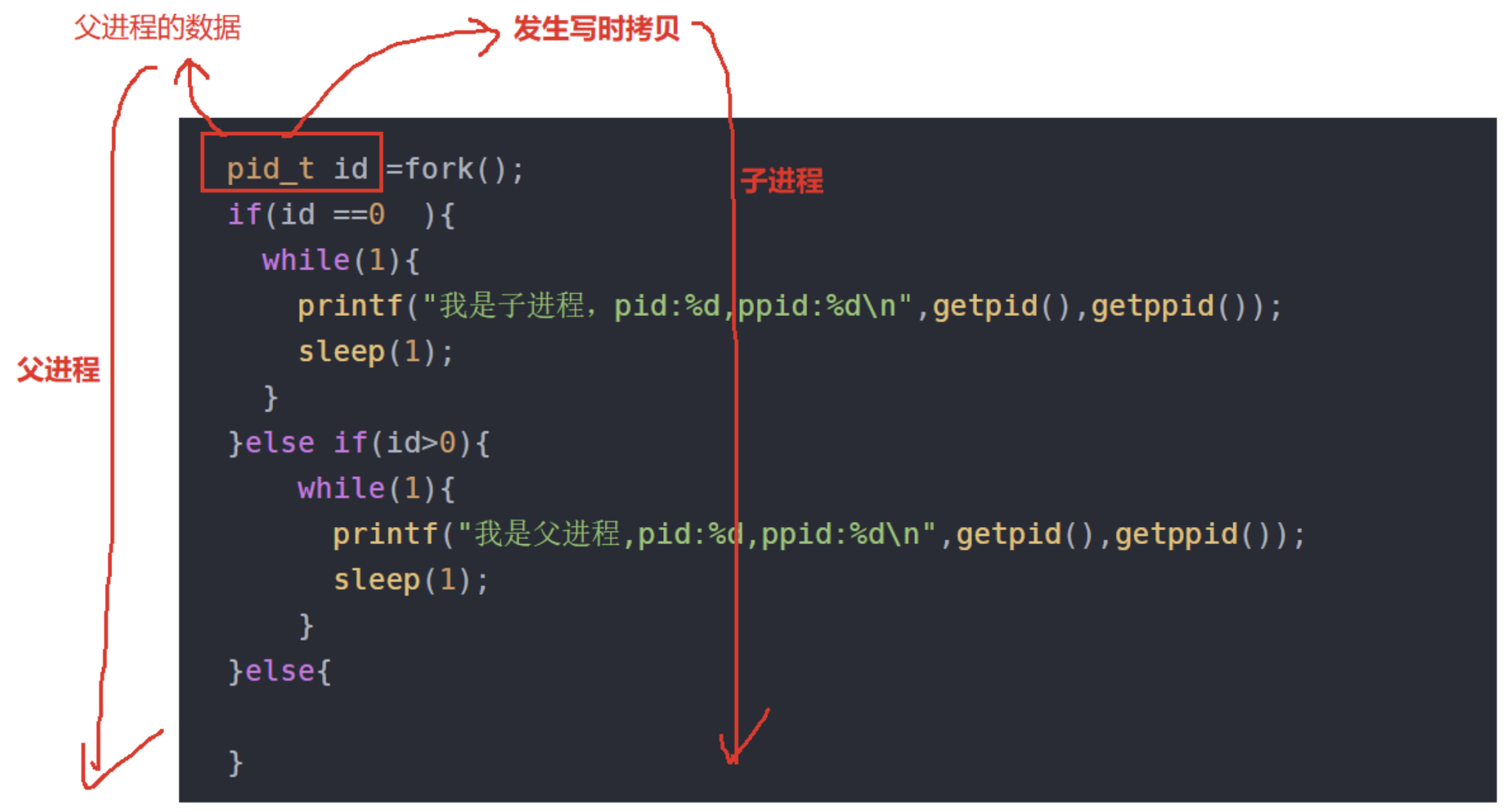
fork()函数功能
fork函数的作用是创建一个新的进程该函数通过系统调用在当前进程的地址空间中复制一份子进程,子进程几乎与父进程完全相同,包括进程代码、数据、堆栈以及打开的文件描述符
也就是主进程和fork()出的两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
fork函数有两个返回值:
在父进程中,fork返回子进程的ID;
在子进程中,fork返回0;
如果出现错误,fork返回一个负值;
fork()函数干了什么?
linux中对OS对进程的管理是通过进程控制块(PCB)实现的。进程=内部数据结构+代码和数据
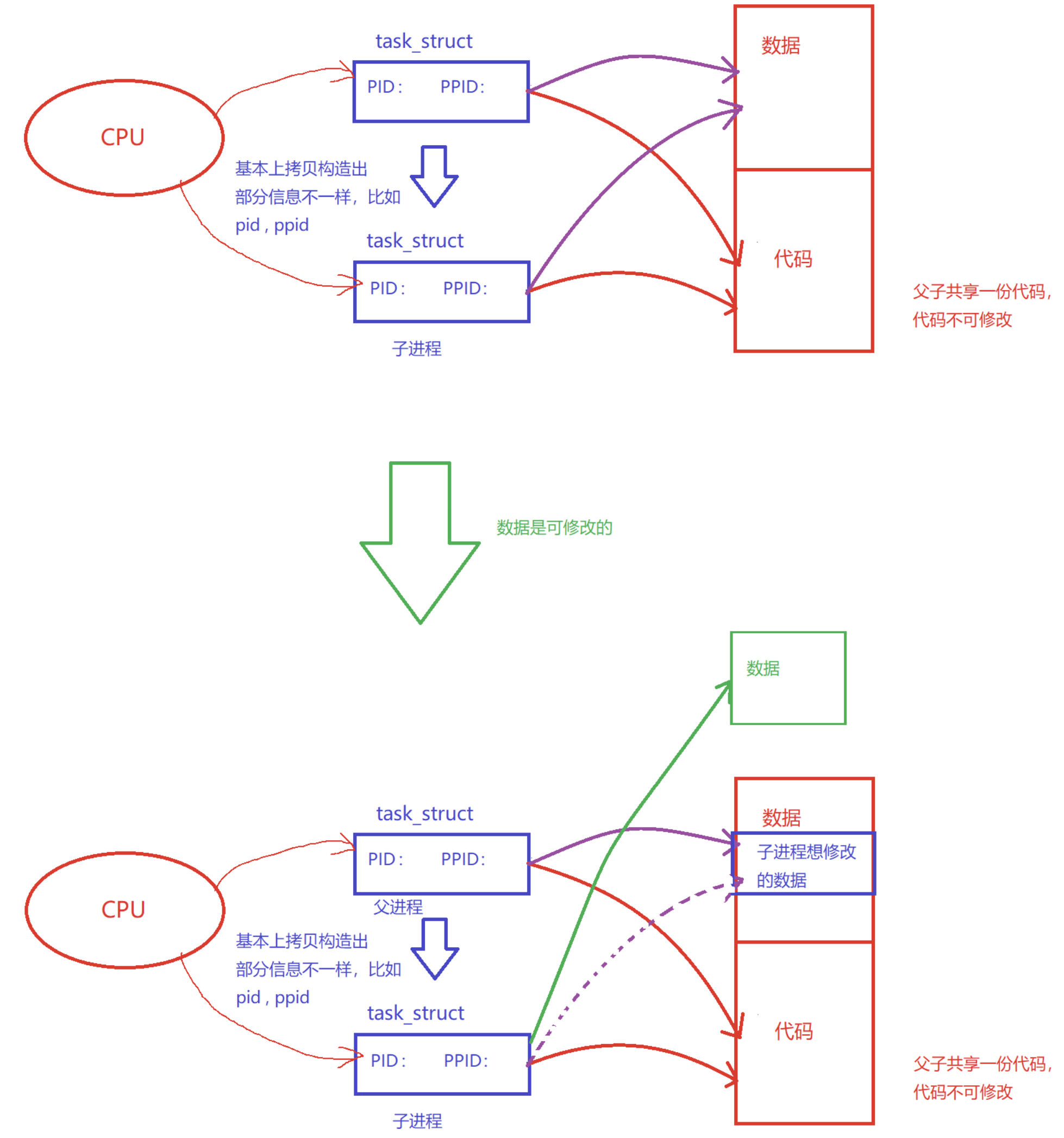
fork函数先几乎复制一份父进程的task_struct,并指向同一块内存空间,创建一个了与原来进程几乎完全一致的子进程。
因为代码是不可以修改的,而数据是可以修改的,所以一般父子进程不享用同一块数据
当子进程想修改父进程中的数据时,系统会单独分配一块空间存储子进程的数据。
但如果子进程不修改父进程的数据,就不用拷贝父进程的数据并开空间,这种方法叫做写时拷贝。
为什么fork()函数有两个返回?为什么可以返回两次?
fork函数的返回值给子进程返回0,给父进程返回子进程的pid
因为调用fork函数之后的代码父子共享,返回不同的返回值,是为了区分不同的执行流,执行不同的代码块。
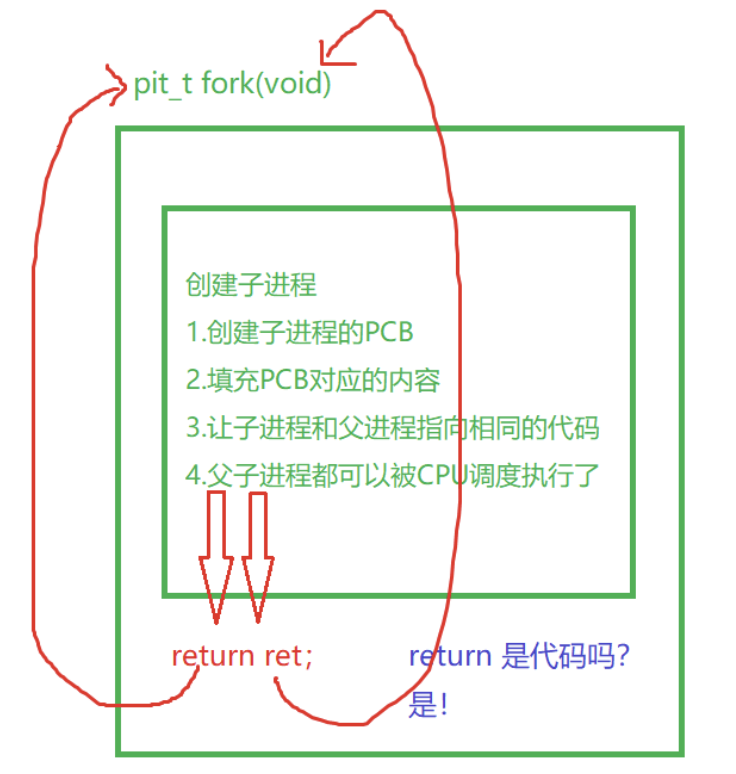
返回两次是因为创建了两个进程,每个进程都返回了一次。
也就是对于不同的进程来说一个变量会有不同的内容: