项目目录结构
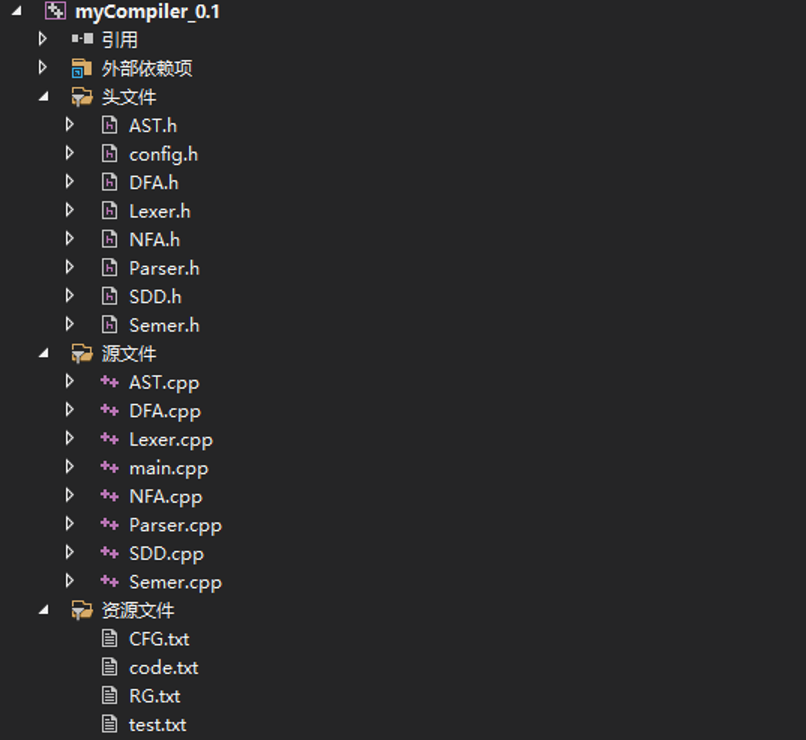
config.h - 程序参数配置文件
NFA.h/NFA.cpp - 定义NFA数据结构及函数的类
DFA.h/DFA.cpp - 定义DFA数据结构及函数的类
SDD.h/SDD.cpp - 定义SDD数据结构及函数的类
AST.h/AST.cpp - 定义AST数据结构及函数的类
Lexer.h/Lexer.cpp - 词法分析器类
Parser.h/Parser.cpp - 语法分析器类
Semer.h/Semer.cpp - 语义分析器类
main.cpp - 程序入口
资源文件:
RG.txt - 正则文法文本文档
CFG.txt - 上下文无关文法文本文档
code.txt - 源代码文本文档
类说明
NFA类
**数据结构:**
私有成员变量如下:
set<string> states; // 状态集合
set<char> inputs; // 输入符号集合
map< pair<string, char>, set<string> > trans; // 转换函数
string is = RG_INITIAL_SYM; // 开始状态
set<string> fs; // 接受状态
**函数说明:**
NFA(string path);
构造函数。接受含有正则文法文本的文档地址,构造NFA。
string get_is();
公共函数。返回NFA初始状态。
set<string> get_fs();
公共函数。返回NFA接收状态集合
set<char> get_inputs();
公共函数。返回NFA输入符号集合
set<string> move(set<string> T, char a);
公共函数。输入状态集合T及输入符号a,返回从集合T中的状态经输入a能到达的所有状态
set<string> closure(set<string> T);
公共函数。输入状态集合T,返回T的闭包
void print();
公共函数。打印NFA相关参数
void set_edge(string s0, set<char> i, string s1);
私有函数。建立边:状态s0对于集合i中的每一个输入转换到s1
DFA类
**数据结构**
私有成员变量
set<int> states; // 状态集合
set<char> inputs; // 输入符号集合
map< pair<int, char>, int > trans; // 转换函数
int is = 0; // 开始状态
set<int> fs; // 接受状态
map<int, string> token; // 接受状态token映射
**函数说明**
DFA(NFA* nfa);
构造函数。接受指向NFA的指针,构造DFA
int move(int T, char a);
公共函数。接受参数状态T和输入a,若存在T在输入a下的转换,返回转换后的状态编号;否则返回-1
bool is_fs(int T);
公共函数。接受状态T,若T为接受状态,返回true;否则返回false
string get_token(int T);
公共函数。接受一个终态T,返回终态T代表的token值
void print();
公共函数。打印DFA参数
SDD类
**数据结构**
结构体 ITEM :表示一个项集中的一个项
size_t pid; // 产生式编号
int dot; // 点位置,以产生式体最左端为0起
string peek; // 向前看符号
结构体定义的运算(用于set排序)
bool operator<(const ITEM& it) const noexcept;
bool operator==(const ITEM& it) const noexcept;
私有成员变量
set<string> vt; // 终结符集
set<string> vn; // 非终结符集
map<string, set<string>> first; // first集
vector<vector<string>> prod; // 产生式
vector<set<ITEM>> collection; // LR(1)项集族
map<pair<int, string>, int> trans; // 项集转换函数
map<pair<int, string>, int> action_table; // ACTION表
map<pair<int, string>, int> goto_table; // GOTO表
map<int, vector<string>> rules; // 语义规则
**函数说明:**
SDD(string path);
构造函数。接受包含上下文无关文法文本的文档地址,构造SDD
vector<string> get_pd(int i);
公共函数。返回编号为i的产生式(以第一个产生式为编号0)
vector<string> get_rules(int i);
公共函数。返回编号为i的产生式的语义规则
int ACTION(int i, string t);
公共函数。返回项集i在输入为终结符号t下的ACTION动作
int GOTO(int i, string n);
公共函数。返回项集i在输入为非终结符号n下GOTO的下一个状态
void print();
公共函数。打印SDD参数
void cal_first();
私有函数。计算文法符号的FIRST集合(在构造函数中调用)
void cal_collec();
私有函数。计算给定文法的LR(1)项集族(在构造函数中调用)
void cal_action();
私有函数。计算ACION表(在构造函数中调用)
void cal_goto();
私有函数。计算GOTO表(在构造函数中调用)
void set_rule(int i, string rule);
私有函数。建立编号为i产生式到语义规则的映射
set<ITEM> closure(set<ITEM>& I);
私有函数。计算项集I的closure闭包
set<ITEM> go_to(set<ITEM>& I, string x);
私有函数。计算项集I经输入X转换得到的项集
set<string> get_first(vector<string> v);
私有函数。返回符号串的FIRST符号集合
AST类
**数据结构**
结构体 QUAD :表示一个四元式
string op;
string arg1;
string arg2;
string res;
结构体定义的函数
void print(Semer& semer);
以中间代码的形式打印此四元式
结构体 AST_NODE :表示抽象语法树的一个节点
string val; // 值或代表的文法符号
string addr; // 存储值的地址
string truelb; // 为真时,转向的地址标号
string falselb; // 为假时,转向的地址标号
string nextlb; // 下一个语句的地址标号
vector<QUAD*> code; // 四元式代码序列
map<string, AST_NODE*> children; // 子节点,键为文法符号
私有成员变量
AST_NODE* root; // 抽象语法树根节点
**函数说明**
void set_root(AST_NODE* root);
公共函数。设置根节点
AST_NODE* get_root();
公共函数。返回根节点
void print(AST_NODE* n, int deep = 0);
公共函数。以递归方式打印抽象语法树
Lexer词法分析主类
**数据结构**
结构体 TOKEN :表示一个TOKEN
int line;
string type;
string content;
私有成员变量
char* lexeme_begin = nullptr; // 词素头
char* forward = nullptr; // 当前字符
char* potential_lex = nullptr; // 潜在接受位置
int state = 0; // 当前状态
int line = 1; // 当前行
int res = 1; // 分析结果
vector<TOKEN*> tokens; // token列表
**函数说明**
Lexer(string path, DFA* dfa);
构造函数。接受DFA和包含源代码的文档的地址,构造Lexer并执行词法分析过程
vector<TOKEN*> get_tokens();
公共函数。返回分析后生成的TOKEN序列
int get_res();
公共函数。返回分析结果
void print();
公共函数。打印词法分析结果
Parser语法分析主类
**数据结构**
私有成员变量
stack<int> st; // 状态栈
stack<AST_NODE*> nt; // 节点栈
int res = 0; // 处理结果
**函数说明**
Parser(const vector<TOKEN*>& tokens, SDD& sdd, Semer &semer);
构造函数。接受词法分析器输出的token序列,一个构造好的SDD,语义分析器Semer,构造Parser并进行语法分析
void print();
公共函数。打印语法分析结果
Semer语义分析主类
**数据结构**
私有成员变量
AST* ast; // 带注释的抽象语法树
stack<map<string, SYM*>*> sym_st; // 符号表栈
map<string, string> label_map; // 标号映射表
static int t_num; // 中间变量寄存器计数
static int l_num; // 标号计数
static int i_num; // GOTO地址中间变量计数
**函数说明**
AST* get_ast();
公共函数。返回构造好的AST
AST_NODE* execute(vector<string> pd, vector<string> rules, stack<AST_NODE*>& nt);
公共函数。接受一个产生式,产生式对应的语义规则,以及语法分析维护的节点栈;生成新内部节点并执行对应语义规则,计算节点属性值。返回构造的新节点。
string get_true_label(string instr);
公共函数。返回临时标号指向的最终标号
void print();
公共函数。打印语义分析结果
string get_attr(AST_NODE* node, string attr);
私有函数。返回与节点node相关的名字为attr的属性值
vector<QUAD*> get_code(AST_NODE* node, string node_name);
私有函数。返回与节点node相关的子节点node_name的四元式序列
void set_addr(AST_NODE* node, string right);
私有函数。根据right定义的规则设置节点node的addr属性
void set_true(AST_NODE* node, string right);
私有函数。根据right定义的规则设置节点node的truelb属性
void set_fals(AST_NODE* node, string right);
私有函数。根据right定义的规则设置节点node的falselb属性
void set_next(AST_NODE* node, string right);
私有函数。根据right定义的规则设置节点的nextlb属性
void set_code(AST_NODE* node, string right);
私有函数。根据right定义的规则设置节点的code属性