CPU统计分析原理
首先要明白,我们究竟要统计的是什么内容?我们需要知道cpu的使用情况,换言之就是cpu的工作时间花在了哪些函数上,最后是不是就是看函数在cpu上的工作时长。
golang的pprof是采用部分采样的方式,通过系统调用(settimmer)设置了发送sigprof的定时器,当达到了周期间隔(runtime.SetCPUProfileRate),操作系统就会给进程发送SIGPROF信号(默认10ms)
发送信号过后cpu的采样就开始了,一旦到达周期间隔10ms,操作系统就会把记录的调用堆栈之类的数据发送给golang golang就会统计当前正在运行的是哪个函数,采样的这段时间内,哪个函数占用cpu时间多
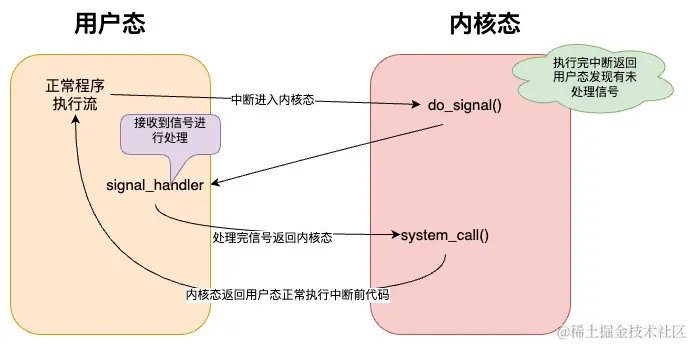
上图表示线程对信号的处理时机,当线程由于系统调用或者中断进入内核态后,系统调用结束或者中断处理完成后,在返回到用户态之前,操作系统会检查这个线程是不是有未处理的信号,如果有的话,那么会先切回到用户态让 线程会首先处理信号,信号处理完毕后 又返回内核态,内核此时才会将调用栈设置为中断或者系统调用时 用户进程中断的地方
内核向进程发信号的方式是对进程中的一个线程发送信号,而通过settimmer 系统调用设置定时器 发送SIGPROF 信号的方式就是随机的对进程中的一个运行中线程去进行发送。
第一,golang用settimmer 设置定时器发送SIGPROF 信号 的方式的确被证实在linux上存在线程选择公平性问题(A线程接收到SIGPROF信号的次数远远大于B 线程接收SIGPROF信号的次数,这样对A线程进行采样的次数将会变多,影响了我们采样的结果)
第二 因为是向一个运行中的线程去发送信号,所以我们只能统计到采样时间段内在cpu上运行的函数,而那些io阻塞的函数将不能被统计到
为了解决公平性问题,golang在settimer的系统调用的基础上增加了timer_create系统调用timer_create 可以单独的为每一个线程都创建定时器,这样每个运行线程都会采样到自己的函数堆栈了
示例计算
假设我们有以下采样数据,每次采样间隔为 10 毫秒:
• 函数 busyWork 在 100 次采样中出现了 70 次。
• 函数 idleWork 在 100 次采样中出现了 30 次。
则 CPU 使用时间可以估算如下:
• busyWork 的 CPU 时间 = 70 次 * 10 毫秒 = 700 毫秒
• idleWork 的 CPU 时间 = 30 次 * 10 毫秒 = 300 毫秒
- 定时器设置:
通过系统调用(如 setitimer)设置一个定时器,每隔 10 毫秒触发一次时钟中断。
- 时钟中断处理:
当定时器到期时,操作系统会触发一个时钟中断,这时 CPU 从用户态切换到内核态,由内核处理这个中断。
- 发送信号:
内核处理完时钟中断后,会向当前运行的进程发送 SIGPROF 信号。
- 信号处理程序:
Go 运行时系统中有一个预先设置好的信号处理程序,当接收到 SIGPROF 信号时,CPU 切换回用户态,Go 运行时的信号处理程序被调用。
- 记录堆栈信息:
Go 运行时的信号处理程序会记录当前的堆栈信息。这个过程通常非常快,完成后,程序继续执行。
-
处理完信号返回内核态:
-
**返回用户态正常执行中断前的代码**
总结
cpu的统计原理与前面所讲的指标统计的原理稍微复杂点,涉及到了linux信号处理相关的内容,cpu统计的原理,简而言之,就是通过设置一个发送SIGPROF信号的定时器,然后用户程序通过接收操作系统定时发送的SIGPROF信号来对用户程序正在执行的堆栈函数进行统计。在采样时间内,同一个函数被统计的越多,说明该函数占用的cpu工作时长就越长。