Step1. Import
首先导入database,解压压缩包,出现dump文件夹。右键选择Import导入下载的数据库
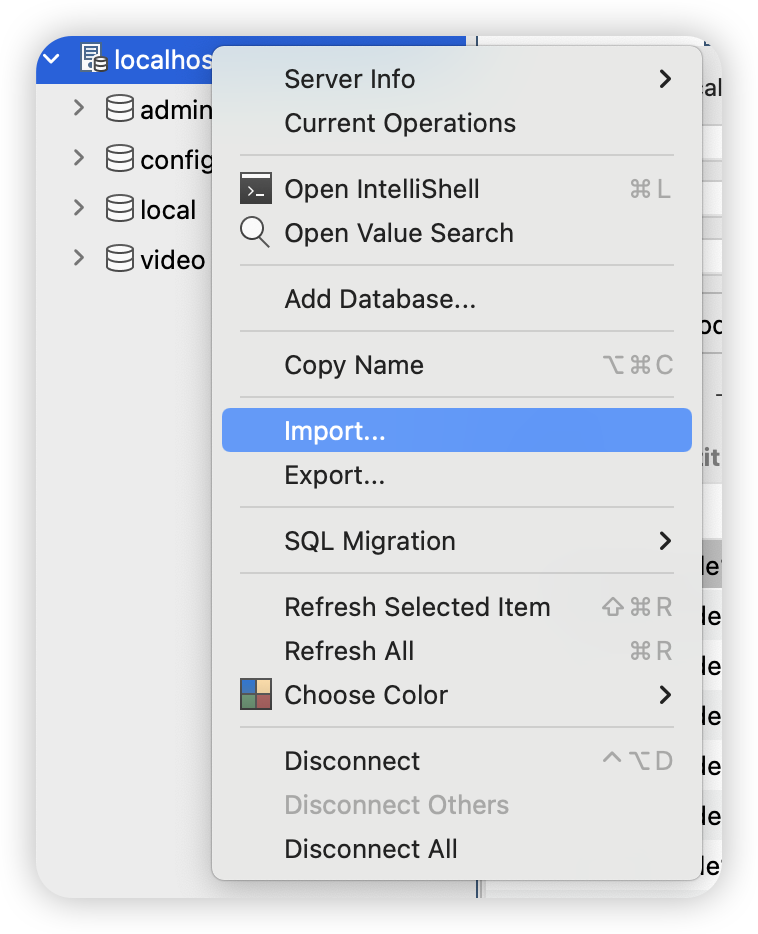
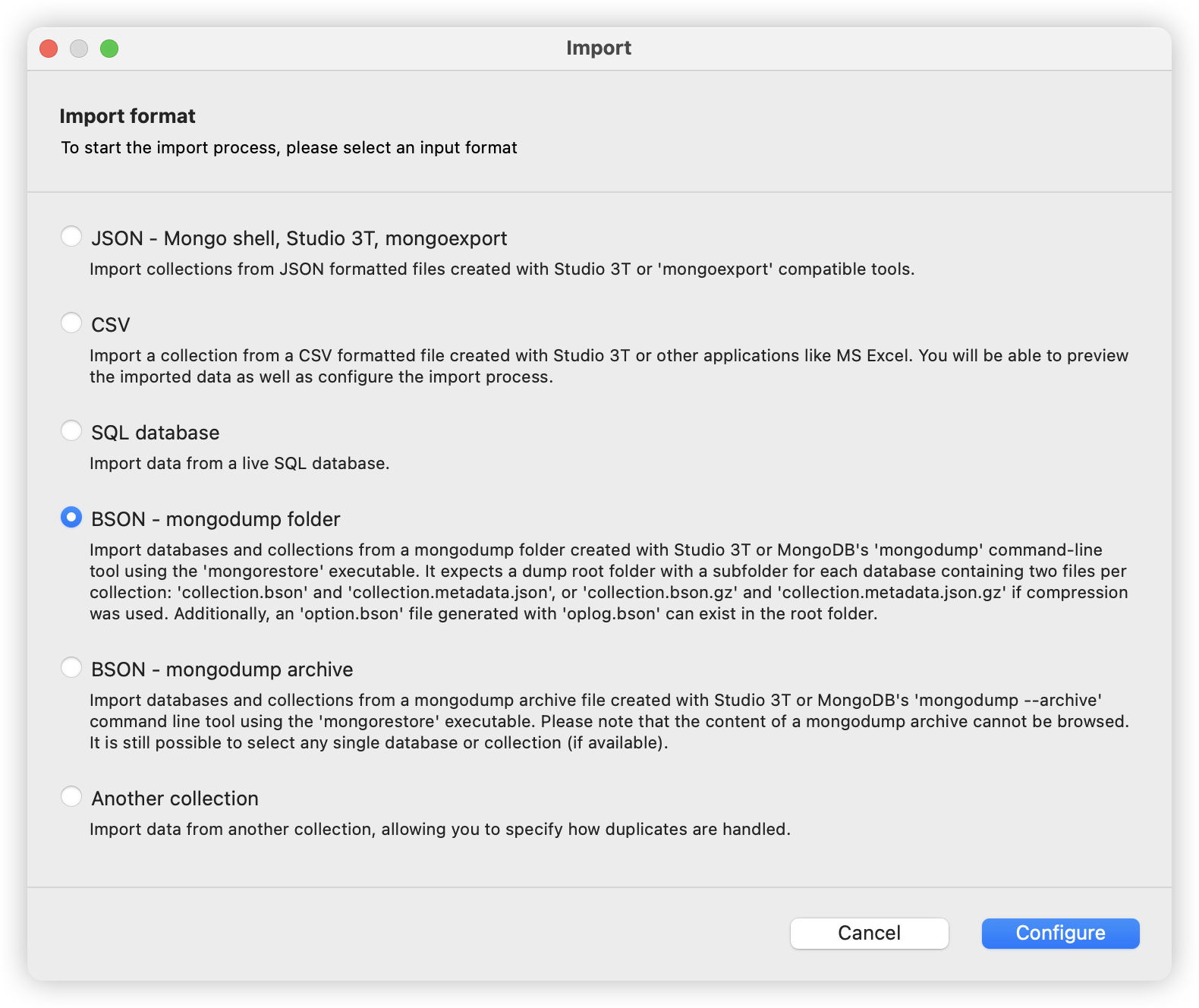
Step2. Query command
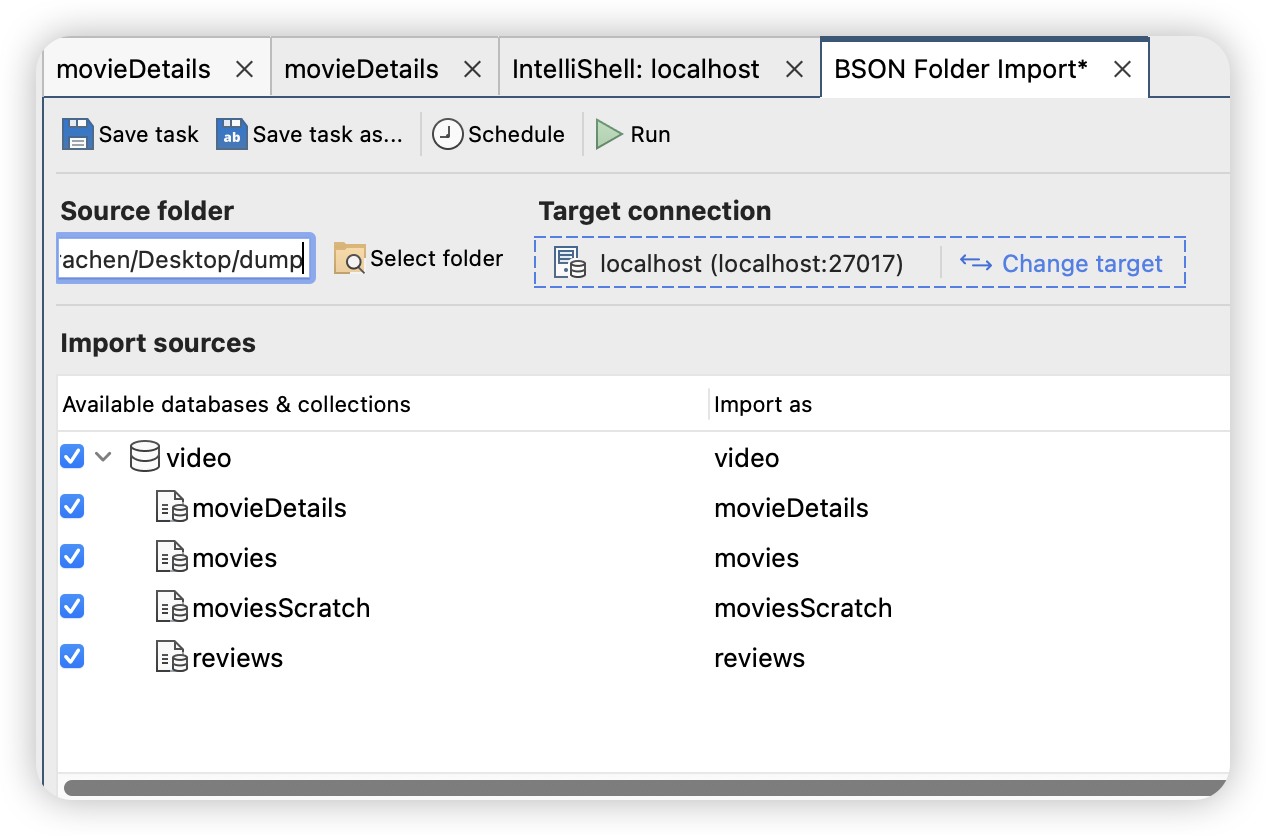
打开后界面如图:
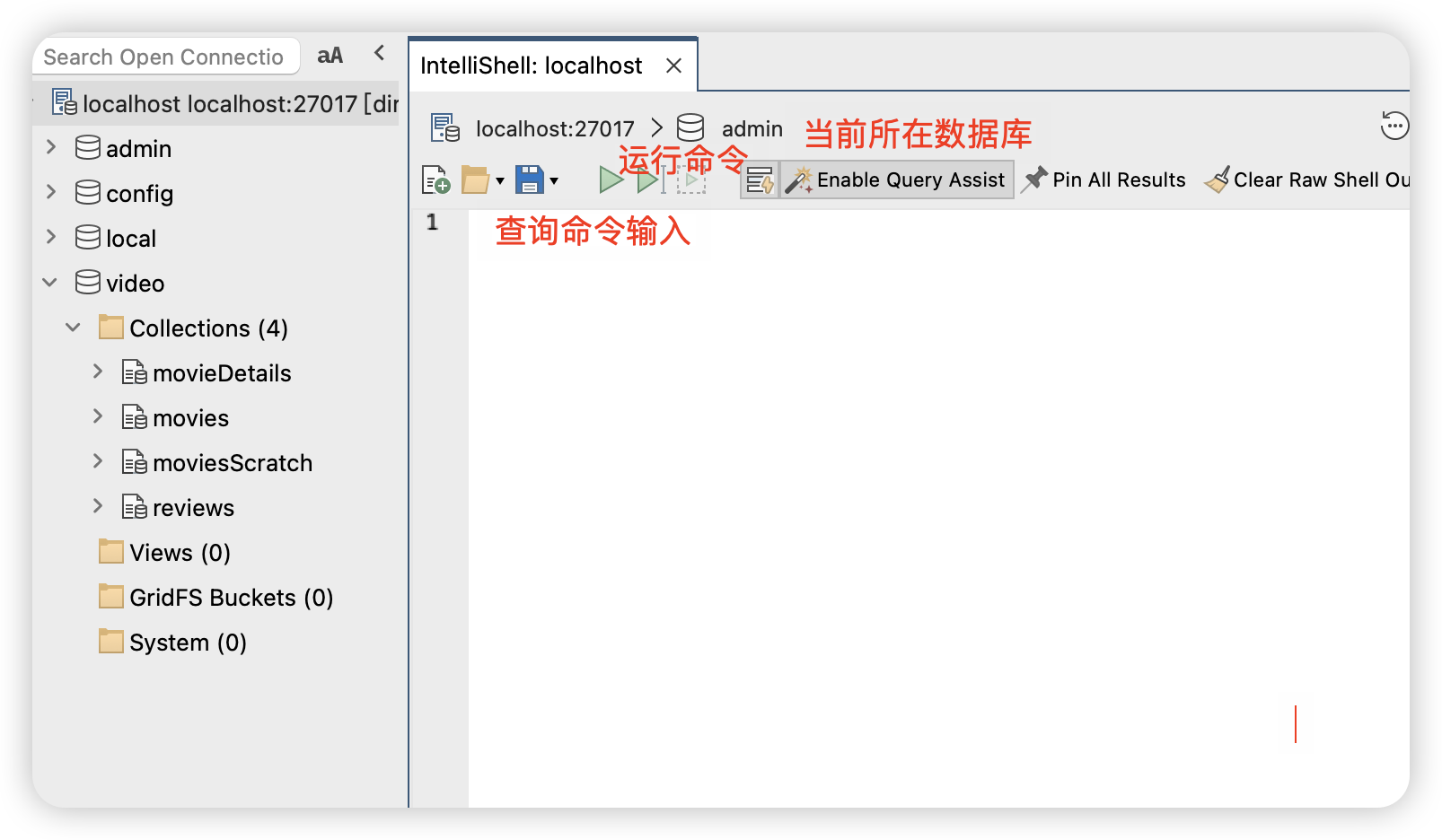
接下来输入命令,每次输入一次就可以点绿箭头运行一句,运行结果在最下面显示。
use video; //该步骤使用use命令选择在哪个数据库操作,默认为admin,导入的是video,进入video
基本命令如下:
use database_name;//如上
show collections;//展示数据库中所有collections
db.createCollection('Collection_name');//该数据库下创建集合
db.getCollection('Collection_name').drop();//删除某集合
db.Collection_name.drop();//同上
db.Collection_name.insert({'id':1,'name':'Tom','age':13});//在某集合中插入数据
db.getCollection("Collection_name").find({});//展示某集合所有documents
db.getCollection("Collection_name").find({});//展示某集合所有documents
Step3. Questions
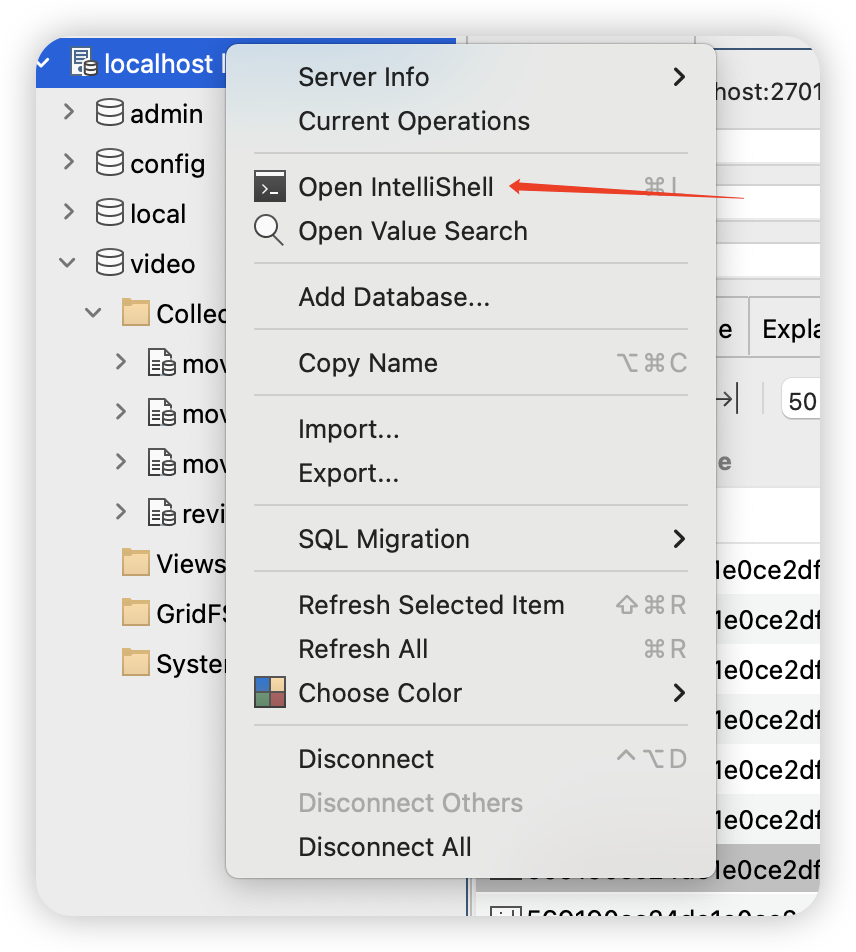
Q1~Q3需要用到Xpath查询,vs中shift+control+option+x
也可以搜索:shift+cmd+p 输入evaluate Xpath
也可以点击 view-command palette-输入evaluate Xpath
记得每次输入完进行terminal里面jps重置
基本操作符 (1)
实例 (1)
轴 (1)
**基本操作**
/channel/xxxx/xxxx 表示逐层进入
//xxxx 表示所有具有xxxx的层
count(/xxx/sample) 计算sample层数量
//page[1]/id 取得第一个page层的id
//page[last()]/revision[last()]/id 取最后page的最
后一个revision的id
用position()<11 可以输出前10个
轴的用法:
比如要获取revision中text bytes=33193的id
//revision[text[@bytes=’33193’]]/id
//revision/text[@bytes=’33193’]/preceding-sibling::id[1] id是text的同级节点
//revision/text[@bytes=”33193”]/parent::revision/id 得到text的父节点revision 然后找这个revision的id
找到title内容为xxxx的title
//title[text()=’xxxx’] 使用text()方法获取内容
找title内容不为xxxx的page
//page[title[not(text()=’xxxx’)]]
找revision里面的contributor下有ip属性的(没有usermname属性的)
//revision[contributor/ip]
//revision[not(contributor/username)]
找除了titile为xxxx的page中revision的text里面字体加粗的 ‘’’为加粗
//page[not(title[text()=’xxxx’])]/revision/text[contains(text(),”’’’”)] 这里获得的是revision
//page[not(title[text()=’xxxx’]) and revision/text[contains(text(),”’’’”)]] 对page进行修饰 得到page
找page里面revision text超过2804bytes的
//page[revision/text[number(@bytes)>2804]]
需要把bytes转换成字符串
比较同级元素的text
/rss/channel/item[description[text()!=preceding-sibling::title/text()]]
比较同级不同元素的属性
/pa[a/attribute::data1=b/attribute::data3]
通配符:
"*"表示匹配任何元素节点。
"@*"表示匹配任何属性值。
node()表示匹配任何类型的节点。
https://www.ruanyifeng.com/blog/2009/07/xpath_path_expressions.html
Q1. How many podcasts have files larger than 5MB? File sizes are stored as “lengths” and are recorded in bytes. There are 1048576 bytes in one MB.
//item[enclosure[number(@length)>5*1048576]]
题目问文件大小大于5MB的item数量,每MB是1048576bytes。这个属性是在item下的enclosure中的length属性,获取得到转换成number 判断下大于。最后用count(//item[enclosure[number(@length)>5*1048576]])计算一下就行
175
Q2. /rss/channel/item[contains(itunes:keywords, “stocks”) and
enclosure/@type=“audio/mpeg”]/media:content/@url
Consider the XPath query given above. What type of nodes will it return?
就是找item中itunes:keywords节点含有“stocks”字串 并且 enclosure节点中属性type为”audio/mpeg”的,得到一个满足条件的item集合,然后获取这个item集合中的media:content节点中的@url属性。会最后就是得到@url属性节点
@url
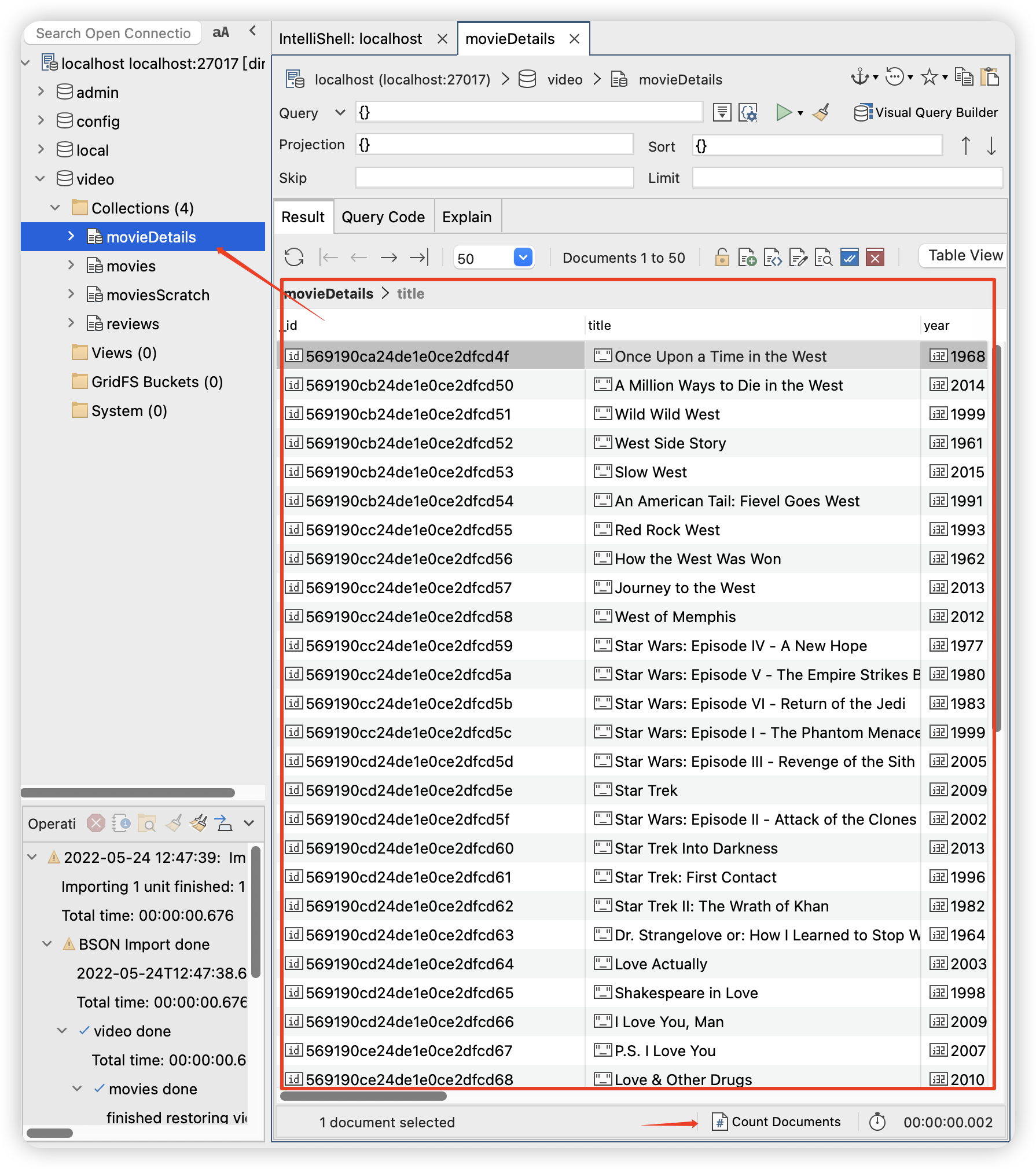
Q4.How many documents in the movieDetails collection have an _id field?
此类题目问多少个documents有_id字段,实际上mongodb中每个集合都一定有_id字段,这个问题就是问movieDetails这个集合有多少documents。两种方法:
方法一
直接在界面看。双击movieDetails的集合,出现所有documents。下面有个Count Documents,点一下,会显示有2,295 documents,为答案。
方法二
命令查询。运行db.collection.count()命令,输出会看到有2295的输出字样。
💡 官方解释:The db.collection.count() method is a shell wrapper that returns the count of documents that would match a find()query; i.e., db.collection.count()method is equivalent to:
db.movieDetails.count();//执行命令
2295
Q5. A RomCom is a movie that has both “Romance” and “Comedy” genres. The movie may also have other genres. How many movies are RomComs?
该问题需要在movieDetails集合中对每个电影查询他的genres字段是否同时包含“Romance”和“Comedy”两个元素,如果包含那它就是RomCom,计算一下这个数量就可以了。
查询命令如下:
db.movieDetails.find({
genres:{
$all:["Romance","Comedy"]
}
});
db.movieDetails.find({
$or:[
{
genres:{
$all:["Romance","Comedy"]
}
},
{
genres:{
$all:["Drama","Comedy"]
}
}
]
});
131
Q6. How many movies have no writers and no plot?
该题目需要查询movieDetails表中没有writers字段(该题中一定存在)或者writers字段为空 并且 没有plot字段(该题中一定存在)或者plot字段为空的documents,查询方法如下:
db.movieDetails.find({
$and:[
{writers:{"$size":0}},
{plot:null}
]
},{ writers: 1, plot: 1})
304
Q7. Of the movies which have a release date, how many were released between 1st June 2010 3pm (inclusive) and 1st December 2013 3pm (inclusive)?
这个题是首先要求了UTC格式的时间,默认只要没改就是UTC。
该题需要用到时间格式 来判断release date在1st June 2010 3pm 和 1st December 2013 3pm之间(均包含),查询方法如下:
db.movieDetails.find({
released:{
$gte:ISODate("2010-06-01T15:00:00.000Z"),
$lte:ISODate("2013-12-01T15:00:00.000Z")
}
})
$gt $gte $lt $lte $ne $eq分别为大于、大于等于、小于、小于等于、不等于、等于
333
Q8. How many movies have plot descriptions with more than one sentence? Assume a sentence always begins with an alphabetic character and ends in a single full stop. Sentences are separated (delimited) by spaces.
此题需要找到plot中有多个句子的documents。其实就是找句号.的数量(需要人工剔除A.A J.J类似人名的,还有省略号这种…)
db.movieDetails.find({
plot:{$regex: /(.*\..*){2,}/, $options: '1' }
},{plot:1})
实际上此时得到782个,但是问题是有人名J.J. 还有省略号… 这种,不知道怎么算,有歧义。
Q9. Find all movies which satisfy all the criteria below; sort them by release year ascendingly, then by title alphabetically. Enter the title of the last movie returned.
Criteria:
• The movie rating on both IMDB and Rotten Tomatoes is over 5.0
• Has not won any awards.
首先需要找到满足要求的电影,要求为:
- IMDB字段和Rotten Tomatoes字段中rating的值 大于5.0
- 没有获得任何奖项,即是说award字段中的wins为0
然后排序,要求首先按年份递增,然后根据标题的字母顺序。最后得到最后一部movie的名字。查询语句如下:
db.movieDetails.find({
'imdb.rating':{$gt:5.0},
'tomato.rating':{$gt:5.0},
'awards.wins':0
}).sort({released:1},{title:1})
Woman in Gold
Q10. Find the movie which is a documentary (and has no other genres) with the shortest run time.
Enter the title of this movie.
找最短的纪录片(不能有其他类型),就是先过滤出只为纪录片的movie,然后按时间升序排,第一个就是了。
db.movieDetails.find({
genres:["Documentary"],
runtime:{$ne:null}
},{genres:1,runtime:1,title:1}).sort({runtime:1})
CF: Two Little Letters
Q11. Write a MongoDB find query to retrieve the IMDB details, Rotten Tomatoes details, and Metacritic rating for all movies which have a higher rating on Rotten Tomatoes than on IMDB. Order the results by their IMDB id ascendingly.
Format your query neatly.
写查询语句,要列出Tomato的rating大于IMDBrating的所有电影的IMDB、Tomato、Metacritic信息,并且按IMDB的id 升序排列,语句书写如下:
db.movieDetails.find({
$expr:{$gt:["$tomato.rating","$imdb.rating"]}
},{imdb:1,tomato:1,metacritic:1}).sort({"imdb.id":1})
Q12. Write the steps necessary to convert the URLs in the file raw.json (download from Canvas)into a plaintext list. The output format should be plaintext with one URL per line. E.g.
/path/path?query=value
Assume URLs can contain commas and quotation marks (double quotes)
根据要求,首先提取[]中括号内的内容:
find:\[(.*)\]
replace:$1
然后,去除所有引号
find:"
replace:
find:"([^"]*)"
replace:$1
最后,将逗号替换成换行符
find:,
replace:\n
find:([^,]*),
replace:$1/n
Q13. The file url.txt (download from Canvas) contains one URL per line in plaintext. Some URLs have query parameters used for tracking user clicks. There are two types of parameters: referral parameters, and UTM parameters
该题目需要将url中的参数给去除。参数一定是&或者?开头,然后跟一个ref=或者utm_xxxxx=,其中xxxxx有5种,utm_source, utm_medium, utm_campaign, utm_item, utm_content 然后等于号后面的内容也需要删掉。
因此正则匹配如下:
find:(\?|&)(ref|(utm_(source|medium|campaign|item|content)))=([^&?\n]*)
replace:
steps:
- 用vs code打开原始数据url.txt,并且使用regex
- find:
(\?|&)(ref|(utm_(source|medium|campaign|item|content)))=([^&?\n]*)
replace:
第一个括号匹配问号或者&符号,然后第二个括号匹配ref或者utm_type,其中type有5种,分别为source、medium、campaign、item和content。此后紧跟一个等号,然后等号后面的第三个括号匹配一个非& 非? 非换行符的0或以上长度的字符串 - 进行替换,替换内容为空,则可删除
2020 Test
Q1.RNZ - All Programmes的channel,找到有August 的title的item数量
/rss/channel/title[text()='RNZ - All Programmes']/parent::channel/item[contains(title,"August")]
63
Q2.多少item在Monday上映并且持续时间不在50:00到50:59之间
count(/rss/channel/item[contains(pubDate,"Mon") and (number(substring(itunes:duration,1,2))*3600+number(substring(itunes:duration,4,2))*60+number(substring(itunes:duration,7,2)))>3059])
count(/rss/channel/item[contains(pubDate,"Mon") and (number(substring(itunes:duration,1,2))*3600+number(substring(itunes:duration,4,2))*60+number(substring(itunes:duration,7,2)))<3000])
117
Q3.有一个item他的enclosure的url和mediacontent的url不一样 找出来,找到他的guid前八位
/rss/channel/item[enclosure/attribute::url!=media:content/attribute::url]/guid
856c1b45-1e0b-4abc-b058-0a0a9061056f(前8字符就是856c1b45)
Q4. movie中有_id field 的documents数量
直接查看:3,365
Q5.根据award.text,有多少部电影获4部奥斯卡
db.movieDetails.find({
'awards.text':{
$regex : ".*Won 4 Oscar*"
}
});
7
Q6. 既没有award wins又没有nominations,或者有超过8个wins并且少于16个提名的电影数量
db.movieDetails.find({
$or:[
{
'awards.wins':0,
'awards.nominations':0
},
{
'awards.wins':{$gt:8},
'awards.nominations':{$lt:16}
}
]
});
1497
Q7. 多少电影没有writers和poster
db.movieDetails.find({
writers:{"$size":0},
poster:null
});
410
Q8. 有多少电影不是“R” rated
db.movieDetails.find({
rated:{$ne:"R"}
});
2081
Q9. 找第一个导演中firstname是5个字符的电影数量
db.movieDetails.find({
director:{$regex:/^([A-Za-z]{5})\s/}
});
461
Q10. 找runtime最长的并且制造公司同时有UK和Italy
db.movieDetails.find({
countries:{
"$all":["UK","Italy"]
}
}).sort({runtime:-1})
The Adventures of Baron Munchausen
Q11. 解释代码意思
从movieDetails集合中找到有4个actors和4个writers并且没有director的电影title,并且首先根据第三writer的名字进行升序排序(alphabetically),如果名字相同,则按第二actor的名字降序排序。
Q12.
csv:
MovieID, Oscar Wins, General Wins, General Nominations
1,3,7,5
10,3,7,5
101,10,18,11
1001,3,7,5
1002,1,7,5
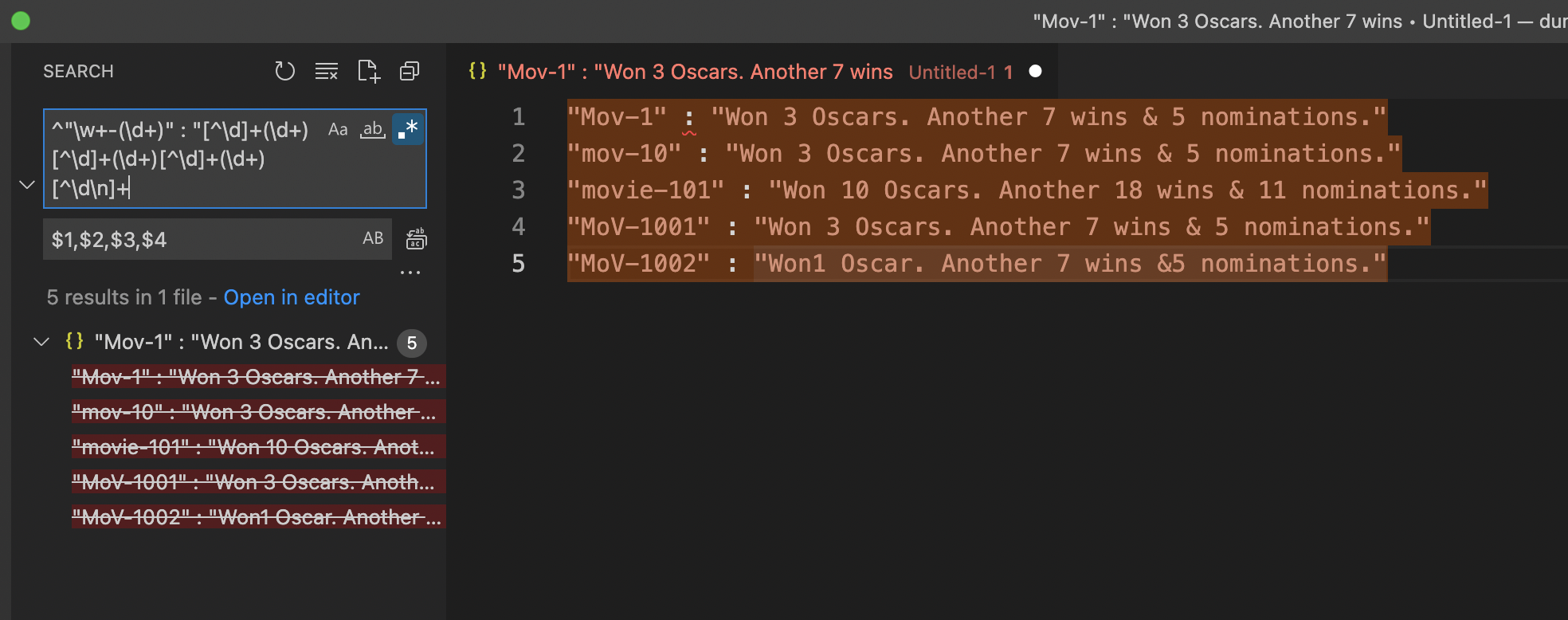

步骤:
- 在vs code中打开源文件
- 打开查找,输入regex表达式
^[^\d]+(\d+)[^\d]+[^\d]+(\d+)[^\d]+(\d+)[^\d]+(\d+)[^\d\n]+,查找并替换为$1,$2,$3,$4,得到数字结果
其中四个(\d+)分别匹配MovieID, Oscar Wins, General Wins, General Nominations的数字,并将其分组为$1-$4。其他[^\d]+匹配所有非数字字符,注意最后的[^\d\n]要求不能匹配换行符。 - 将表头插入到结果的第一行
Q13.
Find: ([a-z]+)(\d+)
Replace: $2$1
找到字符串在数字串前面的字串,分别给字符串和数字串分组为$1和$2,交换$1和$2位置。