2. 复制模型
平常的开发中,其实很少说一上来就直接搞主从架构的。费时间、费钱还引入了额外的复杂度,最后发现投入了这么多一个单MySQL服务器就完全能handle。
这就跟一个产品的架构迭代是一样的,刚刚起步的时候一个单体应用足够了。当你的业务扩展,请求膨胀,单体无法抗住压力了,就会考虑开始部署多实例,开始采用微服务架构去做横向扩展、负载均衡。
2.1 一主多从
当然你也可以把它当成一主一从。
这是最简单的模型,特别适合少量写、大量读的情况。读请求被分到了各个从库上,有效的帮主库分散了压力,能够提升读并发。当然,你也可以只是把从库当成一个灾备库,除了主从复制之外,没有其他任何的请求和数据传输。
甚至你可以把其中一个备库作为你的预发环境的数据库,当然,这说到底还是直接动了生产环境的数据库,是一种过于理想的用途,因为这还涉及到生产环境数据库的数据敏感性。不是所有人都能够接触到的,需要有完善的权限机制。

MySQL一主多从
值得注意的是,如果有n个从库,那么主库上就会有n个binlog dump线程。如果这个n比较大的话在复制的时候可能会造成主库的性能抖动。所以在从库较多的情况下可以采用级联复制。
2.2 级联复制
级联复制用大白话说就是套娃。
本来从库B、C、D、E、F、G都是复制的主库A,但是现在由于A的压力比较大,就不这么干了,调整成了如下的模式。
- B、C复制A
- D、E复制B
- F、G复制C
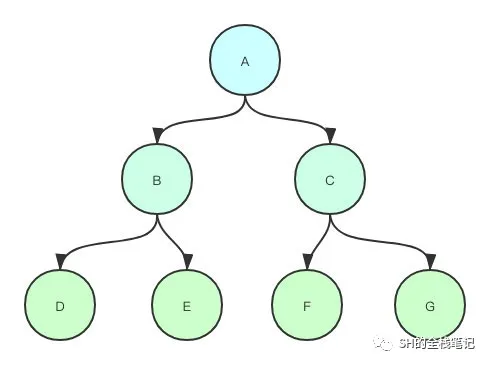
MySQL级联复制
这就叫级联复制,开启疯狂套娃模式。你甚至会觉得这种套娃很眼熟,在Redis主从复制中也可以采用级联模式, slave去复制另一个slave。
级联复制的好处在于很大程度上减轻了主库的压力,主库只需要关心与其有直接复制关系的从库,剩下的复制则交给从库即可。相反,由于是这种层层嵌套的关系,如果在较上层出现了错误,会影响到挂在该服务器下的所有子库,这些错误的影响效果被放大了。
2.3 主主复制
顾名思义,就是两个主库相互复制,客户端可以对任意一台主库进行写操作。任何一台主库服务器上的数据发生了变化都会同步到另一台服务器上去。有点类似于Eureka Server的双节点模式,两个注册中心相互注册。这样一来,任何一台挂了都不会对系统产生影响。
而且主主复制可以打破数据库性能瓶颈,一个很酷的功能——横向扩展。为什么说很酷呢,如果DB能做到横向扩展,那很多被数据库并发所限制的瓶颈都可以被突破,然而…
但是主主复制其实并不可靠,两边的数据冲突的可能性很大。例如复制停止了,系统仍然在向两个主库中写入数据,也就是说一部分数据在A,另一部分的数据在B,但是没有相互复制,且数据也不同步了。要修复这部分数据的难度就会变得相当大。
所以我认为双主的更多的意义在于HA,而不是负载均衡。
2.4 主、被动的主主复制
同样还是双主的结构,但是区别在于其中一台是只读的被动服务器,客户端不会向该库进行写操作。
其用途在哪里呢?例如我们要在不中断服务的前提下对MySQL进行维护、优化,举个例子——修改表结构。假设我们有两个数据库,主库A和被动主库B,注意此处的被动主库是只读的,我们先停止A对B的复制,也就是停掉A上的SQL线程。
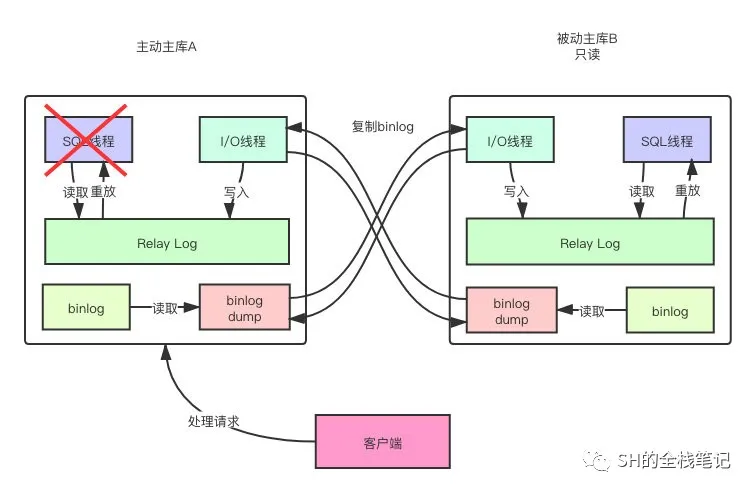
主主停止复制
这样一来,我们之后在B上执行的非常耗时、可能需要锁表的操作就不会立即同步到A上来。因为此时A正在对外提供服务,所以不能使其收到影响,但是由于采用的是异步的复制模式,所以Relay Log还是继续由I/O线程写入,只是不去进行重放。
然后我们在B上执行此次的维护操作,注意,此时A上面发生的更新还是会正常的同步到B来。执行完后交换读写的角色。也就是让A变成只读的被动主库,而B变为主动主库对外提供服务。
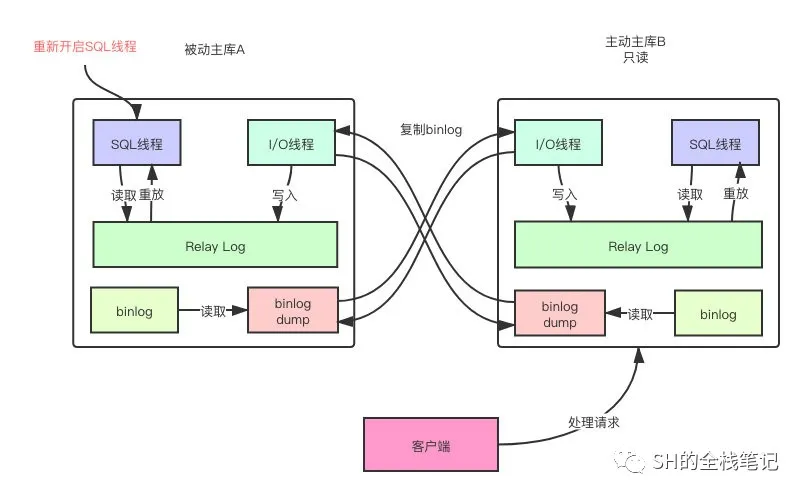
重新开启SQL线程
然后重新开启SQL线程,A开始去对之前Relay Log中积累的event进行重放。虽然A此时可能会阻塞住,但是A已经没有对外提供服务了,所以没有问题。
主、被动下的主主模式的好处大家也就清楚了,可以在不停止服务的情况下去做数据库的结构更新,其次可以在主库发生故障的情况下,快速的切换,保证数据库的HA。
3. 复制方式
上文我们不止一次的提到了复制是异步的,接下来我们来了解一下MySQL的主从复制都有哪些方式。
3.1 异步复制
首先就是异步,这也是MySQL默认的方式。在异步复制下,主库不会主动的向从库发送消息,而是等待从库的I/O线程建立连接,然后主库创建binlog dump线程,把binlog event发送给I/O线程,流程如下图。
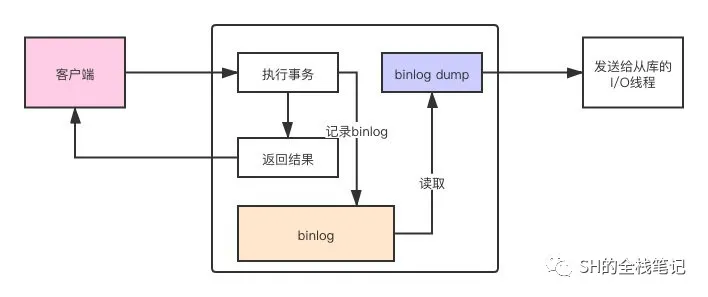
MySQL复制模式
主库在执行完自己的事务、记录完binlog之后就会直接返回,不会与客户端确认任何结果。然后后续由binlog dump线程异步的读取binlog,然后发送给从库。处理请求和主从复制是两个完全异步化的过程。
3.2 同步复制
同步模式则是,主库执行一个事务,那么主库必须等待所有的从库全部执行完事务返回commit之后才能给客户端返回成功,
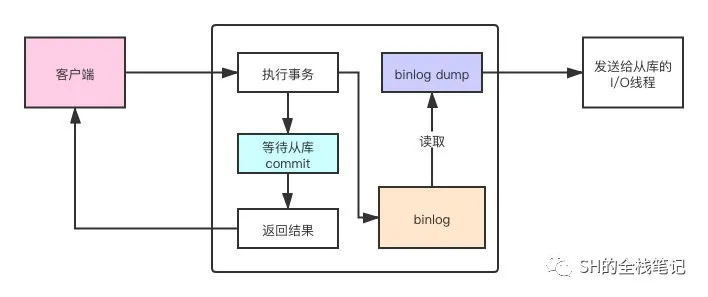
同步复制
值得注意的是,主库会直接提交事务,而不是等待所有从库返回之后再提交。MySQL只是延迟了对客户端的返回,并没有延后事务的提交。
同步模式用脚趾头想知道性能会大打折扣,它把客户端的请求和主从复制耦合在了一起,如果有某个从库复制线程执行的慢,那么对客户端的响应也会慢很多。
3.3 半同步复制
半同步相对于同步的区别在于,同步需要等待所有的从库commit,而半同步只需要一个从库commit就可以返回了。如果超过默认的时间仍然没有从库commit,就会切换为异步模式再提交。客户端也不会一直去等待了。
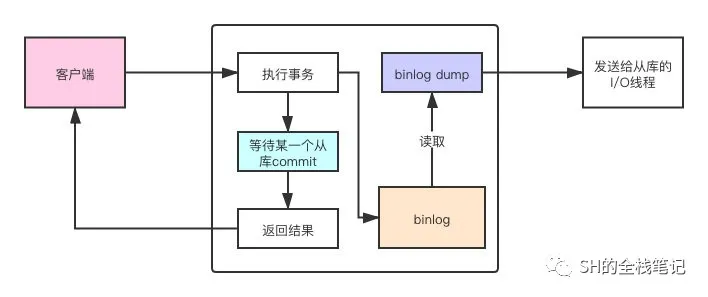
MySQL复制模式
因为即使后面主库宕机了,也能至少保证有一个从库节点是可以用的,此外还减少了同步时的等待时间。
4. 复制中的数据一致性
我们在1.3中讨论了复制的核心步骤,看似很简单的一个流程,主库的binlog dump去读取binlog,然后从库的I/O线程去读取、写入Relay Log,进而从库的SQL线程再读取Relay Log进行重放。
那如果I/O线程复制到一半自己突然挂掉了呢?又或者复制到一半主库宕机了呢?如果和保证数据一致性的呢?
我们上面提到过,有一个relay-log.info的文件,用于记录当前从库正在复制的binlog和写入的Relay Log的Pos,只要这个文件还在,那么当从库意外重启之后,就会重新读取文件,从上次复制的地方开始继续复制。这就跟Redis中的主从复制类似,双方要维护一个offset,通过对比offset,来进行psync增量数据同步。
但是在MySQL 5.5以及之前,都只能将复制的进度记录在relog-log.info文件中。换句话说,参数relay_log_info_repository只支持FILE,可以再回到上面的1.5 Relay Log核心参数看一下。所以只有在sync_relay_log_info次事务之后才会把relay-log.info文件刷入磁盘。
如果在刷入磁盘之前从库挂了,那么重启之后就会发现SQL线程实际执行到位置和数据库记录的不一致,数据一致性的问题就这么产生了。
所以在MySQL 5.6时,参数relay_log_info_repository支持了TABLE,这样一来我们就可以将复制的进度放在系统的mysql.slave_relay_log_info表里去,并且把更新进度、SQL线程执行用户事务绑定成一个事务执行。即使slave宕机了,我们也可以通过MySQL内建的崩溃恢复机制来使实际执行的位置和数据库保存的进度恢复到一致。
其次还有上面提到的半同步复制,主库会先提交事务,然后等待从库的返回,再将结果返回给客户端,但是如果在主库等待的时候,从库挂了呢?
此时主库上由于事务已经提交了,但是从库上却没有这个数据。所以在MySQL 5.7时引入了无损半同步复制,增加了参数rpl_semi_sync_master_wait_point的值,在MySQL 5.7中值默认为after_sync,在MySQL 5.6中默认值为after_commit。
- after_sync 主库先不提交事务,等待某一个从库返回了结果之后,再提交事务。这样一来,如果从库在没有任何返回的情况下宕机了,master这边也无法提交事务。主从仍然是一致的
- after_commit 与之前讨论的一样,主库先提交事务,等待从库返回结果再通知客户端