dlv调试使用
对于一个正在运行的进程 通过dlv attatch -p [pid] 可以进入现场调试,当前进程会停止。
如何生成coredump
环境变量GOTRACEBACK
GOTRACEBACK是用来控制panic发生时golang程序行为的,值是字符串
| 值 | 行为 |
|---|---|
| none | 不打印任何堆栈跟踪信息,不过崩溃的原因和哪行代码触发的panic还是会打印 |
| single | 只打印当前正在运行的触发panic的goroutine的堆栈以及runtime的堆栈;如果panic是runtime里发出的,则打印所有goroutine的堆栈跟踪信息 |
| all | 打印所有用户创建的goroutine的堆栈信息(不包含runtime的) |
| system | 在前面all的基础上把runtime相关的所有协程的堆栈信息也一起打印出来 |
| crash | 打印的内容和前面system一样,但还会额外生成对应操作系统上的coredump文件 |
go build main.go
GOTRACEBACK=crash ./main
然后就可以通过coredumpctl加载coredump文件(由系统集中管理了),然后就可以用dlv调试,注意coredump文件需要配合执行的程序比如下面的main,不然无法匹配内存映射
coredumpctl list # 查看所有崩溃的进程的coredump记录 找到进程ID
coredumpctl debug <list那给出的崩溃的进程的id> --debugger=<调试器程序的名字或路径> -A <传给调试器的参数>
coredumpctl debug 156814 --debugger=dlv -A core ./main
标准库接口
没有标准库函数可以主动触发coredump生成,但有可以在代码里设置panic时候的行为的,使用的值和GPTRACEBACK一模一样:debug.SetTraceback
这个函数优先级比环境变量高,但有个限制,它只能设置比环境变量的值打印更多信息的值,也就是说如果环境变量是all,那么这个函数就只能设置system和crash,不能设置none和single。
调试coredump
coredumpctl debug 156814 --debugger=dlv -A core ./main
然后按下面的步骤查看信息:
bt,查看当前的调用堆栈,找到触发panic的那行代码在哪个frame(栈帧)里- 看到是编号为10的frame,使用
frame 10进入这个栈帧 - 使用
locals查看当前栈帧内变量的值 p <变量名/表达式>查看变量的具体内容,或者执行一些简单的表达式- 还可以修改变量的值,设置断点后再次运行查看结果,不过例子里的问题到第四步就已经明了了。
goroutines查看所有的goroutinesgoroutine 1切换到1goroutines -with running查看running状态的goroutinebreakpoints查看所有断点- 设置断点
break package/path/to/file.go:lineNumber - 清除断点
clear <Number> stack查看当前调用的堆栈信息list显示当前位置附近源代码
程序正常运行生成dump
具体方法是dlv attach <pid>之后直接运行dump <输出coredump的文件名>命令,然后退出,这个命令本身比较耗时,进程用的内存越多就越慢,请谨慎在生产环境使用。
一次debug流程
背景是go在1.14.1中引入了一个协作式的有信号的抢占调度机制,那么很简单的想法就是把这个抢占调度的机制放在每个函数都会执行的一个函数上那正好,go在编译的时候有一个morestack函数,一旦有函数调用 这个函数就会被添加进去,顾名思义就是做栈空间检查 栈是不是需要扩容。
那有了这个函数就可以在这个函数里面加一个抢占调度的算法,那就是去判断当前协程等待100us是不是还没被调度,如果没有被调度那就会重新执行schedule。当然这个过程就需要通知其它的goroutine退出自己的running状态,把P给空出来,让我这个等待了很久的G去调度
golang在之前的版本中已经实现了抢占调度,不管是陷入到大量计算还是系统调用,大多可被sysmon扫描到并进行抢占。但有些场景是无法抢占成功的。比如轮询计算 for { i++ } 等,这类操作无法进行newstack、morestack、syscall,所以无法检测stackguard0 = stackpreempt。
go team已经意识到抢占是个问题,所以在1.14中加入了基于信号的协程调度抢占。原理是这样的,首先注册绑定 SIGURG 信号及处理方法runtime.doSigPreempt,sysmon会间隔性检测超时的p,然后发送信号,m收到信号后休眠执行的goroutine并且进行重新调度。
但是发现在项目代码中出现了死锁,调用dlv看卡在了什么地方,发现是在调用抢占的时候wait for remainning P’s stop voluntarily,也就是在等待所有p停住(置标识位)
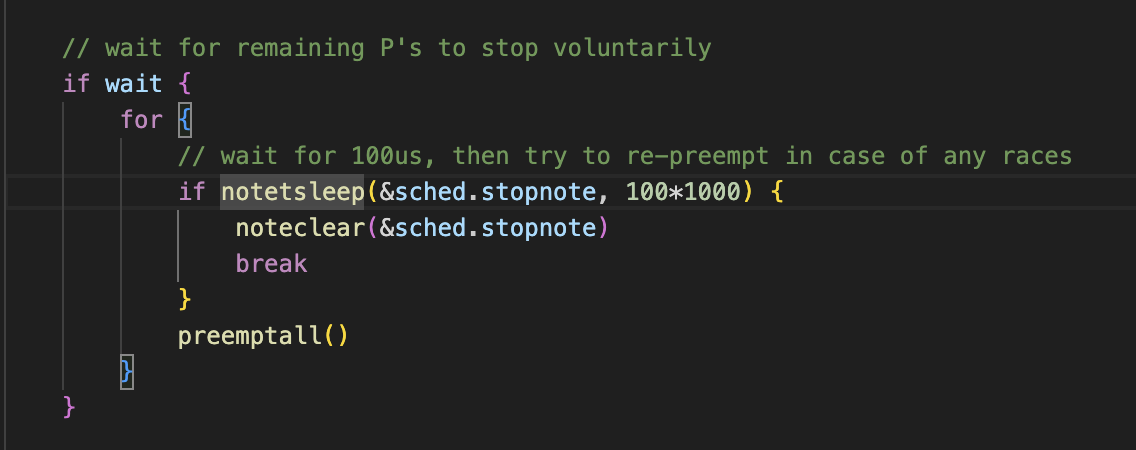
这里就是在循环每次等100us然后看看是否所有p都停了,如果没有停那就用preeptall去通知所有p停下来,一旦所有p都停了 notetsleep就会返回true,然后退出循环,抢占成功
按道理说所有p应该会在有限的时间被抢占然后停住,那这里就由于go自身底层代码有一些问题 导致存在p没有停下来,然后在执行schedule的时候一直等,出现了死锁
那就是需要去找为什么有p不能被停下来
dlv attach进现场 coredump一份快照,然后开始排查,那几先去看看有个全局变量是绑定了所有p的有个allp,所以p allp 看一下所有的p的status到底是啥,去根据p的status,那就找到了这个没有停下来的p status为1 表示他在running
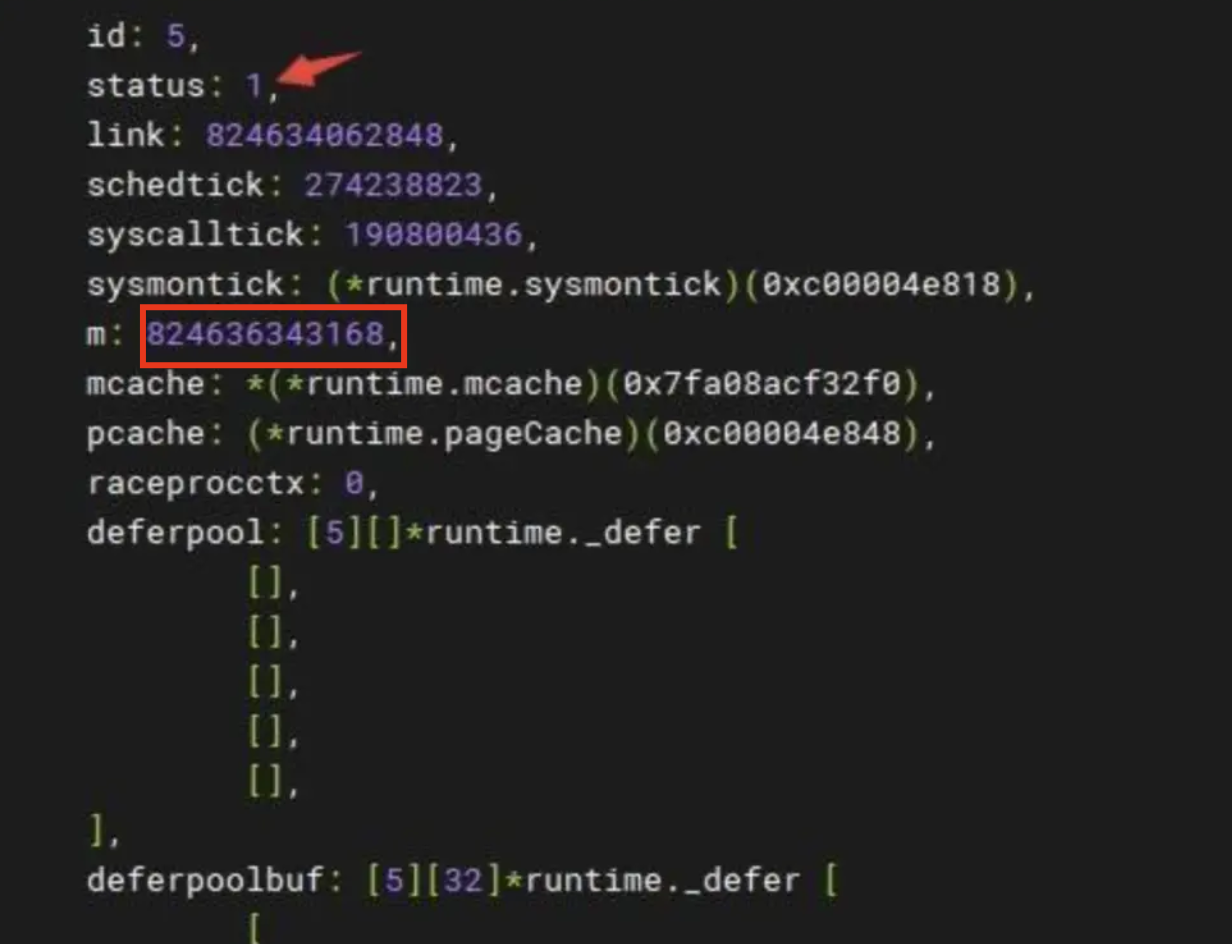
然后就看一下这个p绑定了哪个mp *(*runtime.m)(824636343168)打印出这个 p 绑定的这个 m 结构体的具体内容,m里面有curg变量可以找到当前正在执行的g
然后一看curg为空的 是一个nil 那具体原因就知道了,刚刚我们说他会去通知所有p停下来,改变状态,然后这个代码会判断p.m.g是不是空 空的话就不需要改变g的标识位来表示他被抢占,那么自然也就轮不到preemtM(mp)这个函数去发送已经全部退出的信号,自然而然这个schedule就要等
func preemptone(pp *p) bool {
mp := pp.m.ptr()
if mp == nil || mp == getg().m {
return false
}
gp := mp.curg
if gp == nil || gp == mp.g0 {
return false
}
gp.preempt = true
// Every call in a goroutine checks for stack overflow by
// comparing the current stack pointer to gp->stackguard0.
// Setting gp->stackguard0 to StackPreempt folds
// preemption into the normal stack overflow check.
gp.stackguard0 = stackPreempt
// Request an async preemption of this P.
if preemptMSupported && debug.asyncpreemptoff == 0 {
pp.preempt = true
preemptM(mp)
}
return true
}
但是问题就来了,这个curg为啥是空的呢,直接搜索curg是找不到的 curg设置的太多了,然后就换了个思路,观察到m结构体里面还有个procid,标识了线程号,看下threads线程情况,通过thread <procid> 看下线程执行的调用栈,就发现这个栈就是从morestack开始的,执行到addjuasttimer这个函数中osyield(),
也就是在morestack调用newstack的函数里面,就有检查是否抢占的函数,如果抢占,就会跑到goschedImpl里面去把当前g变为nil,再让g0再去调度 执行runtime.schedule,然后会进行Timer的check操作 这个checktimer是为了窃取的工作

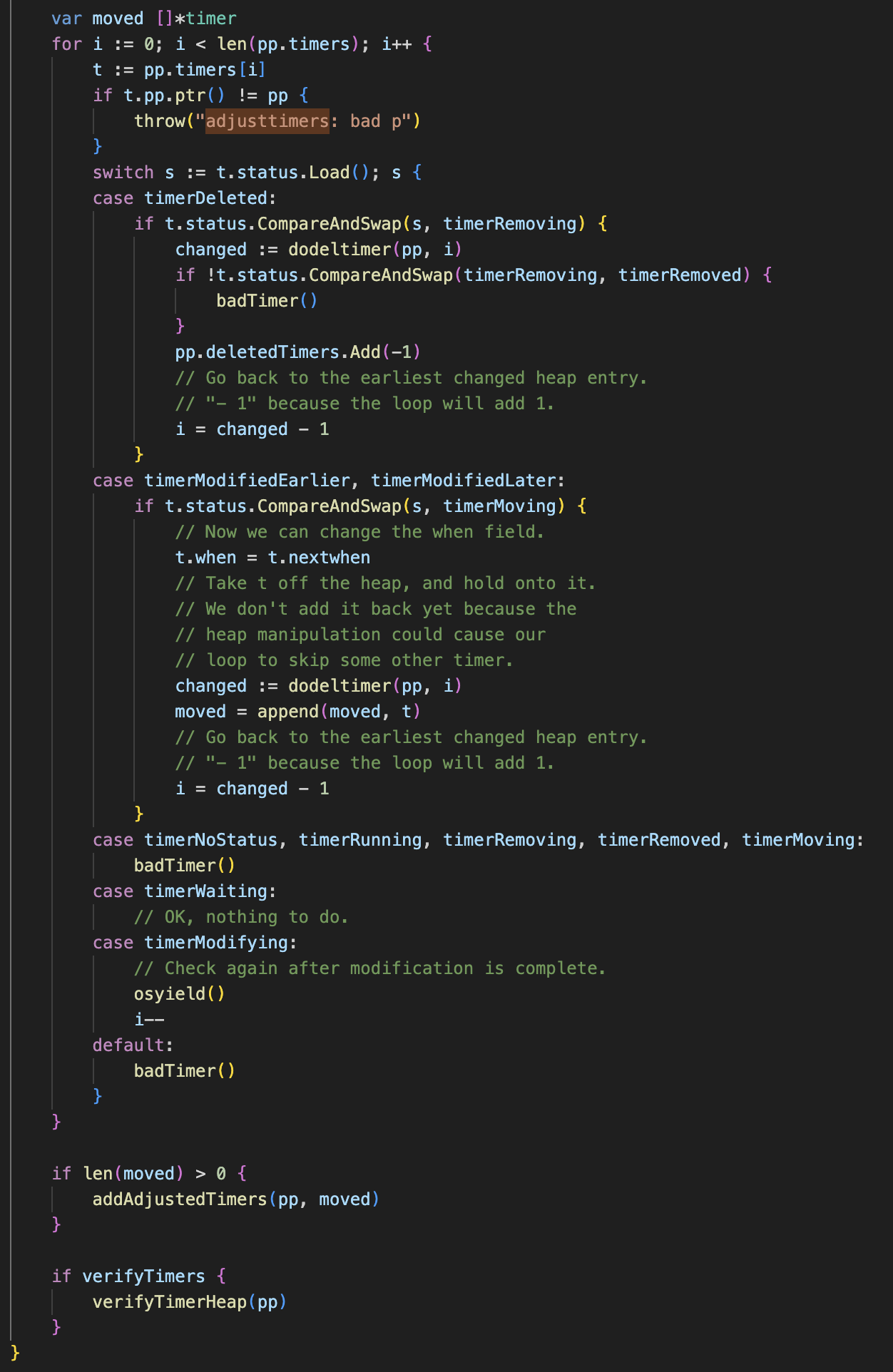
去查看这里的逻辑,是个for循环再遍历所有计时器。
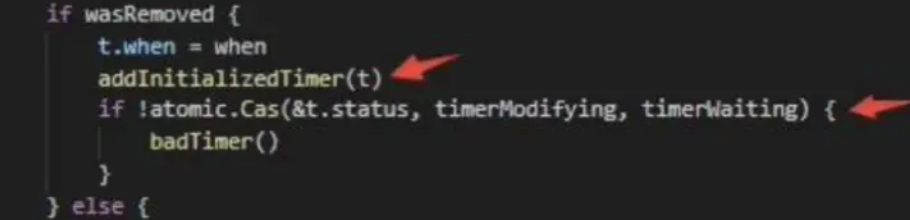
一看到这儿有个i—,他这里osyield要是每次执行都i–那不就铁死循环了吗 那基本可以确定就是,这里是在干啥呢,就是检查timer是否正在被修改,这个标识位要是表示有人在修改timer,就会循环,然后用osyield切到别的goroutine,i—表示先就不检查下一个定时器了了 下次再来检查一下这个退出timerModifying状态了没
那问题就可能出现在这儿,如果有一个正在修改timer的g还没把这个计时器从状态timerModifying修改为别的就被之前的preemptone给抢占了
现在就去这个函数调用栈开头看一下morestack,这个是汇编,发现调用了newstack进来看一下,这里面第一行就得到了当前的g
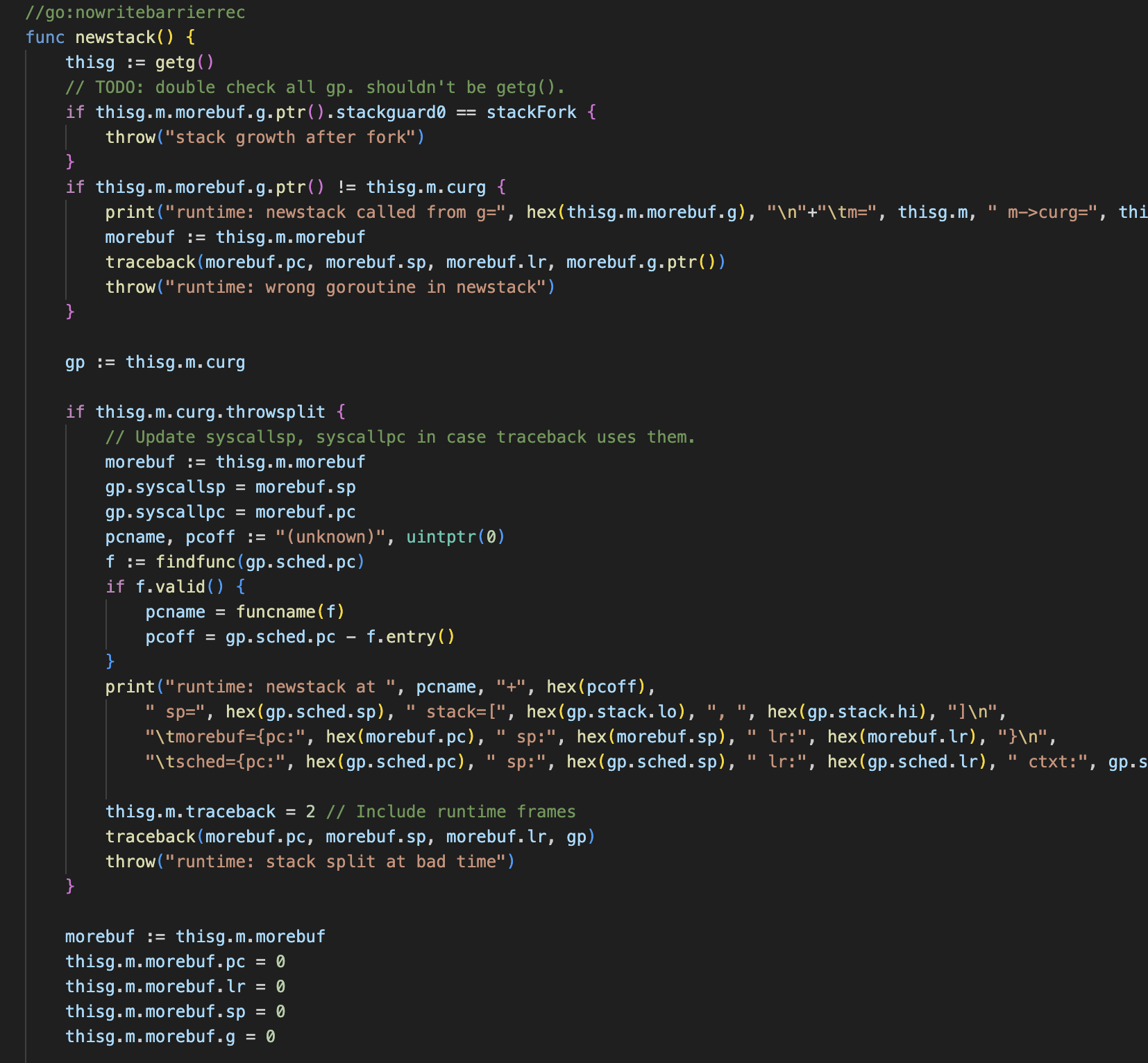
然后通过查看p thisg 发现thisg的goid居然是0,查了一下:
getg() and getg().m.curg
To get the current user g, use getg().m.curg.
getg() alone returns the current g, but when executing on the system or signal stacks, this will return the current M’s “g0” or “gsignal”, respectively. This is usually not what you want.
To determine if you’re running on the user stack or the system stack, use getg() == getg().m.curg.
也就是:
getg()
•getg():返回当前正在执行的 Goroutine 的指针。这个 Goroutine 可能是用户 Goroutine、系统 Goroutine(g0)或信号 Goroutine(gsignal)。
•当在用户 Goroutine 上运行时,getg() 返回的是用户 Goroutine 的指针。
•当在系统 Goroutine(g0)或信号 Goroutine(gsignal)上运行时,getg() 返回的是这些特殊 Goroutine 的指针。
getg().m.curg
•getg().m.curg:返回当前 M(操作系统线程)正在执行的用户 Goroutine 的指针。
•如果当前 M 正在执行用户 Goroutine,那么 getg().m.curg 返回该用户 Goroutine 的指针。
•如果当前 M 正在执行系统 Goroutine(g0)或信号 Goroutine(gsignal)getg().m.curg 仍然返回该 M 最后调度的用户 Goroutine 的指针。
所以要用thisg.m.curg才能获取真正当前g的goid,不然就是g0,然后继续看gp:=thisg.m.curg 这个对gp赋值了 这里就是我们后面看到curg变成nil前存在的g
p gp 看到这个goid=10,那么可能就是这个g出了问题!
通过goroutine 10 切换过来,bt查看调用栈,最后停在了addInitializedTimer(t)
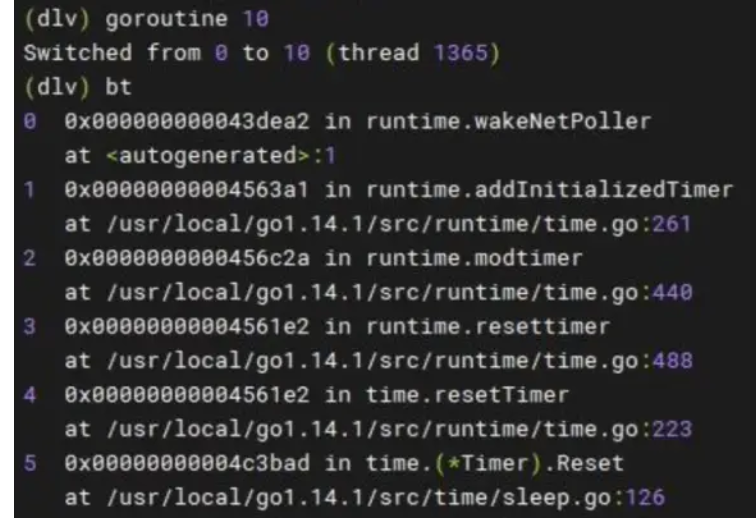
正好!这是因为我们log日志中调用了对timer 进行了 timer.sleep.Reset(d Duration)的操作。我们的这个日志系统,每天凌晨将日志文件重命名并创建一个新的日志文件,就会重置定时器,调用的是sleep.go里面的Reset方法,这个方法最终就调用到了runtime.resettimer 然后就是这个addInitializedTimer
具体来说就是duration就是24小时 创建一个24h的定时器,然后定时器一到期就会通知日志任务去轮转(做新的日志),然后重置定时器
那这个原因可以确定:
g10 在修改 timer 的过程中,只是先置了Timer的标识位timerModifying,然后就被一个无名g0 抢占,等待调度,然后这个g0又需要等g10把 timer 修改完,死锁发生了
disass看下汇编
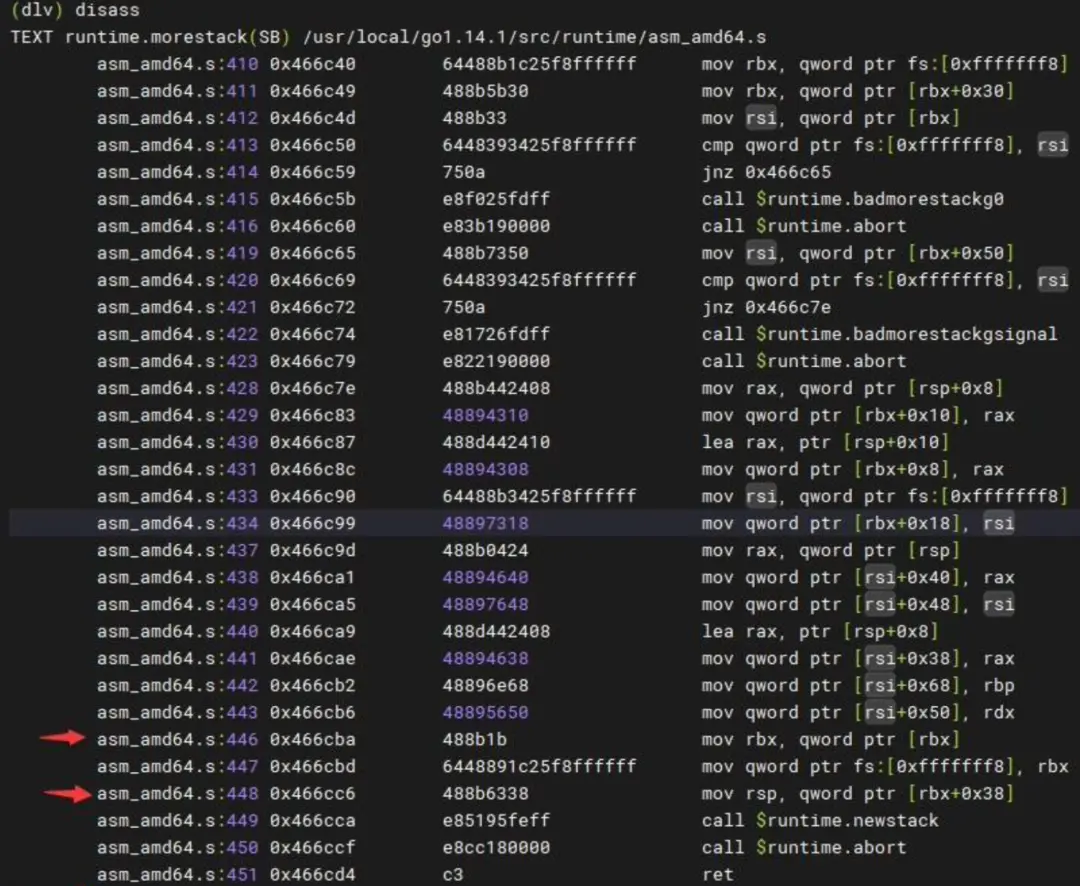
为什么只能看到morestack之后的执行栈?
通过注释和阅读源码可以发现,在执行 newstack 前,morestack 通过修改 bx 和 sp 寄存器(用来标识栈底和栈顶)把执行栈替换为了当前 m 所有的 g0 的执行栈