gin路由树原理
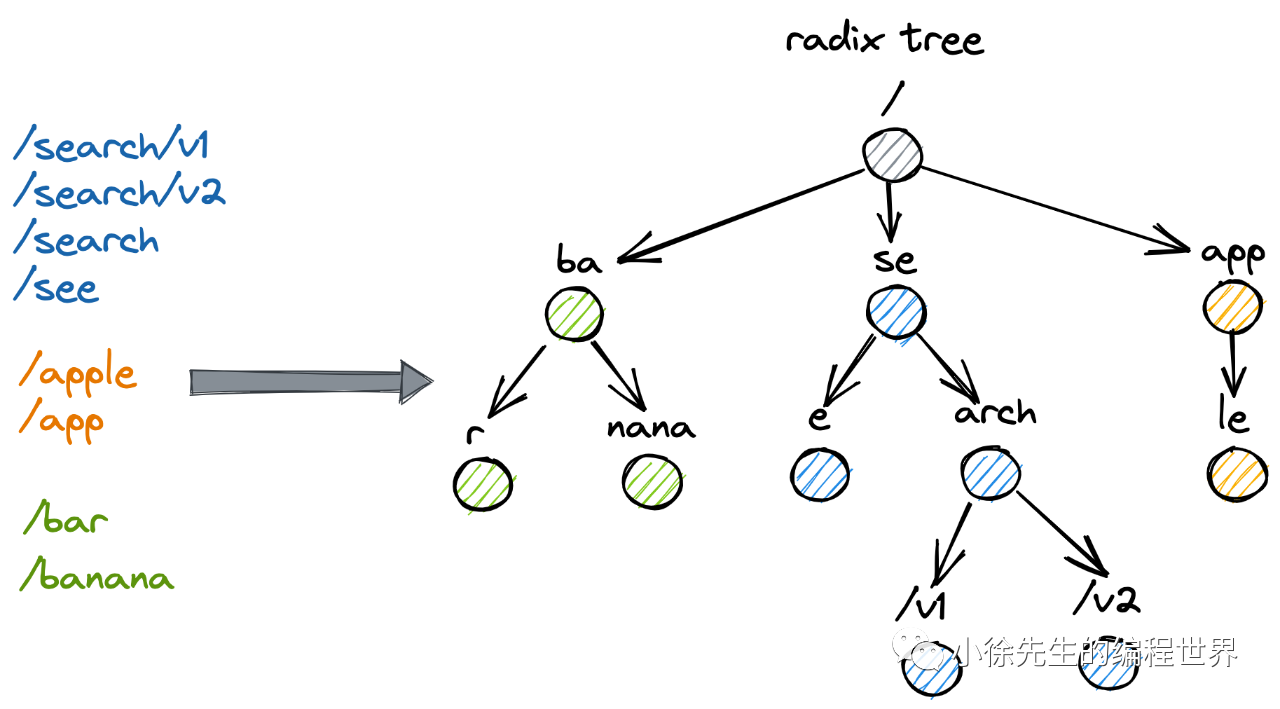
1)前缀树
前缀树又称 trie 树,是一种基于字符串公共前缀构建索引的树状结构,核心点包括:
- 除根节点之外,每个节点对应一个字符
- 从根节点到某一节点,路径上经过的字符串联起来,即为该节点对应的字符串
- 尽可能复用公共前缀,如无必要不分配新的节点
2)压缩前缀树
压缩前缀树又称基数树或 radix 树,是对前缀树的改良版本,优化点主要在于空间的节省,核心策略体现在:倘若某个子节点是其父节点的唯一孩子,同时没有一个单词是以父节点结尾的,则与父节点进行合并
3)为什么使用压缩前缀树
与压缩前缀树相对的就是使用 hashmap,以 path 为 key,handlers 为 value 进行映射关联,这里选择了前者的原因在于:
- path 匹配时不是完全精确匹配,比如末尾 ‘/’ 符号的增减、全匹配符号 ‘*’ 的处理等,map 无法胜任(模糊匹配部分的代码于本文中并未体现,大家可以深入源码中加以佐证)
- 路由的数量相对有限,对应数量级下 map 的性能优势体现不明显O(1)常数可能比较大,在小数据量的前提下,map 性能甚至要弱于前缀树
- path 串通常存在基于分组分类的公共前缀, 适合使用前缀树进行管理,可以节省存储空间
4)补偿策略
在 Gin 路由树中还使用一种补偿策略,在组装路由树时,会将注册路由句柄数量更多的 child node 摆放在 children 数组更靠前的位置.
这是因为某个链路注册的 handlers 句柄数量越多,一次匹配操作所需要花费的时间就越长,且被匹配命中的概率就越大,因此应该被优先处理.
核心数据结构

路由树的数据结构,对应于 9 种 http method,共有 9 棵 methodTree. 每棵 methodTree 会通过 root 指向 radix tree 的根节点.
type methodTree struct {
method string
root *node
}
type node struct {
// 节点的相对路径
path string
// 每个 indice 字符对应一个孩子节点的 path 首字母
indices string
// ...
// 后继节点数量
priority uint32
// 孩子节点列表
children []*node
// 处理函数链
handlers HandlersChain
// path 拼接上前缀后的完整路径
fullPath string
}
node 是 radix tree 中的节点,对应节点含义如下:
- path:节点的相对路径,拼接上 RouterGroup 中的 basePath 作为前缀后才能拿到完整的路由 path
- indices:由各个子节点 path 首字母组成的字符串,子节点顺序会按照途径的路由数量 priority进行排序
- priority:途径本节点的路由数量,反映出本节点在父节点中被检索的优先级
- children:子节点列表
- handlers:当前节点对应的处理函数链
注册到路由树
下述代码展示了将一组 path + handlers 添加到 radix tree 的详细过程
// 插入新路由
func (n *node) addRoute(path string, handlers HandlersChain) {
fullPath := path
// 每有一个新路由经过此节点,priority 都要加 1
n.priority++
// 加入当前节点为 root 且未注册过子节点,则直接插入由并返回
if len(n.path) == 0 && len(n.children) == 0 {
n.insertChild(path, fullPath, handlers)
n.nType = root
return
}
// 外层 for 循环断点
walk:
for {
// 获取 node.path 和待插入路由 path 的最长公共前缀长度
i := longestCommonPrefix(path, n.path)
// 倘若最长公共前缀长度小于 node.path 的长度,代表 node 需要分裂
// 举例而言:node.path = search,此时要插入的 path 为 see
// 最长公共前缀长度就是 2,len(n.path) = 6
// 需要分裂为 se -> arch
-> e
if i < len(n.path) {
// 原节点分裂后的后半部分,对应于上述例子的 arch 部分
child := node{
path: n.path[i:],
// 原本 search 对应的参数都要托付给 arch
indices: n.indices,
children: n.children,
handlers: n.handlers,
// 新路由 see 进入时,先将 search 的 priority 加 1 了,此时需要扣除 1 并赋给 arch
priority: n.priority - 1,
fullPath: n.fullPath,
}
// 先建立 search -> arch 的数据结构,后续调整 search 为 se
n.children = []*node{&child}
// 设置 se 的 indice 首字母为 a
n.indices = bytesconv.BytesToString([]byte{n.path[i]})
// 调整 search 为 se
n.path = path[:i]
// search 的 handlers 都托付给 arch 了,se 本身没有 handlers
n.handlers = nil
// ...
}
// 最长公共前缀长度小于 path,正如 se 之于 see
if i < len(path) {
// path see 扣除公共前缀 se,剩余 e
path = path[i:]
c := path[0]
// 根据 node.indices,辅助判断,其子节点中是否与当前 path 还存在公共前缀
for i, max := 0, len(n.indices); i < max; i++ {
// 倘若 node 子节点还与 path 有公共前缀,则令 node = child,并调到外层 for 循环 walk 位置开始新一轮处理
if c == n.indices[i] {
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// node 已经不存在和 path 再有公共前缀的子节点了,则需要将 path 包装成一个新 child node 进行插入
// node 的 indices 新增 path 的首字母
n.indices += bytesconv.BytesToString([]byte{c})
// 把新路由包装成一个 child node,对应的 path 和 handlers 会在 node.insertChild 中赋值
child := &node{
fullPath: fullPath,
}
// 新 child node append 到 node.children 数组中
n.addChild(child)
n.incrementChildPrio(len(n.indices) - 1)
// 令 node 指向新插入的 child,并在 node.insertChild 方法中进行 path 和 handlers 的赋值操作
n = child
n.insertChild(path, fullPath, handlers)
return
}
// 此处的分支是,path 恰好是其与 node.path 的公共前缀,则直接复制 handlers 即可
// 例如 se 之于 search
if n.handlers != nil {
panic("handlers are already registered for path '" + fullPath + "'")
}
n.handlers = handlers
// ...
return
}
func (n *node) insertChild(path string, fullPath string, handlers HandlersChain) {
// ...
n.path = path
n.handlers = handlers
// ...
}
补偿策略下面这段代码体现了,在每个 node 的 children 数组中,child node 在会依据 priority 有序排列,保证 priority 更高的 child node 会排在数组前列,被优先匹配.
func (n *node) incrementChildPrio(pos int) int {
cs := n.children
cs[pos].priority++
prio := cs[pos].priority
// Adjust position (move to front)
newPos := pos
for ; newPos > 0 && cs[newPos-1].priority < prio; newPos-- {
// Swap node positions
cs[newPos-1], cs[newPos] = cs[newPos], cs[newPos-1]
}
// Build new index char string
if newPos != pos {
n.indices = n.indices[:newPos] + // Unchanged prefix, might be empty
n.indices[pos:pos+1] + // The index char we move
n.indices[newPos:pos] + n.indices[pos+1:] // Rest without char at 'pos'
}
return newPos
}
检索路由树
下述代码展示了从路由树中匹配 path 对应 handler 的详细过程
type nodeValue struct {
// 处理函数链
handlers HandlersChain
// ...
}
// 从路由树中获取 path 对应的 handlers
func (n *node) getValue(path string, params *Params, skippedNodes *[]skippedNode, unescape bool) (value nodeValue) {
var globalParamsCount int16
// 外层 for 循环断点
walk:
for {
prefix := n.path
// 待匹配 path 长度大于 node.path
if len(path) > len(prefix) {
// node.path 长度 < path,且前缀匹配上
if path[:len(prefix)] == prefix {
// path 取为后半部分
path = path[len(prefix):]
// 遍历当前 node.indices,找到可能和 path 后半部分可能匹配到的 child node
idxc := path[0]
for i, c := range []byte(n.indices) {
// 找到了首字母匹配的 child node
if c == idxc {
// 将 n 指向 child node,调到 walk 断点开始下一轮处理
n = n.children[i]
continue walk
}
}
// ...
}
}
// 倘若 path 正好等于 node.path,说明已经找到目标
if path == prefix {
// ...
// 取出对应的 handlers 进行返回
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath
return
}
// ...
}
// 倘若 path 与 node.path 已经没有公共前缀,说明匹配失败,会尝试重定向,此处不展开
// ...
}
Gin.Context
核心数据结构
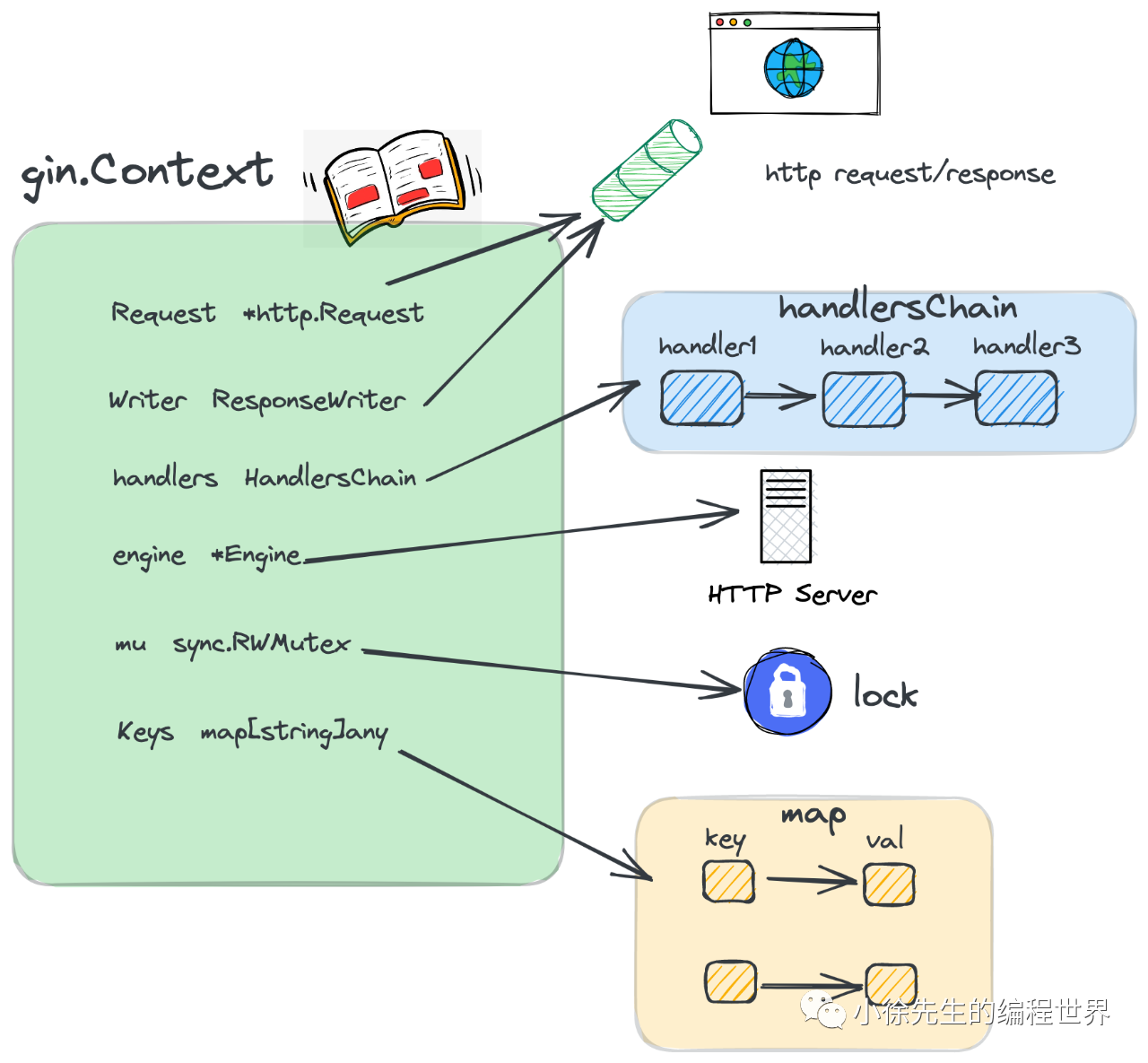
gin.Context 的定位是对应于一次 http 请求,贯穿于整条 handlersChain 调用链路的上下文,其中包含了如下核心字段:
- Request/Writer:http 请求和响应的 reader、writer 入口
- handlers:本次 http 请求对应的处理函数链
- index:当前的处理进度,即处理链路处于函数链的索引位置
- engine:Engine 的指针
- mu:用于保护 map 的读写互斥锁
- Keys:缓存 handlers 链上共享数据的 map
type Context struct {
// ...
// http 请求参数 用来读取客户端传输数据的接口(入口)
Request *http.Request
// http 响应 writer 处理后的请求(出口)
Writer ResponseWriter
// ...
// 处理函数链 是由路由树赋予的
handlers HandlersChain
// 当前处于处理函数链的索引
index int8
engine *Engine
// ...
// 读写锁,保证并发安全
mu sync.RWMutex
// key value 对存储 map
Keys map[string]any
// ..
}
复用策略
gin.Engine创建之初就会有一个context的对象池,可以用来复用,因为gin.Context作为请求的通用数据结构不可避免会频繁创建和销毁,gin框架使用sync.Pool来进行Context缓存复用
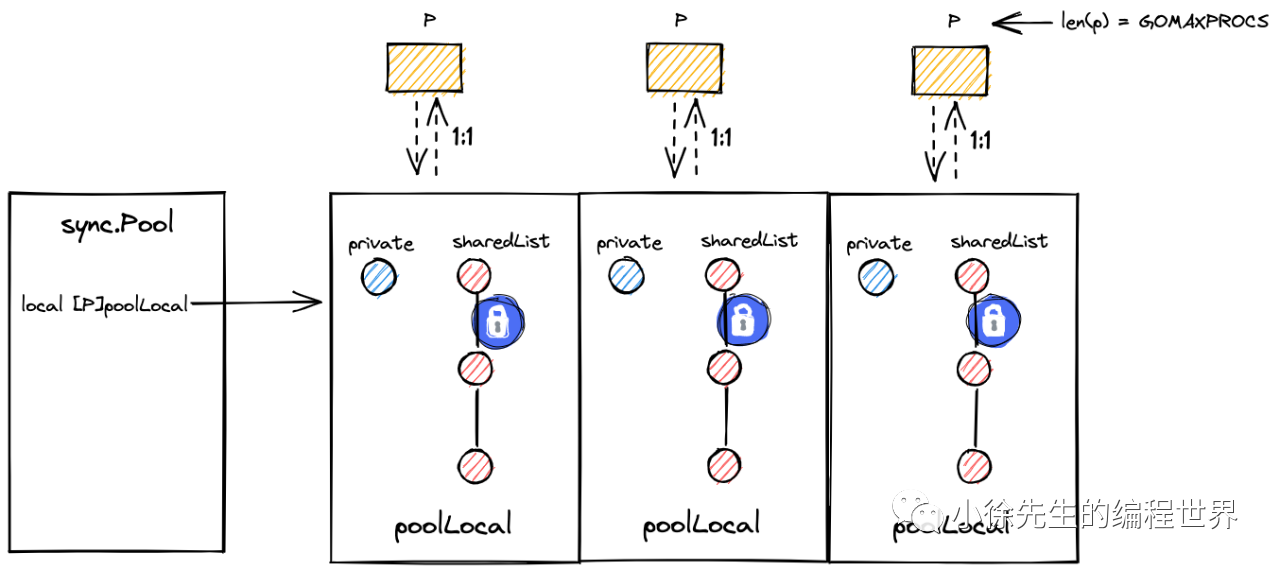
- http 请求到达时,从 pool 中获取 Context,倘若池子已空,通过 pool.New 方法构造新的 Context 补上空缺
- http 请求处理完成后,将 Context 放回 pool 中,用以后续复用
sync.Pool 并不是真正意义上的缓存,将其称为回收站或许更加合适,放入其中的数据在逻辑意义上都是已经被删除的,但在物理意义上数据是仍然存在的,这些数据可以存活两轮 GC 的时间,在此期间倘若有被获取的需求,则可以被重新复用.
sync.Pool里面有一个private 这个是对应P独有的,所以可以并发安全得读取,而shareList需要加锁,所有p都共享,所以会先在private寻找,找不到才去sharelist中找,如果没有会重新构造
type Engine struct {
// context 对象池
pool sync.Pool
}
func New() *Engine {
// ...
engine.pool.New = func() any {
return engine.allocateContext(engine.maxParams)
}
return engine
}
func (engine *Engine) allocateContext(maxParams uint16) *Context {
v := make(Params, 0, maxParams)
// ...
return &Context{engine: engine, params: &v, skippedNodes: &skippedNodes}
}
分配与回收时机
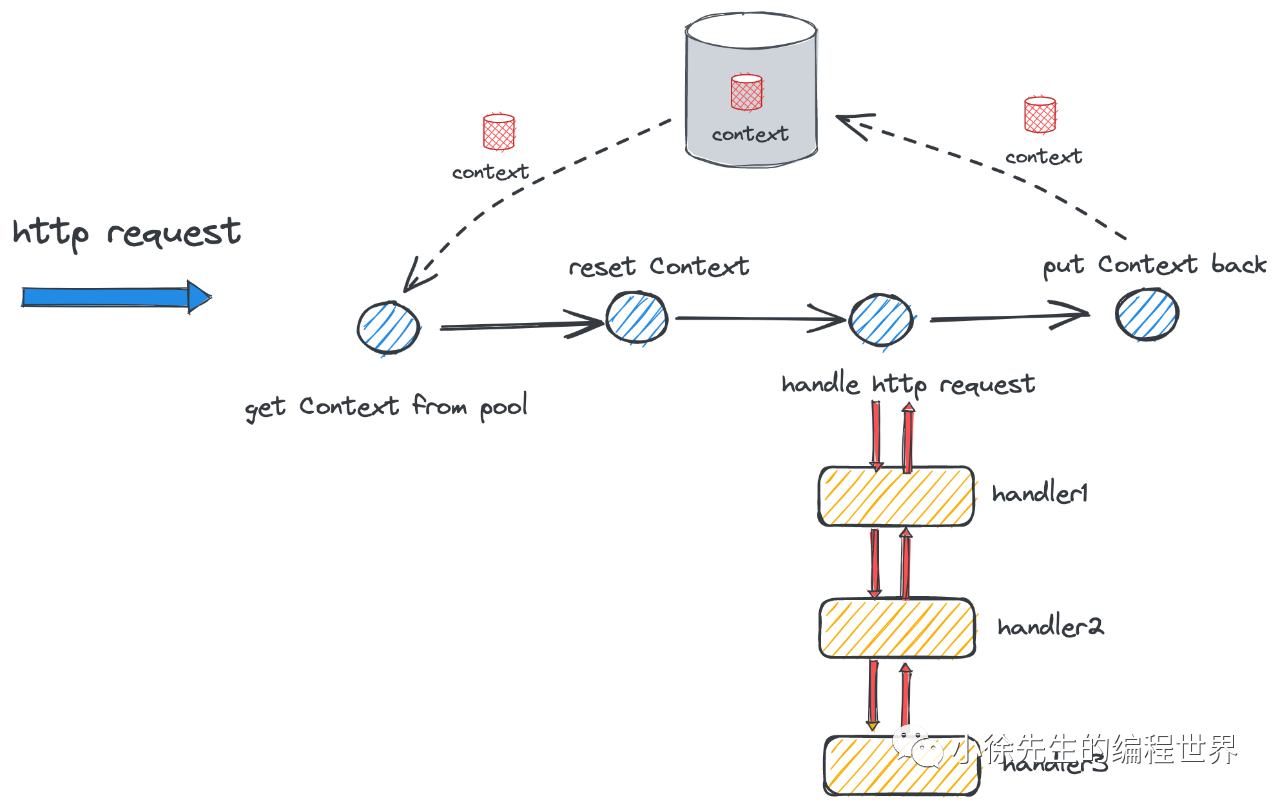
gin.Context 分配与回收的时机是在 gin.Engine 处理 http 请求的前后,位于 Engine.ServeHTTP 方法当中:
- 从池中获取 Context
- 重置 Context 的内容,使其成为一个空白的上下文
- 调用 Engine.handleHTTPRequest 方法处理 http 请求
- 请求处理完成后,将 Context 放回池中
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// 从对象池中获取一个 context
c := engine.pool.Get().(*Context)
// 重置/初始化 context
c.writermem.reset(w)
c.Request = req
c.reset()
// 处理 http 请求
engine.handleHTTPRequest(c)
// 把 context 放回对象池
engine.pool.Put(c)
}
Context的使用时机
1)handlesChain 入口
在Engine.handleHTTPRequest方法处理请求的时候,他会通过path匹配获取到路由树中的handlers链,然后将handlers链注入到context里面,然后启动Context.Next()开始链的遍历调用
func (engine *Engine) handleHTTPRequest(c *Context) {
// ...
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ {
if t[i].method != httpMethod {
continue
}
root := t[i].root
value := root.getValue(rPath, c.params, c.skippedNodes, unescape)
// ...
if value.handlers != nil {
c.handlers = value.handlers
c.fullPath = value.fullPath
c.Next()
c.writermem.WriteHeaderNow() // 响应
return
}
// ...
}
// ...
}
2)handlesChain遍历调用
推进 handlers 链调用进度的方法正是 Context.Next. 可以看到其中以 Context.index 为索引,通过 for 循环依次调用 handlers 链中的 handler. 每次函数调用其实调用的就是我们通过engine.POST 或者engine.GET各种方法注册handler函数 或者中间件等
func (c *Context) Next() {
c.index++ // 初始为-1
for c.index < int8(len(c.handlers)) {
c.handlers[c.index](c) // 其实就是压栈
c.index++
}
}
在这个过程中我们其实可以人为去干扰这个Next的执行,由于 Context 本身会暴露于调用链路中,因此用户可以在某个 handler 中通过手动调用 Context.Next 的方式来打断当前 handler 的执行流程,提前进入下一个 handler 的处理中.
由于此时本质上是一个方法压栈调用的行为,因此在后置位 handlers 链全部处理完成后,最终会回到压栈前的位置,执行当前 handler 剩余部分的代码逻辑.
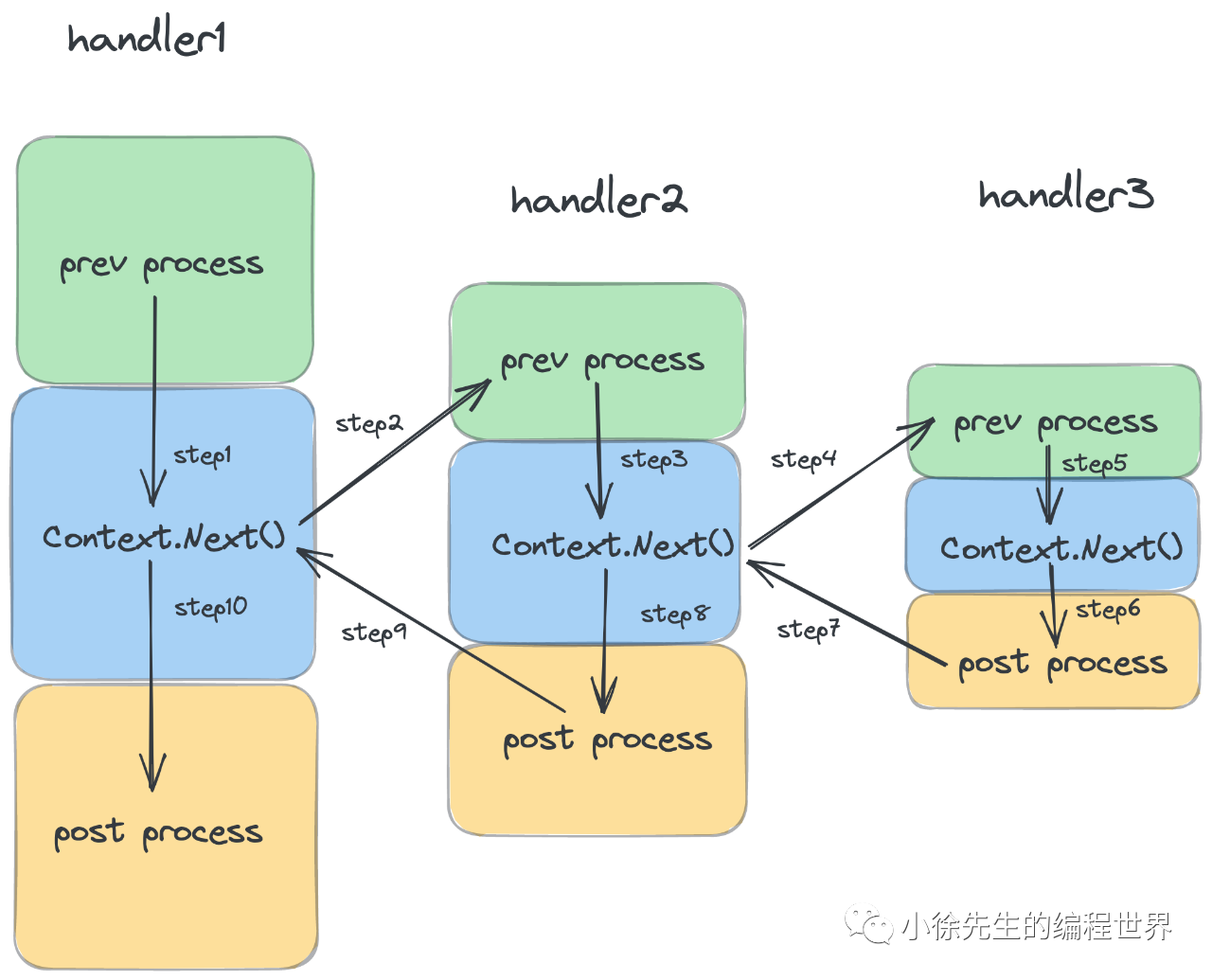
结合下面的代码示例来说,用户可以在某个 handler 中,于调用 Context.Next 方法的前后分别声明前处理逻辑和后处理逻辑,这里的“前”和“后”相对的是后置位的所有 handler 而言.
func myHandleFunc(c *gin.Context){
// 前处理
preHandle()
c.Next()
// 后处理
postHandle()
}
此外,用户可以在某个 handler 中通过调用 Context.Abort 方法实现 handlers 链路的提前熔断.
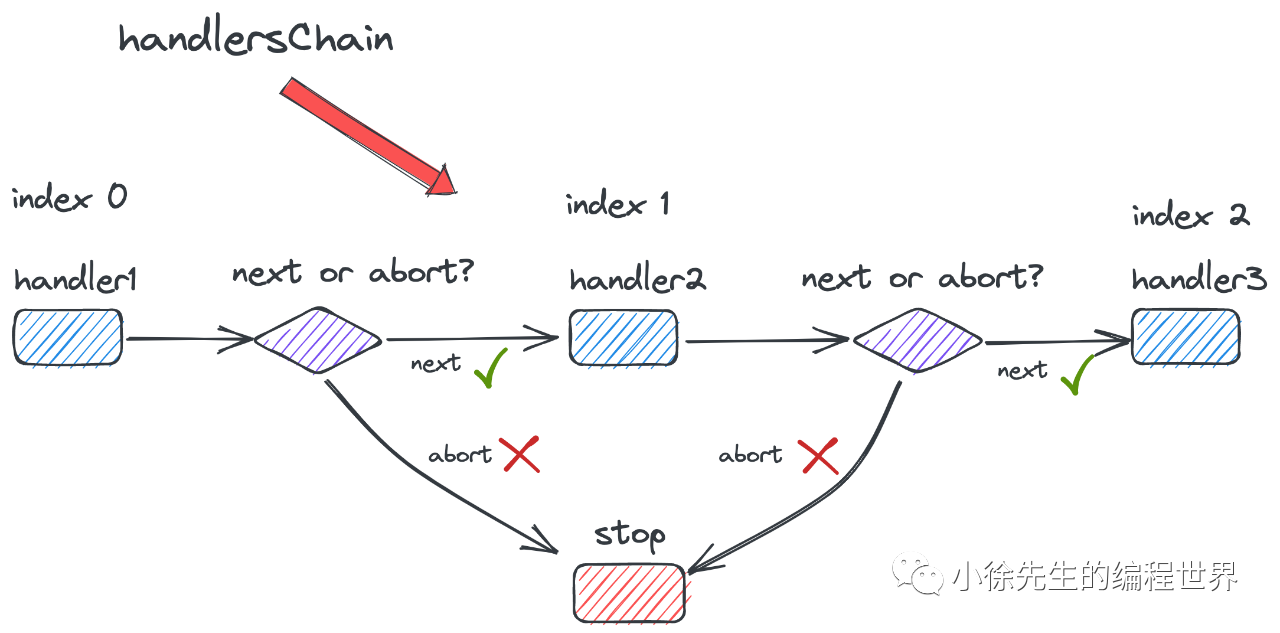
其实现原理是将 Context.index 设置为一个过载值 63,导致 Next 流程直接终止. 这是因为 handlers 链的长度必须小于 63,否则在注册时就会直接 panic. 因此在 Context.Next 方法中,一旦 index 被设为 63,则必然大于整条 handlers 链的长度,for 循环便会提前终止.
const abortIndex int8 = 63
func (c *Context) Abort() {
c.index = abortIndex
}
此外,用户还可以通过 Context.IsAbort 方法检测当前 handlerChain 是出于正常调用,还是已经被熔断.
func (c *Context) IsAborted() bool {
return c.index >= abortIndex
}
注册 handlers,倘若 handlers 链长度达到 63,则会 panic
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain {
finalSize := len(group.Handlers) + len(handlers)
// 断言 handlers 链长度必须小于 63
assert1(finalSize < int(abortIndex), "too many handlers")
// ...
}
3)共享数据
gin.Context 作为 handlers 链的上下文,还提供对外暴露的 Get 和 Set 接口向用户提供了共享数据的存取服务,相关操作都在读写锁的保护之下,能够保证并发安全.
type Context struct {
// ...
// 读写锁,保证并发安全
mu sync.RWMutex
// key value 对存储 map
Keys map[string]any
}
func (c *Context) Get(key string) (value any, exists bool) {
c.mu.RLock()
defer c.mu.RUnlock()
value, exists = c.Keys[key]
return
}
func (c *Context) Set(key string, value any) {
c.mu.Lock()
defer c.mu.Unlock()
if c.Keys == nil {
c.Keys = make(map[string]any)
}
c.Keys[key] = value
}