Redis Serialization Protocol(RESP)
redis的通信协议,有以下:
正常回复 “+”开头, “\r\n”结尾的形式,例如”+OK\r\n”
错误回复 “-”开头, “\r\n”结尾的形式,例如”-Error message\r\n”
整数 “:”开头, “\r\n”结尾的形式,例如”:123456\r\n”
批量字符串 bulk strings “$”开头, 然后跟实际发送字节数, “\r\n”结尾的形式, 例如
”$10\\r\\nstringtest\\r\\n”代表“stringtest”例如”$0\\r\\n\\r\\n”空字符串””例如”$14\\r\\nimooc\\r\\nmoody\\r\\n””imooc\\r\\nmoody”带数字好处就是不会把字符串本身的\r\n给识别了 $-1表示空数组 ”*”开头,后面跟成员个数,然后每个命令字符用$开头加字节数 然后再跟字符串
*3\\r\\n$3\\r\\nSET\\r\\n$3\\r\\nkey\\r\\n$5\\r\\nvalue\\r\\nSET key value
TCP服务器
首先redis服务器是基于TCP的应用服务器,那么需要有自己的创建链接管理链接和关闭链接的方式。
基于golang的net库 他实现了epoll的网络模型,支持IO多路复用,因此性能比较高,所以用netpoller编写服务器
首先服务器要 绑定tcp端口,然后循环调用Accept() 这个会一直阻塞等待客户端链接,一旦有客户端链接就可以开一个协程处理这个链接
考虑应用层的粘包问题,客户端发来的信息是基于RESP协议的信息,我们需要根据这个RESP协议去解析不同命令(在解析器实现)
关闭链接,关闭TCP链接前要完成必要的清理操作,包括完成整在传输的数据、关闭和客户端的TCP链接等。步骤是:先关闭listener阻止后续可能的客户端请求,然后遍历所有已经有的连接,逐个调用close方法。对每个client连接调用close的时候,要查看client的watinggroup(这个是决定是不是还在发数据 每次发送Write给client的时候都会Add 1,要等数据传输完)
注意关闭链接可以通过信号机制来调用。比如可以异步监听系统的syscall 比如SIGINT等信号(比如ctrl+c就会发送),一旦从channel中收到信号就开始关闭链接的函数调用
协议解析器
协议解析器将实现其 Handler 接口充当应用层服务器。协议解析器将接收 Socket 传来的数据,并将其数据还原为 [][]byte 格式,如 "*3\\r\\n$3\\r\\nSET\\r\\n$3\\r\\nkey\\r\\n$5\\r\\nvalue\\r\\n" 将被还原为 ['SET', 'key', 'value']。
bufio 标准库可以将从 reader 读到的数据缓存到 buffer 中,直至遇到分隔符或读取完毕后返回,所以我们使用 reader.ReadBytes('\\n') 来保证每次读取到完整的一行。
里面有个坑坑坑!!比如Redis 可以正确接收并执行SET "a\\r\\nb" 1指令
这个\\n 在这儿就出问题了!被当成了两行,所以读取了$n过后直接读取指定长度的内容
解析器的流程大概是:
将读到的数据解析为 是否有多数据 还是单数据命令 然后对应调用不同的流程去解析命令和相应数据,然后在过程中封装了一个reply结构,作为命令解析的返回结果,如果命令本身就解析有错会返回error相关的reply,还有诸如ok之类的reply 或者返回修改了多少个数据之类的int值的reply
KV实现的内存数据库
Concurrent Hash Map
KV 内存数据库的核心是并发安全的哈希表,常见的设计有几种:
sync.map: golang 官方提供的并发哈希表, 适合读多写少的场景。但是他有个问题,在dirty刚被提升 也就是read指向了这个dirty的数据,然后新dirty置为空的时候,这里为了保证read和dirty数据不一致并且下次dirty发生升级的时候不丢失数据,dirty需要有read的完整数据,而且要保证这个read在复制给dirty的时候没有被修改,这个时候如果数据非常大,可能会阻塞,存在性能问题
juc.ConcurrentHashMap: java 的并发哈希表采用分段锁实现。在进行扩容时访问哈希表线程都将协助进行 rehash 操作,在 rehash 结束前所有的读写操作都会阻塞。因为缓存数据库中键值对数量巨大且对读写操作响应时间要求较高,使用juc的策略是不合适的。
memcached hashtable: 在后台线程进行 rehash 操作时,主线程会判断要访问的哈希槽是否已被 rehash 从而决定操作 old_hashtable 还是操作 primary_hashtable。
memcached hashtable 的渐进式 Rehash 策略使主线程和rehash线程之间的 data race 限制在哈希槽内,最小化rehash操作对读写操作的影响,这是最理想的实现方式。但由于作者才疏学浅无法使用 golang 实现该策略故忍痛放弃(主要原因在于 golang 没有 volatile 关键字, 保证可见性的操作非常复杂),欢迎各位读者讨论。
本文采用 golang 社区广泛使用的分段锁策略。shard 是有锁保护的 map, 当 shard 进行 rehash 时会阻塞shard内的读写,但不会对其他 shard 造成影响。
这种策略简单可靠易于实现,但由于需要两次 hash 性能略差
主要sync.map的问题:
它在一些场景下也有问题,如果熟悉Java的同学,可以对比一下java的ConcurrentHashMap的实现,在map的数据非常大的情况下,一把锁会导致大并发的客户端共争一把锁,Java的解决方案是shard, 内部使用多个锁,每个区间共享一把锁,这样减少了数据共享一把锁带来的性能影响
sync.Map的实现有几个优化点,这里先列出来,我们后面慢慢分析。
空间换时间。 通过冗余的两个数据结构(read、dirty),实现加锁对性能的影响。
使用只读数据(read),避免读写冲突。
动态调整,miss次数多了之后,将dirty数据提升为read。
double-checking。
延迟删除。 删除一个键值只是打标记,只有在提升dirty的时候才清理删除的数据。
优先从read读取、更新、删除,因为对read的读取不需要锁。
哈希算法选择FNV算法 这个算法核心思想也就是乘以大质数和异或
const prime32 = uint32(16777619)
func fnv32(key string) uint32 {
hash := uint32(2166136261)
for i := 0; i < len(key); i++ {
hash *= prime32
hash ^= uint32(key[i])
}
return hash
}
LockMap
上一节实现的ConcurrentMap 可以保证对单个 key 操作的并发安全性,但是仍然无法满足需求:
Incr 命令需要完成: 读取 -> 做加法 -> 写入 三步操作
MSETNX 命令当且仅当所有给定键都不存在时所有给定键设置值, 因此我们需要锁定所有给定的键直到完成所有键的检查和设置
因此我们需要实现 db.Locker 用于锁定一个或一组 key 并在我们需要的时候释放锁。
实现 db.Locker 最直接的想法是使用一个 map[string]*sync.RWMutex, 加锁过程分为两步: 初始化对应的锁 -> 加锁, 解锁过程也分为两步: 解锁 -> 释放对应的锁。那么存在一个无法解决的并发问题:
由于 t3 时协程B释放了锁,t4 时协程A试图加锁会失败。
若我们在解锁时不释放锁就可以避免该异常的发生,但是每个曾经使用过的锁都无法释放从而造成严重的内存泄露。
我们注意到哈希表的长度远少于可能的键的数量,反过来说多个键可以共用一个哈希槽。若我们不为单个键加锁而是为它所在的哈希槽加锁,因为哈希槽的数量非常少即使不释放锁也不会占用太多内存。
作者根据这种思想实现了 LockMap 来解决并发控制问题。
type Locks struct {
table []*sync.RWMutex
}
func Make(tableSize int) *Locks {
table := make([]*sync.RWMutex, tableSize)
for i := 0; i < tableSize; i++ {
table[i] = &sync.RWMutex{}
}
return &Locks{
table: table,
}
}
func (locks *Locks)Lock(key string) {
index := locks.spread(fnv32(key))
mu := locks.table[index]
mu.Lock()
}
func (locks *Locks)UnLock(key string) {
index := locks.spread(fnv32(key))
mu := locks.table[index]
mu.Unlock()
}
在锁定多个key时需要注意,若协程A持有键a的锁试图获得键b的锁,此时协程B持有键b的锁试图获得键a的锁则会形成死锁。
解决方法是所有协程都按照相同顺序加锁,若两个协程都想获得键a和键b的锁,那么必须先获取键a的锁后获取键b的锁,这样就可以避免循环等待。
内存数据库代码结构
最后为打算阅读源码的朋友们简单介绍一下 godis/database 包的代码结构:
MultiDB 实现了 database 接口,server.Handler 会持有一个 MultiDB 实例作为 Redis 存储引擎,并通过 Exec 函数将命令行传递给 MultiDB。
MultiDB 是支持 select 命令的多数据库引擎,它持有多个单数据库实例(godis.DB)以及支持发布订阅、AOF持久化所需的 pubsub.Hub 和 aof.Handler。
MultiDB.Exec 函数是 MultiDB 的总入口,它会自行处理鉴权、发布订阅、AOF相关命令以及FLUSHALL等系统命令,其它命令会调用被选中数据库的 DB.Exec 函数执行。
godis.DB.Exec 函数会自行处理 multi、exec 等事务控制命令,并调用 DB.execNormalCommand 函数处理常规命令。这里的常规命令是指仅读写有限个 key、可以在事务内执行且可以回滚的命令,比如 get、set、lpush 等命令,flushdb、keys 等命令不属于常规命令。
godis/database/router.go 中的 RegisterCommand函数负责注册常规命令。
实现一个常规命令需要提供3个函数:
ExecFunc 是实际执行命令的函数,如: execHSet
PrepareFunc 在 ExecFunc 前执行,负责分析命令行读写了哪些 key 便于进行加锁
UndoFunc 仅在事务中被使用,负责准备 undo logs 以备事务执行过程中遇到错误需要回滚。
跳表实现SortedSet
实现ZRange命令最简单的数据结构是有序链表:

在有序链表上实现ZRange key start end命令需要进行end次查询, 即时间复杂度为 O(n)
跳表的优化思路是添加上层链表,上层链表中会跳过一些节点。如图所示:
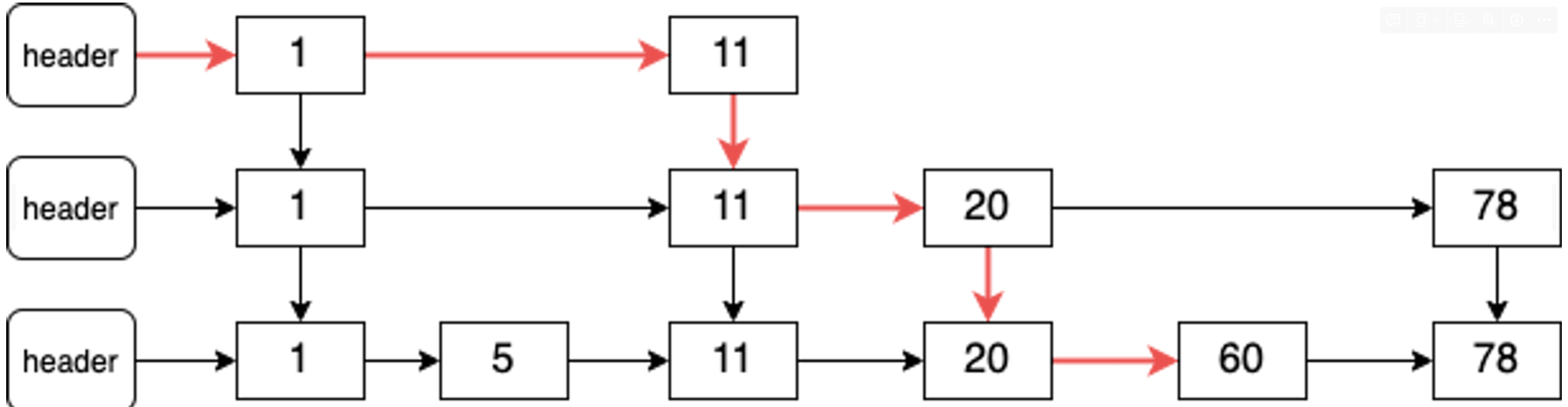 在有两层的跳表中,搜索的时间复杂度降低为了O(n / 2)。以此类推在有 log2(n) 层的跳表中,搜索元素的时间复杂度为O(log n)。
在有两层的跳表中,搜索的时间复杂度降低为了O(n / 2)。以此类推在有 log2(n) 层的跳表中,搜索元素的时间复杂度为O(log n)。
// 对外的元素抽象
type Element struct {
Member string
Score float64
}
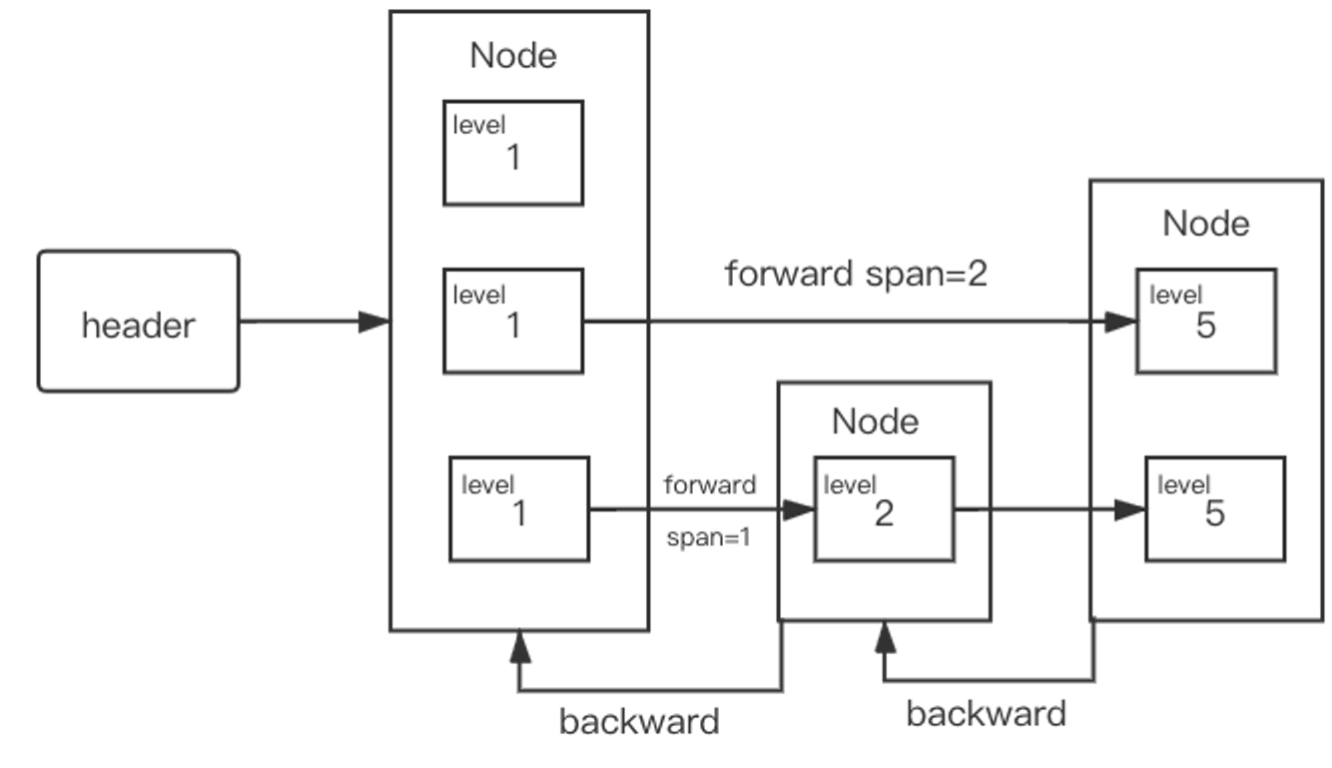
type Node struct {
Element // 元素的名称和 score
backward *Node // 后向指针
level []*Level // 前向指针, level[0] 为最下层
}
// 节点中每一层的抽象
type Level struct {
forward *Node // 指向同层中的下一个节点
span int64 // 到 forward 跳过的节点数
}
// 跳表的定义
type skiplist struct {
header *Node
tail *Node
length int64
level int16
}
查找节点
有了上文的描述查找节点的逻辑不难实现, 以 RangeByRank 的核心逻辑为例:
// 寻找排名为 rank 的节点, rank 从1开始
func (skiplist *skiplist) getByRank(rank int64)*Node {
var i int64 = 0
n := skiplist.header
// 从顶层向下查询
for level := skiplist.level - 1; level >= 0; level-- {
// 从当前层向前搜索
// 若当前层的下一个节点已经超过目标 (i+n.level[level].span > rank),则结束当前层搜索进入下一层
for n.level[level].forward != nil && (i+n.level[level].span) <= rank {
i += n.level[level].span
n = n.level[level].forward
}
if i == rank {
return n
}
}
return nil
}
插入节点
func (skiplist *skiplist)insert(member string, score float64)*Node {
// 寻找新节点的先驱节点,它们的 forward 将指向新节点
// 因为每层都有一个 forward 指针, 所以每层都会对应一个先驱节点
// 找到这些先驱节点并保存在 update 数组中
update := make([]*Node, maxLevel)
rank := make([]int64, maxLevel) // 保存各层先驱节点的排名,用于计算span
node := skiplist.header
for i := skiplist.level - 1; i >= 0; i-- { // 从上层向下寻找
// 初始化 rank
if i == skiplist.level - 1 {
rank[i] = 0
} else {
rank[i] = rank[i + 1]
}
if node.level[i] != nil {
// 遍历搜索
for node.level[i].forward != nil &&
(node.level[i].forward.Score < score ||
(node.level[i].forward.Score == score && node.level[i].forward.Member < member)) { // same score, different key
rank[i] += node.level[i].span
node = node.level[i].forward
}
}
update[i] = node
}
level := randomLevel() // 随机决定新节点的层数
// 可能需要创建新的层
if level > skiplist.level {
for i := skiplist.level; i < level; i++ {
rank[i] = 0
update[i] = skiplist.header
update[i].level[i].span = skiplist.length
}
skiplist.level = level
}
// 创建新节点并插入跳表
node = makeNode(level, score, member)
for i := int16(0); i < level; i++ {
// 新节点的 forward 指向先驱节点的 forward
node.level[i].forward = update[i].level[i].forward
// 先驱节点的 forward 指向新节点
update[i].level[i].forward = node
// 计算先驱节点和新节点的 span
node.level[i].span = update[i].level[i].span - (rank[0] - rank[i])
update[i].level[i].span = (rank[0] - rank[i]) + 1
}
// 新节点可能不会包含所有层
// 对于没有层,先驱节点的 span 会加1 (后面插入了新节点导致span+1)
for i := level; i < skiplist.level; i++ {
update[i].level[i].span++
}
// 更新后向指针
if update[0] == skiplist.header {
node.backward = nil
} else {
node.backward = update[0]
}
if node.level[0].forward != nil {
node.level[0].forward.backward = node
} else {
skiplist.tail = node
}
skiplist.length++
return node
}
删除节点
// 删除操作可能一次删除多个节点
func (skiplist *skiplist) RemoveRangeByRank(start int64, stop int64)(removed []*Element) {
var i int64 = 0 // 当前指针的排名
update := make([]*Node, maxLevel)
removed = make([]*Element, 0)
// 从顶层向下寻找目标的先驱节点
node := skiplist.header
for level := skiplist.level - 1; level >= 0; level-- {
for node.level[level].forward != nil && (i+node.level[level].span) < start {
i += node.level[level].span
node = node.level[level].forward
}
update[level] = node
}
i++
node = node.level[0].forward // node 是目标范围内第一个节点
// 删除范围内的所有节点
for node != nil && i < stop {
next := node.level[0].forward
removedElement := node.Element
removed = append(removed, &removedElement)
skiplist.removeNode(node, update)
node = next
i++
}
return removed
}
// 传入目标节点和删除后的先驱节点
// 在批量删除时我们传入的 update 数组是相同的
func (skiplist *skiplist) removeNode(node *Node, update []*Node) {
for i := int16(0); i < skiplist.level; i++ {
// 如果先驱节点的forward指针指向了目标节点,则需要修改先驱的forward指针跳过要删除的目标节点
// 同时更新先驱的 span
if update[i].level[i].forward == node {
update[i].level[i].span += node.level[i].span - 1
update[i].level[i].forward = node.level[i].forward
} else {
update[i].level[i].span--
}
}
// 修改目标节点后继节点的backward指针
if node.level[0].forward != nil {
node.level[0].forward.backward = node.backward
} else {
skiplist.tail = node.backward
}
// 必要时删除空白的层
for skiplist.level > 1 && skiplist.header.level[skiplist.level-1].forward == nil {
skiplist.level--
}
skiplist.length--
}
Pipeline模式的redis客户端
通常 TCP 客户端的通信模式都是阻塞式的: 客户端发送请求 -> 等待服务端响应 -> 发送下一个请求。因为需要等待网络传输数据,完成一次请求循环需要等待较多时间。
我们能否不等待服务端响应直接发送下一条请求呢?答案是肯定的。
TCP 作为全双工协议可以同时进行上行和下行通信,不必担心客户端和服务端同时发包会导致冲突。
我们为每一个 tcp 连接分配了一个 goroutine 可以保证先收到的请求先先回复。另一个方面,tcp 协议会保证数据流的有序性,同一个 tcp 连接上先发送的请求服务端先接收,先回复的响应客户端先收到。因此我们不必担心混淆响应所对应的请求。
这种在服务端未响应时客户端继续向服务端发送请求的模式称为 Pipeline 模式。因为减少等待网络传输的时间,Pipeline 模式可以极大的提高吞吐量,减少所需使用的 tcp 链接数。
pipeline 模式的 redis 客户端需要有两个后台协程程负责 tcp 通信,调用方通过 channel 向后台协程发送指令,并阻塞等待直到收到响应,这是一个典型的异步编程模式。
定义client结构体
type Client struct {
conn net.Conn // 与服务端的 tcp 连接
pendingReqs chan *Request // 等待发送的请求
waitingReqs chan *Request // 等待服务器响应的请求
ticker *time.Ticker // 用于触发心跳包的计时器
addr string
ctx context.Context
cancelFunc context.CancelFunc
writing *sync.WaitGroup // 有请求正在处理不能立即停止,用于实现 graceful shutdown
}
type Request struct {
id uint64 // 请求id
args [][]byte // 上行参数
reply redis.Reply // 收到的返回值
heartbeat bool // 标记是否是心跳请求
waiting *wait.Wait // 调用协程发送请求后通过 waitgroup 等待请求异步处理完成
err error
}
调用者将请求发送给后台协程,并通过 wait group 等待异步处理完成:
func (client *Client) Send(args [][]byte) redis.Reply {
// 新封装一个request请求
request := &request{
args: args,
heartbeat: false,
waiting: &wait.Wait{},
}
// 对应的watinggroup++
request.waiting.Add(1)
client.working.Add(1)
defer client.working.Done() // 最后无论如何都要保证client的wg释放
client.pendingReqs <- request // 请求入队 进入channel
timeout := request.waiting.WaitWithTimeout(maxWait) // 等待响应或者超时
if timeout {
return reply.MakeErrReply("server time out")
}
if request.err != nil {
return reply.MakeErrReply("request failed")
}
return request.reply
}
那核心就是后台如何读写,写协程如下
// 写协程入口
func (client *Client) handleWrite() {
// 从客户端的channel中拿到待处理请求,挨个处理
for req := range client.pendingReqs {
client.doRequest(req)
}
}
// 发送请求
func (client *Client) doRequest(req *request) {
if req == nil || len(req.args) == 0 {
return
}
// 序列化请求 客户端的消息是封装的reply,解析转换成bytes
re := reply.MakeMultiBulkReply(req.args)
bytes := re.ToBytes()
_, err := client.conn.Write(bytes) // write发送出去
i := 0
// 失败重试
for err != nil && i < 3 {
err = client.handleConnectionError(err)
if err == nil {
_, err = client.conn.Write(bytes)
}
i++
}
if err == nil {
// 发送成功等待服务器响应
client.waitingReqs <- req
} else {
req.err = err
req.waiting.Done()
}
}
读协程就是用协议解析器,把发送的bytes转换成reply
// 读协程是个 RESP 协议解析器
func (client *Client) handleRead() error {
ch := parser.ParseStream(client.conn)
for payload := range ch {
if payload.Err != nil {
client.finishRequest(reply.MakeErrReply(payload.Err.Error()))
continue
}
client.finishRequest(payload.Data)
}
return nil
}
// 收到服务端的响应
func (client *Client) finishRequest(reply redis.Reply) {
defer func() {
if err := recover(); err != nil {
debug.PrintStack()
logger.Error(err)
}
}()
request := <-client.waitingReqs
if request == nil {
return
}
request.reply = reply
if request.waiting != nil {
request.waiting.Done()
}
}
client的构造器和启动协程
func MakeClient(addr string) (*Client, error) {
conn, err := net.Dial("tcp", addr)
if err != nil {
return nil, err
}
ctx, cancel := context.WithCancel(context.Background())
return &Client{
addr: addr,
conn: conn,
sendingReqs: make(chan *Request, chanSize),
waitingReqs: make(chan *Request, chanSize),
ctx: ctx,
cancelFunc: cancel,
writing: &sync.WaitGroup{},
}, nil
}
func (client *Client) Start() {
client.ticker = time.NewTicker(10 * time.Second)
go client.handleWrite()
go func() {
err := client.handleRead()
logger.Warn(err)
}()
go client.heartbeat()
}
关闭client
func (client *Client) Close() {
// 先阻止新请求进入队列
close(client.sendingReqs)
// 等待处理中的请求完成
client.writing.Wait()
// 释放资源
_ = client.conn.Close() // 关闭与服务端的连接,连接关闭后读协程会退出
client.cancelFunc() // 使用 context 关闭读协程
close(client.waitingReqs) // 关闭队列
}
集群实现
一致性hash
在采用分片方式建立分布式缓存时,我们面临的第一个问题是如何决定存储数据的节点。最自然的方式是参考 hash 表的做法,假设集群中存在 n 个节点,我们用 node = hashCode(key) % n 来决定所属的节点。
普通 hash 算法解决了如何选择节点的问题,但在分布式系统中经常出现增加节点或某个节点宕机的情况。若节点数 n 发生变化, 大多数 key 根据 node = hashCode(key) % n 计算出的节点都会改变。这意味着若要在 n 变化后维持系统正常运转,需要将大多数数据在节点间进行重新分布。这个操作会消耗大量的时间和带宽等资源,这在生产环境下是不可接受的。
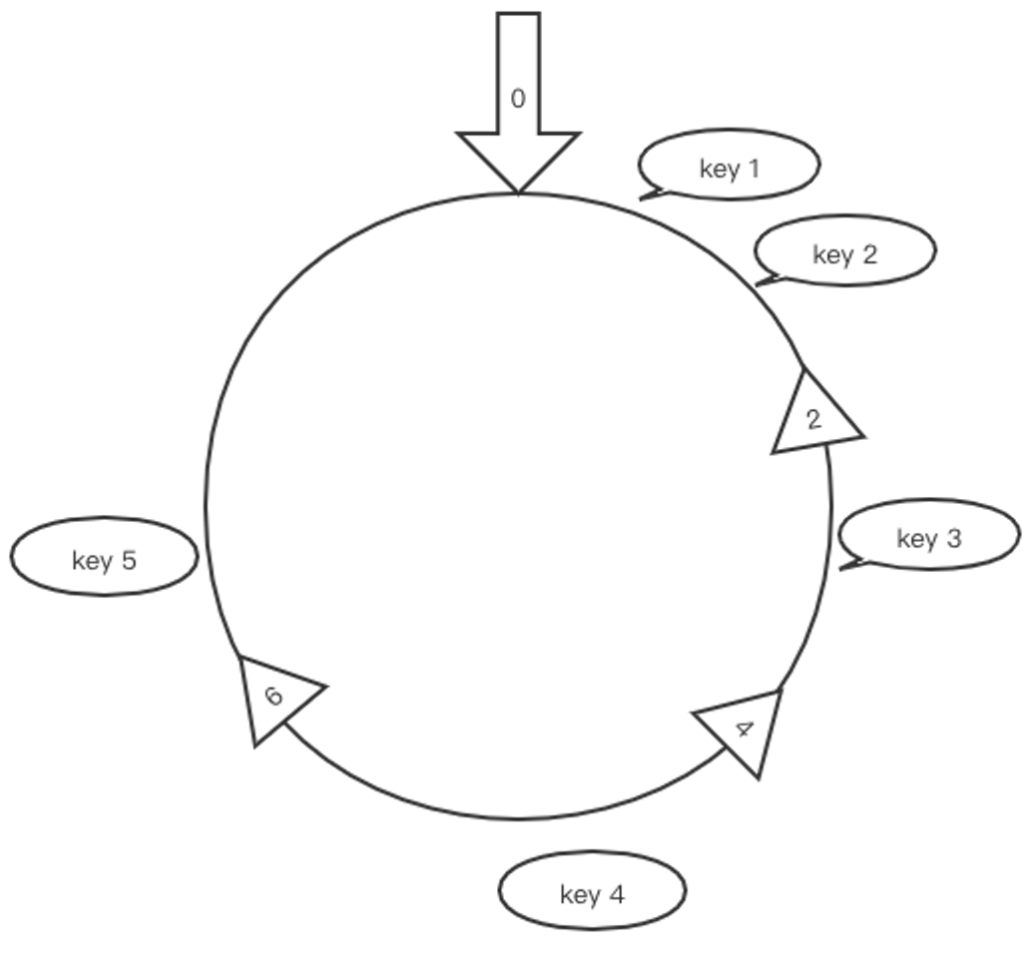
一致性 hash 算法的目的是在节点数量 n 变化时, 使尽可能少的 key 需要进行节点间重新分布。一致性 hash 算法将数据 key 和服务器地址 addr 散列到 2^32 的空间中。
我们将 2^32 个整数首尾相连形成一个环,首先计算服务器地址 addr 的 hash 值放置在环上。然后计算 key 的 hash 值放置在环上,顺时针查找,将数据放在找到的的第一个节点上。
type HashFunc func(data []byte) uint32
type Map struct {
hashFunc HashFunc
replicas int
keys []int // sorted
hashMap map[int]string
}
func New(replicas int, fn HashFunc) *Map {
m := &Map{
replicas: replicas, // 每个物理节点会产生 replicas 个虚拟节点
hashFunc: fn,
hashMap: make(map[int]string), // 虚拟节点 hash 值到物理节点地址的映射
}
if m.hashFunc == nil {
m.hashFunc = crc32.ChecksumIEEE
}
return m
}
func (m *Map) IsEmpty() bool {
return len(m.keys) == 0
}Add方法
func (m *Map) Add(keys ...string) {
for _, key := range keys {
if key == "" {
continue
}
for i := 0; i < m.replicas; i++ {
// 使用 i + key 作为一个虚拟节点,计算虚拟节点的 hash 值
hash := int(m.hashFunc([]byte(strconv.Itoa(i) + key)))
// 将虚拟节点添加到环上
m.keys = append(m.keys, hash)
// 注册虚拟节点到物理节点的映射
m.hashMap[hash] = key
}
}
sort.Ints(m.keys)
}
查找方法
func (m *Map) Get(key string) string {
if m.IsEmpty() {
return ""
}
// 支持根据 key 的 hashtag 来确定分布
partitionKey := getPartitionKey(key)
hash := int(m.hashFunc([]byte(partitionKey)))
// sort.Search 会使用二分查找法搜索 keys 中满足 m.keys[i] >= hash 的最小 i 值
idx := sort.Search(len(m.keys), func(i int) bool { return m.keys[i] >= hash })
// 若 key 的 hash 值大于最后一个虚拟节点的 hash 值,则 sort.Search 找不到目标
// 这种情况下选择第一个虚拟节点
if idx == len(m.keys) {
idx = 0
}
// 将虚拟节点映射为实际地址
return m.hashMap[m.keys[idx]]
}
如何实现集群呢。集群最核心的逻辑是找到 key 所在节点并将指令转发过去
// 集群模式下,除了 MSet、DEL 等特殊指令外,其它指令会交由 defaultFunc 处理
func defaultFunc(cluster *Cluster, c redis.Connection, args [][]byte) redis.Reply {
key := string(args[1])
peer := cluster.peerPicker.Get(key) // 通过一致性 hash 找到节点
return cluster.Relay(peer, c, args)
}
func (cluster *Cluster) Relay(peer string, c redis.Connection, args [][]byte) redis.Reply {
if peer == cluster.self { // 若数据在本地则直接调用数据库引擎
// to self db
return cluster.db.Exec(c, args)
} else {
// 从连接池取一个与目标节点的连接
// 连接池使用 github.com/jolestar/go-commons-pool/v2 实现
peerClient, err := cluster.getPeerClient(peer)
if err != nil {
return reply.MakeErrReply(err.Error())
}
defer func() {
_ = cluster.returnPeerClient(peer, peerClient) // 处理完成后将连接放回连接池
}()
// 将指令发送到目标节点
return peerClient.Send(args)
}
}
func (cluster *Cluster) getPeerClient(peer string) (*client.Client, error) {
connectionFactory, ok := cluster.peerConnection[peer]
if !ok {
return nil, errors.New("connection factory not found")
}
raw, err := connectionFactory.BorrowObject(context.Background())
if err != nil {
return nil, err
}
conn, ok := raw.(*client.Client)
if !ok {
return nil, errors.New("connection factory make wrong type")
}
return conn, nil
}
func (cluster *Cluster) returnPeerClient(peer string, peerClient *client.Client) error {
connectionFactory, ok := cluster.peerConnection[peer]
if !ok {
return errors.New("connection factory not found")
}
return connectionFactory.ReturnObject(context.Background(), peerClient)
}
TCC分布式事务
在上一篇文章中我们使用一致性 hash 算法将缓存中的 key 分散到不同的服务器节点中,从而实现了分布式缓存。随之而来的问题是:一条指令(比如 MSET)可能需要多个节点同时执行,可能有些节点成功而另一部分节点失败。
对于使用者而言这种部分成功部分失败的情况非常难以处理,所以我们需要保证 MSET 操作要么全部成功要么全部失败。
于是问题来了 DEL、MSET 等命令所涉及的 key 可能分布在不同的节点中,在集群模式下实现这类涉及多个 key 的命令最简单的方式当然是 For-Each 遍历 key 并向它们所在的节点发送相应的操作指令。
以 MGET 命令的实现为例:
func MGet(cluster *Cluster, c redis.Connection, args [][]byte) redis.Reply {
if len(args) < 2 {
return reply.MakeErrReply("ERR wrong number of arguments for 'mget' command")
}
// 从参数列表中取出要读取的 key
keys := make([]string, len(args)-1)
for i := 1; i < len(args); i++ {
keys[i-1] = string(args[i])
}
resultMap := make(map[string][]byte)
// 计算每个 key 所在的节点,并按照节点分组
groupMap := cluster.groupBy(keys)
// groupMap 的类型为 map[string][]string,key 是节点的地址,value 是 keys 中属于该节点的 key 列表
for peer, group := range groupMap {
// 向每个节点发送 mget 指令,读取分布在它上面的 key
resp := cluster.Relay(peer, c, makeArgs("MGET", group...))
if reply.IsErrorReply(resp) {
errReply := resp.(reply.ErrorReply)
return reply.MakeErrReply(fmt.Sprintf("ERR during get %s occurs: %v", group[0], errReply.Error()))
}
arrReply, _ := resp.(*reply.MultiBulkReply)
// 将每个节点上的结果 merge 到 map 中
for i, v := range arrReply.Args {
key := group[i]
resultMap[key] = v
}
}
result := make([][]byte, len(keys))
for i, k := range keys {
result[i] = resultMap[k]
}
return reply.MakeMultiBulkReply(result)
}
// 计算 key 所属的节点,并按节点分组
func (cluster *Cluster) groupBy(keys []string) map[string][]string {
result := make(map[string][]string)
for _, key := range keys {
// 使用一致性 hash 计算所属节点
peer := cluster.peerPicker.Get(key)
// 将 key 加入到相应节点的分组中
group, ok := result[peer]
if !ok {
group = make([]string, 0)
}
group = append(group, key)
result[peer] = group
}
return result
}
那么 MSET 命令的实现能否如法炮制呢?答案是否定的。在上面的代码中我们注意到,在向各个节点发送指令时若某个节点读取失败则会直接退出整个 MGET 执行过程。
若在执行 MSET 指令时遇到部分节点失败或超时,则会出现部分 key 设置成功而另一份设置失败的情况。对于缓存使用者而言这种部分成功部分失败的情况非常难以处理,所以我们需要保证 MSET 操作要么全部成功要么全部失败。
两阶段提交
两阶段提交(2-Phase Commit, 2PC)算法是解决我们遇到的一致性问题最简单的算法。在 2PC 算法中写操作被分为两个阶段来执行:
Prepare 阶段
协调者向所有参与者发送事务内容,询问是否可以执行事务操作。在 Godis 中收到客户端 MSET 命令的节点是事务的协调者,所有持有相关 key 的节点都要参与事务。
各参与者锁定事务相关 key 防止被其它操作修改。各参与者写 undo log 准备在事务失败后进行回滚。
参与者回复协调者可以提交。若协调者收到所有参与者的YES回复,则准备进行事务提交。若有参与者回复NO或者超时,则准备回滚事务
Commit 阶段
协调者向所有参与者发送提交请求
参与者正式提交事务,并在完成后释放相关 key 的锁。
参与者协调者回复ACK,协调者收到所有参与者的ACK后认为事务提交成功。
Rollback 阶段
在事务请求阶段若有参与者回复NO或者超时,协调者向所有参与者发出回滚请求
各参与者执行事务回滚,并在完成后释放相关资源。
参与者协调者回复ACK,协调者收到所有参与者的ACK后认为事务回滚成功。
2PC是一种简单的一致性协议,它存在一些问题:
单点服务: 若协调者突然崩溃则事务流程无法继续进行或者造成状态不一致
无法保证一致性: 若协调者第二阶段发送提交请求时崩溃,可能部分参与者受到COMMIT请求提交了事务,而另一部分参与者未受到请求而放弃事务造成不一致现象。
阻塞: 为了保证事务完成提交,各参与者在完成第一阶段事务执行后必须锁定相关资源直到正式提交,影响系统的吞吐量。
事务的结构
事务id由雪花算法生成
type Transaction struct {
id string // 事务 ID, 由协调者使用 snowflake 算法生成
cmdLine CmdLine // 事务要执行命令行
cluster *Cluster
conn redis.Connection
dbIndex int
writeKeys []string // 事务要进行写入的 Key
readKeys []string // 事务要进行读取的 Key
keysLocked bool
undoLog []CmdLine // 回滚命令
status int8
mu *sync.Mutex
}
协调者
func MSet(cluster *Cluster, c redis.Connection, args [][]byte) redis.Reply {
// 解析参数
argCount := len(args) - 1
if argCount%2 != 0 || argCount < 1 {
return reply.MakeErrReply("ERR wrong number of arguments for 'mset' command")
}
size := argCount / 2
keys := make([]string, size)
valueMap := make(map[string]string)
for i := 0; i < size; i++ {
keys[i] = string(args[2*i+1])
valueMap[keys[i]] = string(args[2*i+2])
}
// 找到相关 key 所属的节点
groupMap := cluster.groupBy(keys)
if len(groupMap) == 1 { // do fast
// 若所有的 key 都在同一个节点直接执行,不使用较慢的 2pc 算法
for peer := range groupMap {
return cluster.Relay(peer, c, args)
}
}
// 开始准备阶段
var errReply redis.Reply
txId := cluster.idGenerator.NextId() // 使用 snowflake 算法决定事务 ID
txIdStr := strconv.FormatInt(txId, 10)
rollback := false
// 向所有参与者发送 prepare 请求
for peer, group := range groupMap {
peerArgs := []string{txIdStr}
for _, k := range group {
peerArgs = append(peerArgs, k, valueMap[k])
}
var resp redis.Reply
if peer == cluster.self {
resp = PrepareMSet(cluster, c, makeArgs("PrepareMSet", peerArgs...))
} else {
resp = cluster.Relay(peer, c, makeArgs("PrepareMSet", peerArgs...))
}
if reply.IsErrorReply(resp) {
errReply = resp
rollback = true
break
}
}
if rollback {
// 若 prepare 过程出错则执行回滚
RequestRollback(cluster, c, txId, groupMap)
} else {
// prepare 成功,要求所有节点提交
_, errReply = RequestCommit(cluster, c, txId, groupMap)
rollback = errReply != nil
}
if !rollback {
return &reply.OkReply{}
}
return errReply
}
func requestCommit(cluster *Cluster, c redis.Connection, txID int64, peers map[string][]string) ([]redis.Reply, reply.ErrorReply) {
var errReply reply.ErrorReply
txIDStr := strconv.FormatInt(txID, 10)
respList := make([]redis.Reply, 0, len(peers))
// 要求每个节点进行提交
for peer := range peers {
var resp redis.Reply
if peer == cluster.self {
resp = execCommit(cluster, c, makeArgs("commit", txIDStr))
} else {
resp = cluster.relay(peer, c, makeArgs("commit", txIDStr))
}
if reply.IsErrorReply(resp) {
errReply = resp.(reply.ErrorReply)
break
}
respList = append(respList, resp)
}
// 若有节点提交失败则要求所有节点回滚
if errReply != nil {
requestRollback(cluster, c, txID, peers)
return nil, errReply
}
return respList, nil
}