介绍
本文档旨在尽可能使用 浅显的词语,丰富的图像和实际例子 介绍数字视频概念,使这些知识能适用于各种场合。你可以随时反馈意见或建议,以改进这篇文档。
基本术语
一个 图像 可以视作一个 二维矩阵 。如果将 色彩 考虑进来,我们可以做出推广:将这个图像视作一个 三维矩阵 ——多出来的维度用于储存色彩信息。
如果我们选择三原色(红、绿、蓝)代表这些色彩,这就定义了三个平面:第一个是红色平面,第二个是绿色平面,最后一个是蓝色平面。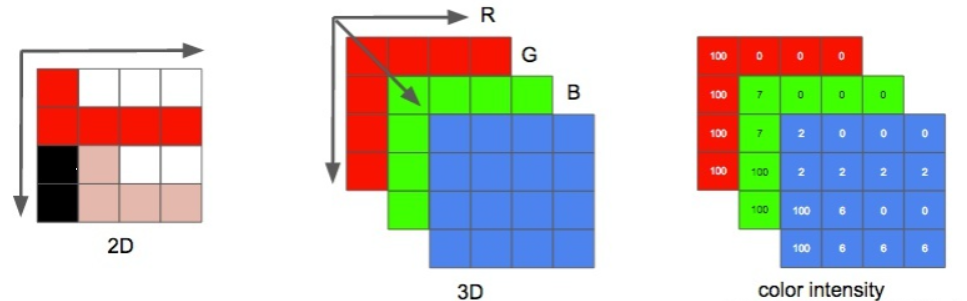 我们把这个矩阵里的每一个点称为 像素 (图像元素)。像素的色彩由三原色的 强度 (通常用数值表示)表示。例如,一个 红色像素 是指强度为 0 的绿色,强度为 0 的蓝色和强度最大的红色。 粉色像素 可以通过三种颜色的组合表示。如果规定强度的取值范围是 0 到 255, 红色 255、绿色 192、蓝色 203 则表示粉色。
我们把这个矩阵里的每一个点称为 像素 (图像元素)。像素的色彩由三原色的 强度 (通常用数值表示)表示。例如,一个 红色像素 是指强度为 0 的绿色,强度为 0 的蓝色和强度最大的红色。 粉色像素 可以通过三种颜色的组合表示。如果规定强度的取值范围是 0 到 255, 红色 255、绿色 192、蓝色 203 则表示粉色。
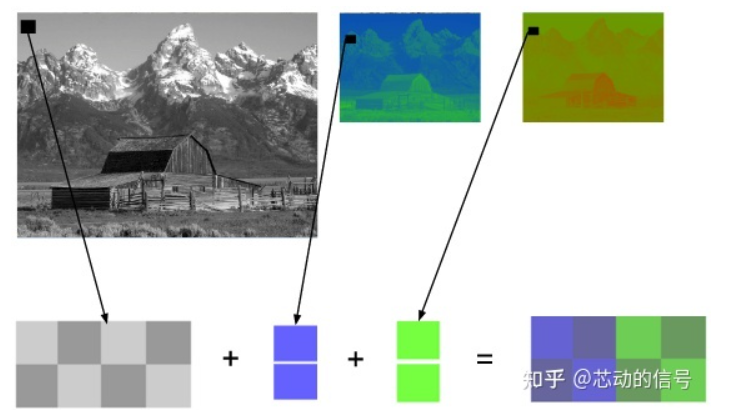
编码彩色图像的其它方法 还有许多其它模型也可以用来表示色彩,进而组成图像。例如,给每种颜色都标上序号(如下图),这样每个像素仅需一个字节就可以表示出来,而不是 RGB 模型通常所需的 3 个。在这样一个模型里我们可以用一个二维矩阵来代替

例如以下几张图片。第一张包含所有颜色平面。剩下的分别是红、绿、蓝色平面(显示为灰调)(译注:颜色强度高的地方显示为亮色,强度低为暗色)。

我们可以看到,对于最终的成像,红色平面对强度的贡献更多(三个平面最亮的是红色平面),蓝色平面(最后一张图片)的贡献大多只在马里奥的眼睛和他衣服的一部分。所有颜色平面对马里奥的胡子(最暗的部分)均贡献较少。
存储颜色的强度,需要占用一定大小的数据空间,这个大小被称为颜色深度。假如每个颜色(平面)的强度占用 8 bit(取值范围为 0 到 255),那么颜色深度就是 24(8*3)bit,我们还可以推导出我们可以使用 2 的 24 次方种不同的颜色。
很棒的学习材料:现实世界的照片是如何拍摄成 0 和 1 的。
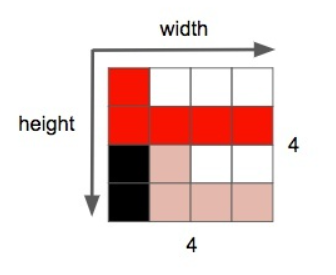
图片的另一个属性是 分辨率 ,即一个平面内像素的数量。通常表示成宽*高,例如下面这张 4x4 的图片。
自己动手:玩转图像和颜色 你可以使用 jupyter(python, numpy, matplotlib 等等)玩转图像。 你也可以学习图像滤镜(边缘检测,锐化,模糊。。。)的原理。
图像或视频还有一个属性是宽高比,它简单地描述了图像或像素的宽度和高度之间的比例关系。
当人们说这个电影或照片是 16:9 时,通常是指显示宽高比(DAR),然而我们也可以有不同形状的单个像素,我们称为像素宽高比(PAR)。


DVD 的 DAR 是 4:3 虽然 DVD 的实际分辨率是 704x480,但它依然保持 4:3 的宽高比,因为它有一个 10:11(704x10/480x11)的 PAR。
现在我们可以将 视频 定义为在 单位时间 内 连续的 n 帧 ,这可以视作一个新的维度,n 即为帧率,若单位时间为秒,则等同于 FPS (每秒帧数 Frames Per Second)。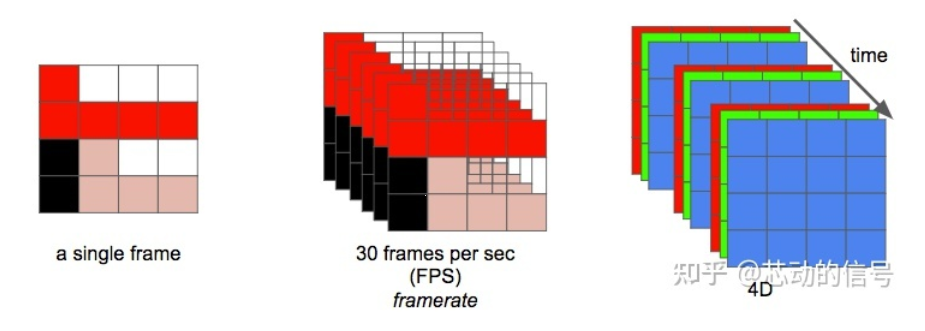 播放一段视频每秒所需的数据量就是它的 比特率 (即常说的码率)。
播放一段视频每秒所需的数据量就是它的 比特率 (即常说的码率)。
比特率 = 宽 高 颜色深度 * 帧每秒
例如,一段每秒 30 帧,每像素 24 bits,分辨率是 480x240 的视频,如果我们不做任何压缩,它将需要 82,944,000 比特每秒 或 82.944 Mbps (30x480x240x24)。
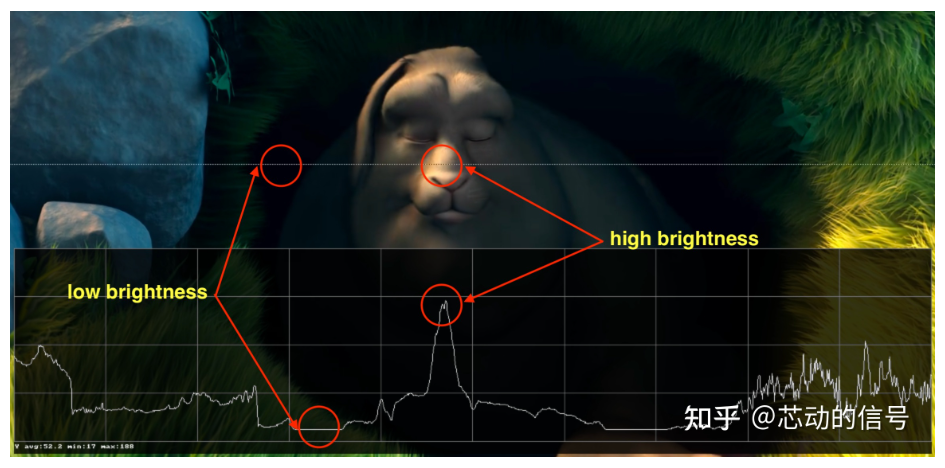
当 比特率 几乎恒定时称为恒定比特率( CBR );但它也可以变化,称为可变比特率( VBR )。
这个图形显示了一个受限的 VBR,当帧为黑色时不会花费太多的数据量。
 在早期,工程师们想出了一项技术能将视频的感官帧率加倍而 没有消耗额外带宽 。这项技术被称为 隔行扫描 ;总的来说,它在一个时间点发送一个画面——画面用于填充屏幕的一半,而下一个时间点发送的画面用于填充屏幕的另一半。
在早期,工程师们想出了一项技术能将视频的感官帧率加倍而 没有消耗额外带宽 。这项技术被称为 隔行扫描 ;总的来说,它在一个时间点发送一个画面——画面用于填充屏幕的一半,而下一个时间点发送的画面用于填充屏幕的另一半。
如今的屏幕渲染大多使用 逐行扫描技术 。这是一种显示、存储、传输运动图像的方法,每帧中的所有行都会被依次绘制。
 现在我们知道了数字化 图像 的原理;它的 颜色 的编排方式;给定 帧率 和 分辨率 时,展示一个视频需要花费多少 比特率 ;它是恒定的(CBR)还是可变的(VBR);还有很多其它内容,如隔行扫描和 PAR。
现在我们知道了数字化 图像 的原理;它的 颜色 的编排方式;给定 帧率 和 分辨率 时,展示一个视频需要花费多少 比特率 ;它是恒定的(CBR)还是可变的(VBR);还有很多其它内容,如隔行扫描和 PAR。
自己动手:检查视频属性 你可以使用 ffmpeg 或 mediainfo 检查大多数属性的解释。
消除冗余
我们认识到,不对视频进行压缩是不行的; 一个单独的一小时长的视频 ,分辨率为 720p 和 30fps 时将 需要 278GB* 。仅仅使用无损数据压缩算法——如 DEFLATE(被PKZIP, Gzip, 和 PNG 使用)——也无法充分减少视频所需的带宽,我们需要找到其它压缩视频的方法。
*我们使用乘积得出这个数字 1280 x 720 x 24 x 30 x 3600 (宽,高,每像素比特数,fps 和秒数)
为此,我们可以 利用视觉特性 :和区分颜色相比,我们区分亮度要更加敏锐。 时间上的重复 :一段视频包含很多只有一点小小改变的图像。 图像内的重复 :每一帧也包含很多颜色相同或相似的区域。
颜色,亮度和我们的眼睛
我们的眼睛对亮度比对颜色更敏感,你可以看看下面的图片自己测试。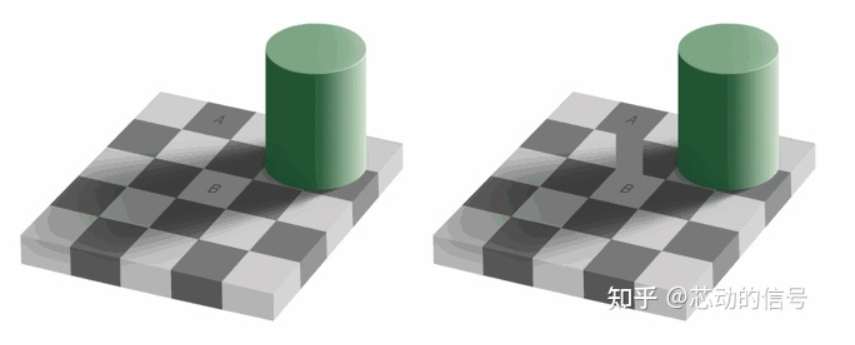 如果你看不出左图的 方块 A 和方块 B 的颜色是 相同的 ,那么好,是我们的大脑玩了一个小把戏,这让我们更多的去注意光与暗,而不是颜色。右边这里有一个使用同样颜色的连接器,那么我们(的大脑)就能轻易分辨出事实,它们是同样的颜色。
如果你看不出左图的 方块 A 和方块 B 的颜色是 相同的 ,那么好,是我们的大脑玩了一个小把戏,这让我们更多的去注意光与暗,而不是颜色。右边这里有一个使用同样颜色的连接器,那么我们(的大脑)就能轻易分辨出事实,它们是同样的颜色。
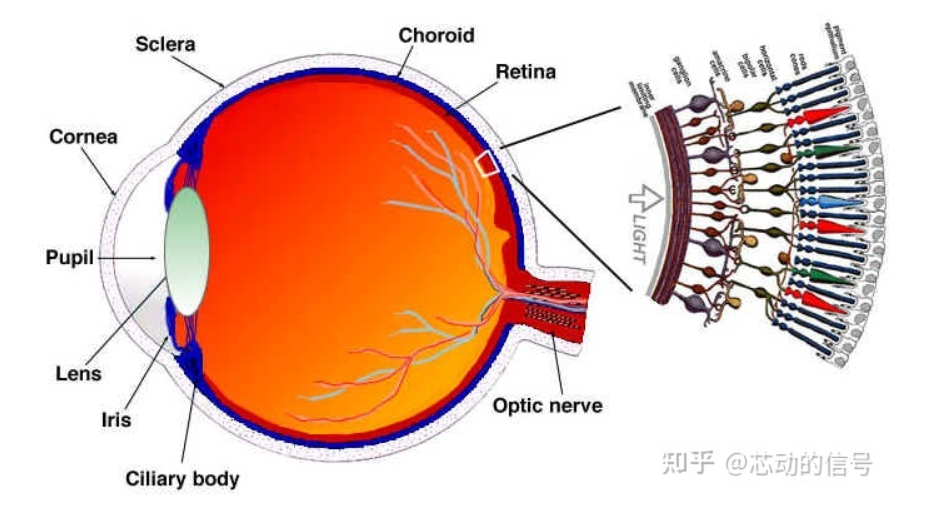
简单解释我们的眼睛工作的原理 眼睛是一个复杂的器官,有许多部分组成,但我们最感兴趣的是视锥细胞和视杆细胞。眼睛有大约1.2亿个视杆细胞和6百万个视锥细胞。 简单来说 ,让我们把颜色和亮度放在眼睛的功能部位上。视杆细胞 主要负责亮度 ,而视锥细胞 负责颜色 ,有三种类型的视锥,每个都有不同的颜料,叫做:S-视锥(蓝色),M-视锥(绿色)和L-视锥(红色)。 既然我们的视杆细胞(亮度)比视锥细胞多很多,一个合理的推断是相比颜色,我们有更好的能力去区分黑暗和光亮。
 一旦我们知道我们对 亮度 (图像中的亮度)更敏感,我们就可以利用它。
一旦我们知道我们对 亮度 (图像中的亮度)更敏感,我们就可以利用它。
颜色模型
我们最开始学习的彩色图像的原理使用的是 RGB 模型 ,但也有其他模型。有一种模型将亮度(光亮)和色度(颜色)分离开,它被称为 YCbCr *。
有很多种模型做同样的分离。
这个颜色模型使用 Y 来表示亮度,还有两种颜色通道:Cb(蓝色色度) 和 Cr(红色色度)。YCbCr 可以由 RGB 转换得来,也可以转换回 RGB。使用这个模型我们可以创建拥有完整色彩的图像,如下图。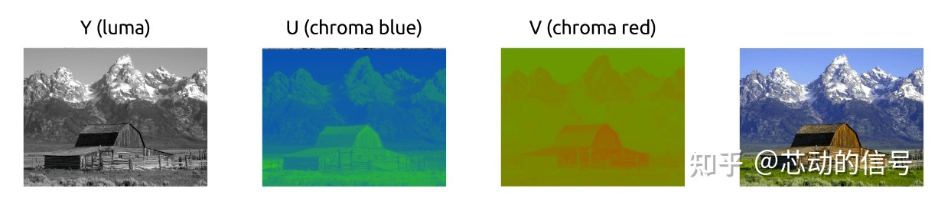
YCbCr 和 RGB 之间的转换
有人可能会问,在 不使用绿色(色度) 的情况下,我们如何表现出所有的色彩?
为了回答这个问题,我们将介绍从 RGB 到 YCbCr 的转换。我们将使用 ITU-R 小组*建议的标准 BT.601 中的系数。
第一步是计算亮度,我们将使用 ITU 建议的常量,并替换 RGB 值。Y = 0.299R + 0.587G + 0.114B
一旦我们有了亮度后,我们就可以拆分颜色(蓝色色度和红色色度):
Cb = 0.564(B - Y)
Cr = 0.713(R - Y)
并且我们也可以使用 YCbCr 转换回来,甚至得到绿色。
R = Y + 1.402Cr
B = Y + 1.772Cb
G = Y - 0.344Cb - 0.714Cr
*组织和标准在数字视频领域中很常见,它们通常定义什么是标准,例如,什么是 4K?我们应该使用什么帧率?分辨率?颜色模型?
通常, 显示屏 (监视器,电视机,屏幕等等) 仅使用 RGB 模型 ,并以不同的方式来组织,看看下面这些放大效果:

色度子采样
一旦我们能从图像中分离出亮度和色度,我们就可以利用人类视觉系统对亮度比色度更敏感的特点,选择性地剔除信息。 色度子采样 是一种编码图像时,使 色度分辨率低于亮度 的技术。
我们应该减少多少色度分辨率呢?已经有一些模式定义了如何处理分辨率和合并( 最终的颜色 = Y + Cb + Cr )。
这些模式称为子采样系统,并被表示为 3 部分的比率 - a:x:y ,其定义了色度平面的分辨率,与亮度平面上的、分辨率为 a x 2 的小块之间的关系。
a是水平采样参考 (通常是 4),x是第一行的色度样本数(相对于 a 的水平分辨率),y是第二行的色度样本数。
存在的一个例外是 4:1:0,其在每个亮度平面分辨率为 4 x 4 的块内提供一个色度样本。
现代编解码器中使用的常用方案是: 4:4:4 (没有子采样), 4:2:2, 4:1:1, 4:2:0, 4:1:0 and 3:1:1。
YCbCr 4:2:0 合并 这是使用 YCbCr 4:2:0 合并的一个图像的一块,注意我们每像素只花费 12bit。
下图是同一张图片使用几种主要的色度子采样技术进行编码,第一行图像是最终的 YCbCr,而最后一行图像展示了色度的分辨率。这么小的损失确实是一个伟大的胜利。
 前面我们计算过我们需要 278GB 去存储一个一小时长,分辨率在720p和30fps的视频文件。如果我们使用
前面我们计算过我们需要 278GB 去存储一个一小时长,分辨率在720p和30fps的视频文件。如果我们使用 YCbCr 4:2:0 我们能减少 一半的大小(139GB) *,但仍然不够理想。
我们通过将宽、高、颜色深度和 fps 相乘得出这个值。前面我们需要 24 bit,现在我们只需要 12 bit。 自己动手:检查 YCbCr 直方图 你可以使用 ffmpeg 检查 YCbCr 直方图。这个场景有更多的蓝色贡献,由直方图显示。
 颜色, 亮度, 视频亮度, 伽马 视频回顾
颜色, 亮度, 视频亮度, 伽马 视频回顾
观看这段精彩的视频,它解释什么是亮度并了解视频亮度、伽马和颜色。
自己动手: 检查 YCbCr 强度 你可以使用FFmpeg's oscilloscope滤镜可视化给定视频行的Y强度. ffplay -f lavfi -i 'testsrc2=size=1280x720:rate=30000/1001,format=yuv420p' -vf oscilloscope=x=0.5:y=200/720:s=1:c=1
帧类型
现在我们进一步消除 时间冗余 ,但在这之前让我们来确定一些基本术语。假设我们一段 30fps 的影片,这是最开始的 4 帧。

我们可以在帧内看到 很多重复内容 ,如 蓝色背景 ,从 0 帧到第 3 帧它都没有变化。为了解决这个问题,我们可以将它们 抽象地分类 为三种类型的帧。
I 帧(帧内,关键帧)
I 帧(可参考,关键帧,帧内编码)是一个 自足的帧 。它不依靠任何东西来渲染,I 帧与静态图片相似。第一帧通常是 I 帧,但我们将看到 I 帧被定期插入其它类型的帧之间。

P 帧(预测)
P 帧利用了一个事实:当前的画面几乎总能 使用之前的一帧进行渲染 。例如,在第二帧,唯一的改变是球向前移动了。仅仅使用(第二帧)对前一帧的引用和差值,我们就能重建前一帧。 自己动手:具有单个 I 帧的视频 既然 P 帧使用较少的数据,为什么我们不能用单个 I 帧和其余的 P 帧来编码整个视频? 编码完这个视频之后,开始观看它,并 快进到视频的末尾部分 ,你会注意到 它需要花一些时间 才真正跳转到这部分。这是因为 P 帧需要一个引用帧 (比如 I 帧)才能渲染。 你可以做的另一个快速试验,是使用单个 I 帧编码视频,然后再次编码且每 2 秒插入一个 I 帧,并 比较成品的大小 。
自己动手:具有单个 I 帧的视频 既然 P 帧使用较少的数据,为什么我们不能用单个 I 帧和其余的 P 帧来编码整个视频? 编码完这个视频之后,开始观看它,并 快进到视频的末尾部分 ,你会注意到 它需要花一些时间 才真正跳转到这部分。这是因为 P 帧需要一个引用帧 (比如 I 帧)才能渲染。 你可以做的另一个快速试验,是使用单个 I 帧编码视频,然后再次编码且每 2 秒插入一个 I 帧,并 比较成品的大小 。
B 帧(双向预测)
如何引用前面和后面的帧去做更好的压缩?!简单地说 B 帧就是这么做的。
自己动手:使用 B 帧比较视频 你可以生成两个版本,一个使用 B 帧,另一个全部不使用 B 帧,然后查看文件的大小以及画质。
小结
这些帧类型用于提供更好的压缩率,我们将在下一章看到这是如何发生的。现在,我们可以想到 I 帧是昂贵的,P 帧是便宜的,最便宜的是 B 帧。 时间冗余(帧间预测)
时间冗余(帧间预测)
让我们探究去除 时间上的重复 ,去除这一类冗余的技术就是 帧间预测 。
我们将尝试 花费较少的数据量 去编码在时间上连续的 0 号帧和 1 号帧。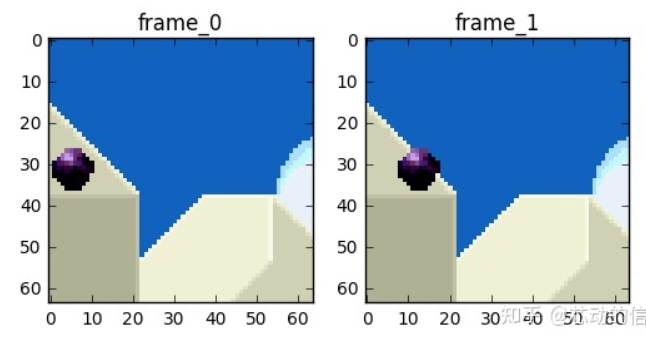
我们可以做个减法,我们简单地 用 0 号帧减去 1 号帧 ,得到残差,这样我们就只需要 对残差进行编码 。
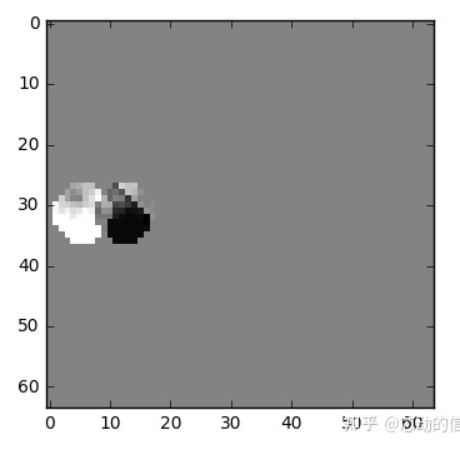
但我们有一个 更好的方法 来节省数据量。首先,我们将 0 号帧 视为一个个分块的集合,然后我们将尝试将 帧 1 和 帧 0 上的块相匹配。我们可以将这看作是 运动预测 。
维基百科—块运动补偿 “运动补偿是一种描述相邻帧(相邻在这里表示在编码关系上相邻,在播放顺序上两帧未必相邻)差别的方法,具体来说是描述前面一帧(相邻在这里表示在编码关系上的前面,在播放顺序上未必在当前帧前面)的每个小块怎样移动到当前帧中的某个位置去。”
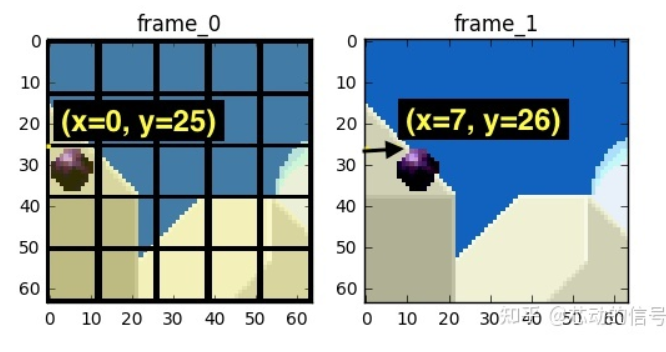
我们预计那个球会从 x=0, y=25 移动到 x=6, y=26 , x 和 y 的值就是 运动向量 。 进一步 节省数据量的方法是,只编码这两者运动向量的差。所以,最终运动向量就是 x=6 (6-0), y=1 (26-25) 。
实际情况下,这个球会被切成 n 个分区,但处理过程是相同的。
帧上的物体 以三维方式移动 ,当球移动到背景时会变小。当我们尝试寻找匹配的块, 找不到完美匹配的块 是正常的。这是一张运动预测与实际值相叠加的图片。
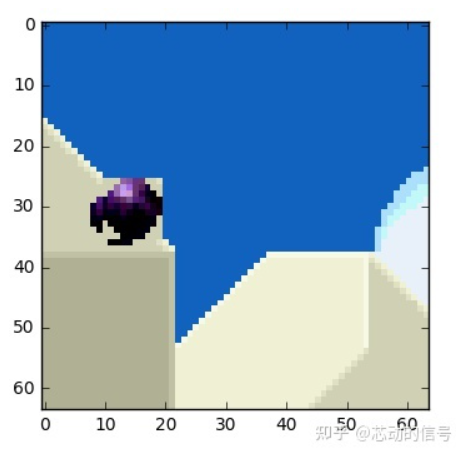
但我们能看到当我们使用 运动预测 时, 编码的数据量少于 使用简单的残差帧技术。

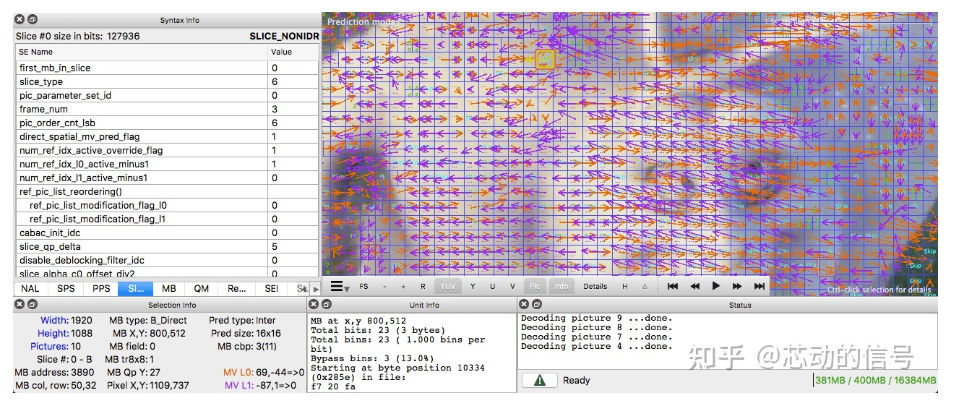
自己动手:查看运动向量 我们可以使用 ffmpeg 生成包含帧间预测(运动向量)的视频

或者我们也可使用 Intel® Video Pro Analyzer(需要付费,但也有只能查看前 10 帧的免费试用版)。