InnoDB 是如何存储数据的?
记录是按照行来存储的,但是数据库的读取并不以「行」为单位,否则一次读取(也就是一次 I/O 操作)只能处理一行数据,效率会非常低。
因此,InnoDB 的数据是按「数据页」为单位来读写的,也就是说,当需要读一条记录的时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。
数据库的 I/O 操作的最小单位是页,InnoDB 数据页的默认大小是 16KB,意味着数据库每次读写都是以 16KB 为单位的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16K 内容刷新到磁盘中。
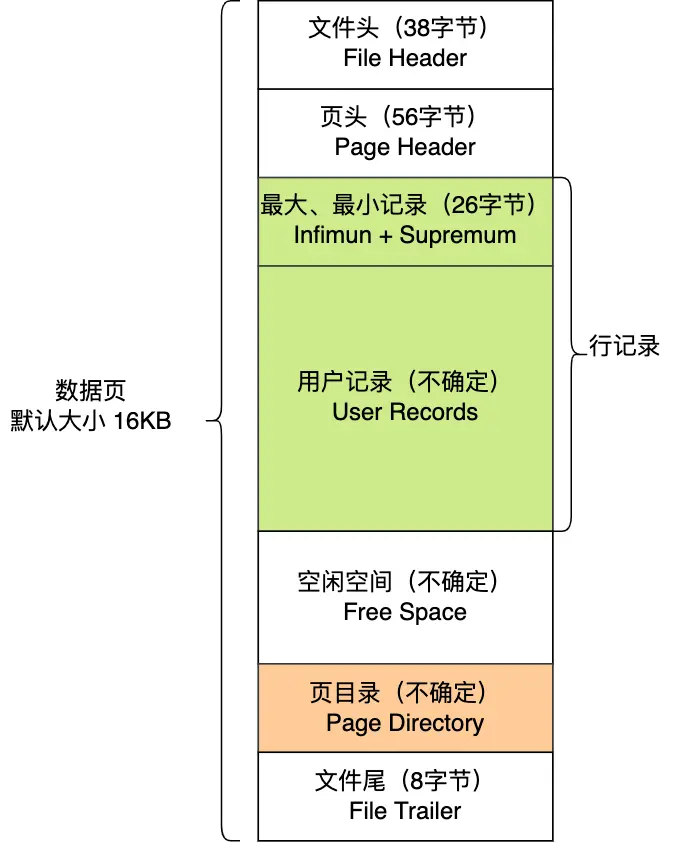
文件头表示页的信息;页头表页的状态信息;最小最大记录;用户记录存储行记录内容;空闲空间存储页中没被使用的空间;页目录存储用户记录的相对位置,对记录索引;文件尾用来校验页完整性
在 File Header 中有两个指针,分别指向上一个数据页和下一个数据页;连接起来的页相当于一个双向的链表。采用链表的结构是让数据页之间不需要是物理上的连续的,而是逻辑上的连续。
数据页的主要作用是存储记录,也就是数据库的数据,所以重点说一下数据页中的 User Records 是怎么组织数据的。
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
因此,数据页中有一个页目录,起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。
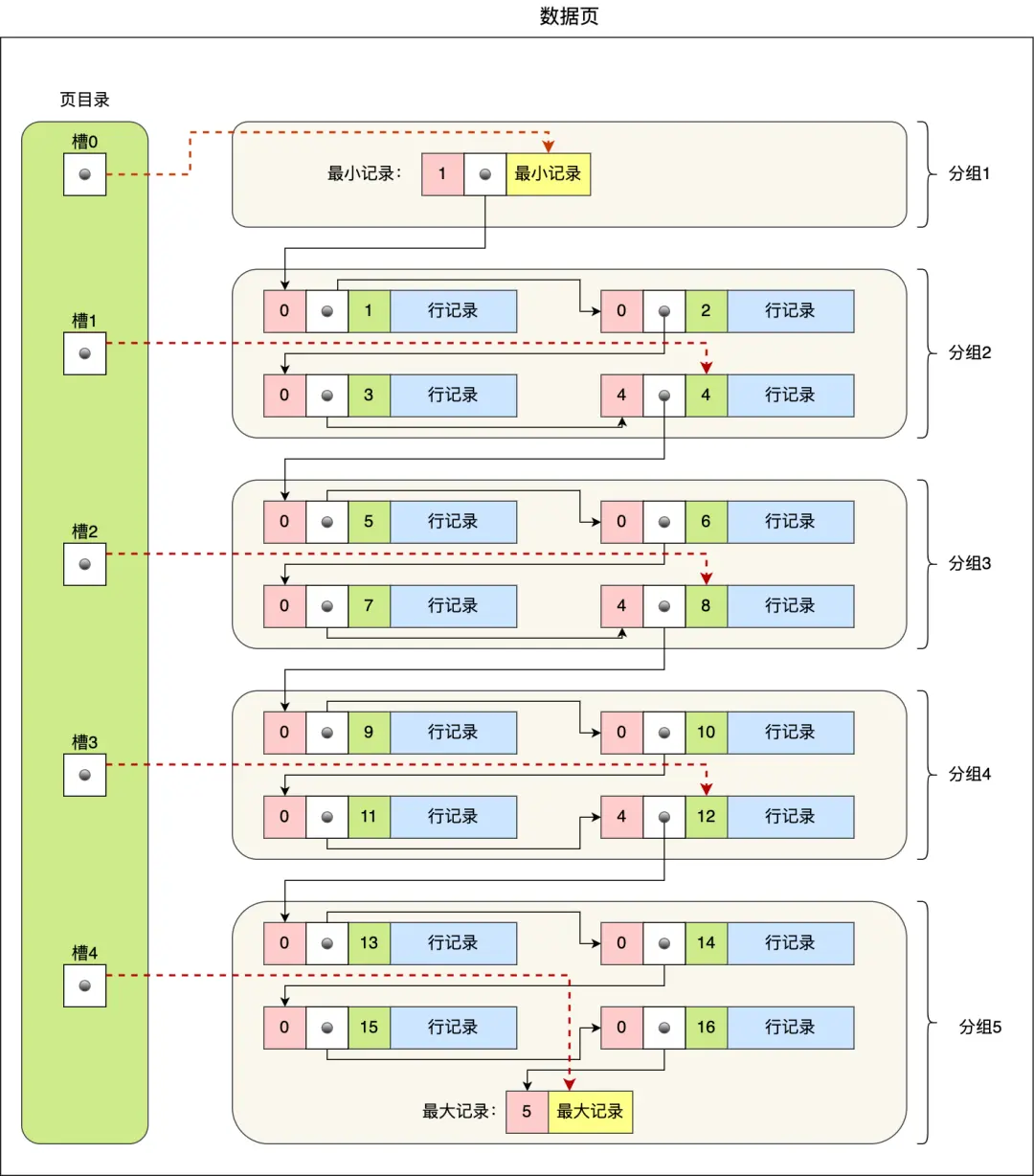
页目录创建的过程如下:
- 将所有的记录划分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录;
- 每个记录组的最后一条记录就是组内最大的那条记录,并且最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段(上图中粉红色字段)
- 页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
从图可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照「主键值」从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。
以上面那张图举个例子,5 个槽的编号分别为 0,1,2,3,4,我想查找主键为 11 的用户记录:
- 先二分得出槽中间位是 (0+4)/2=2 ,2号槽里最大的记录为 8。因为 11 > 8,所以需要从 2 号槽后继续搜索记录;
- 再使用二分搜索出 2 号和 4 槽的中间位是 (2+4)/2= 3,3 号槽里最大的记录为 12。因为 11 < 12,所以主键为 11 的记录在 3 号槽里;
- 这里有个问题,「槽对应的值都是这个组的主键最大的记录,如何找到组里最小的记录」?比如槽 3 对应最大主键是 12 的记录,那如何找到最小记录 9。解决办法是:通过槽 3 找到 槽 2 对应的记录,也就是主键为 8 的记录。主键为 8 的记录的下一条记录就是槽 3 当中主键最小的 9 记录,然后开始向下搜索 2 次,定位到主键为 11 的记录,取出该条记录的信息即为我们想要查找的内容。
看到第三步的时候,可能有的同学会疑问,如果某个槽内的记录很多,然后因为记录都是单向链表串起来的,那这样在槽内查找某个记录的时间复杂度不就是 O(n) 了吗?
这点不用担心,InnoDB 对每个分组中的记录条数都是有规定的,槽内的记录就只有几条:
- 第一个分组中的记录只能有 1 条记录;
- 最后一个分组中的记录条数范围只能在 1-8 条之间;
- 剩下的分组中记录条数范围只能在 4-8 条之间。
B+ 树是如何进行查询的?
当我们需要存储大量的记录时,就需要多个数据页,这时我们就需要考虑如何建立合适的索引,才能方便定位记录所在的页。
为了解决这个问题,InnoDB 采用了 B+ 树作为索引。磁盘的 I/O 操作次数对索引的使用效率至关重要,因此在构造索引的时候,我们更倾向于采用“矮胖”的 B+ 树数据结构,这样所需要进行的磁盘 I/O 次数更少,而且 B+ 树 更适合进行关键字的范围查询。
InnoDB 里的 B+ 树中的每个节点都是一个数据页,结构示意图如下:
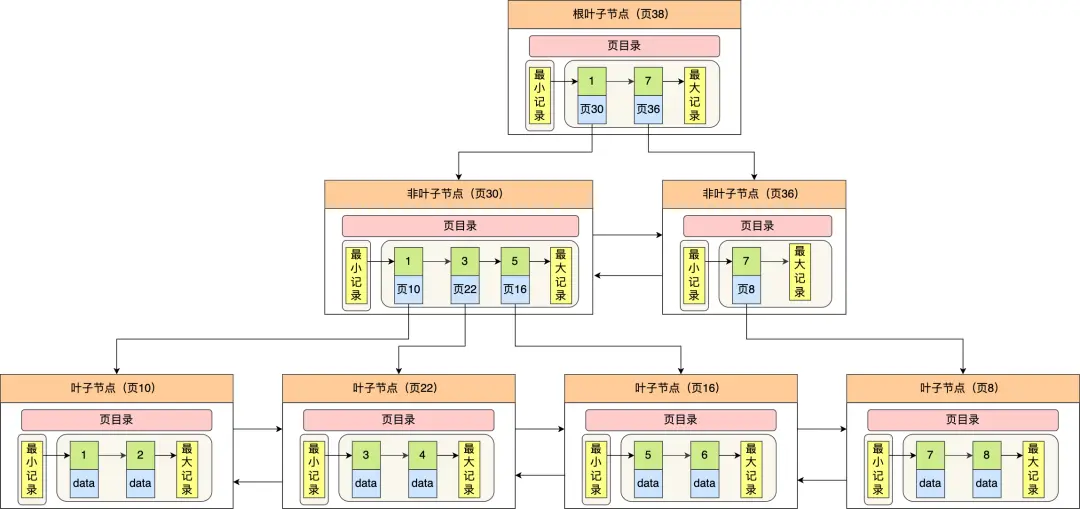
- 只有叶子节点(最底层的节点)才存放了数据,非叶子节点(其他上层节)仅用来存放目录项作为索引。
- 非叶子节点分为不同层次,通过分层来降低每一层的搜索量;
- 所有节点按照索引键大小排序,构成一个双向链表,便于范围查询;
我们再看看 B+ 树如何实现快速查找主键为 6 的记录,以上图为例子:
- 从根节点开始,通过二分法快速定位到符合页内范围包含查询值的页,因为查询的主键值为 6,在[1, 7)范围之间,所以到页 30 中查找更详细的目录项;
- 在非叶子节点(页30)中,继续通过二分法快速定位到符合页内范围包含查询值的页,主键值大于 5,所以就到叶子节点(页16)查找记录;
- 接着,在叶子节点(页16)中,通过槽查找记录时,使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到主键为 6 的记录。
可以看到,在定位记录所在哪一个页时,也是通过二分法快速定位到包含该记录的页。定位到该页后,又会在该页内进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找。
聚簇索引和二级索引
索引又可以分成聚簇索引和非聚簇索引(二级索引),它们区别就在于叶子节点存放的是什么数据:
- 聚簇索引的叶子节点存放的是实际数据,所有完整的用户记录都存放在聚簇索引的叶子节点;
- 二级索引的叶子节点存放的是主键值,而不是实际数据。
因为表的数据都是存放在聚簇索引的叶子节点里,所以 InnoDB 存储引擎一定会为表创建一个聚簇索引,且由于数据在物理上只会保存一份,所以聚簇索引只能有一个。
InnoDB 在创建聚簇索引时,会根据不同的场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键;
- 如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键;
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键;
一张表只能有一个聚簇索引,那为了实现非主键字段的快速搜索,就引出了二级索引(非聚簇索引/辅助索引),它也是利用了 B+ 树的数据结构,但是二级索引的叶子节点存放的是主键值,不是实际数据。
二级索引的 B+ 树如下图,数据部分为主键值:
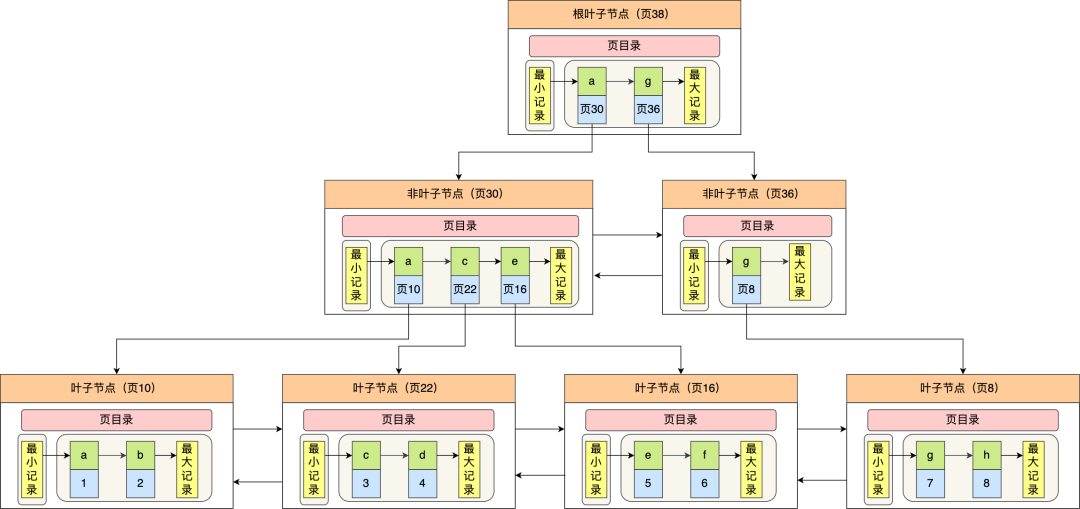
因此,如果某个查询语句使用了二级索引,但是查询的数据不是主键值,这时在二级索引找到主键值后,需要去聚簇索引中获得数据行,这个过程就叫作「回表」,也就是说要查两个 B+ 树才能查到数据。不过,当查询的数据是主键值时,因为只在二级索引就能查询到,不用再去聚簇索引查,这个过程就叫作「索引覆盖」,也就是只需要查一个 B+ 树就能找到数据
比较B+和B树
B+ 树与 B 树差异的点,主要是以下这几点:
- 叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引;
- 所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
- 非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。
- 非叶子节点中有多少个子节点,就有多少个索引;
- 单点查询
B 树进行单个索引查询时,最快可以在 O(1) 的时间代价内就查到,而从平均时间代价来看,会比 B+ 树稍快一些。但是 B 树的查询波动会比较大,因为每个节点即存索引又存记录,所以有时候访问到了非叶子节点就可以找到索引,而有时需要访问到叶子节点才能找到索引。
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。
- 插入删除
B+ 树有大量的冗余节点,这样使得删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点,这样删除非常快,而B树没有,删除节点涉及复杂的树的变形
- 范围查询
B 树和 B+ 树等值查询原理基本一致,先从根节点查找,然后对比目标数据的范围,最后递归的进入子节点查找。
因为 B+ 树所有叶子节点间还有一个链表进行连接,这种设计对范围查找非常有帮助,比如说我们想知道 12 月 1 日和 12 月 12 日之间的订单,这个时候可以先查找到 12 月 1 日所在的叶子节点,然后利用链表向右遍历,直到找到 12 月12 日的节点,这样就不需要从根节点查询了,进一步节省查询需要的时间。
而 B 树没有将所有叶子节点用链表串联起来的结构,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
因此,存在大量范围检索的场景,适合使用 B+树,比如数据库。而对于大量的单个索引查询的场景,可以考虑 B 树,比如 nosql 的MongoDB
单表2000w数据限制
假设有:
- 非叶子节点内指向其他页的数量为 x
- 叶子节点内能容纳的数据行数为 y
- B+ 数的层数为 z
*Total =x^(z-1) y 也就是说总数会等于 x 的 z-1 次方 与 Y 的乘积。
在文章的开头已经介绍了页的结构,索引也也不例外,都会有 File Header (38 byte)、Page Header (56 Byte)、Infimum + Supermum(26 byte)、File Trailer(8byte), 再加上页目录,大概 1k 左右。
我们就当做它就是 1K, 那整个页的大小是 16K, 剩下 15k 用于存数据,在索引页中主要记录的是主键与页号,主键我们假设是 Bigint (8 byte), 而页号也是固定的(4Byte), 那么索引页中的一条数据也就是 12byte。
所以 x=15*1024/12≈1280 行。
叶子节点和非叶子节点的结构是一样的,同理,能放数据的空间也是 15k。
但是叶子节点中存放的是真正的行数据,这个影响的因素就会多很多,比如,字段的类型,字段的数量。每行数据占用空间越大,页中所放的行数量就会越少。
这边我们暂时按一条行数据 1k 来算,那一页就能存下 15 条,Y = 15*1024/1000 ≈15。
算到这边了,是不是心里已经有谱了啊。
根据上述的公式,Total =x^(z-1) *y,已知 x=1280,y=15:
- 假设 B+ 树是两层,那就是 z = 2, Total = (1280 ^1 )*15 = 19200
- 假设 B+ 树是三层,那就是 z = 3, Total = (1280 ^2) *15 = 24576000 (约 2.45kw)
这不是正好就是文章开头说的最大行数建议值 2000W 嘛!一般 B+ 数的层级最多也就是 3 层。如果是 4 层,除了查询的时候磁盘 IO 次数会增加,而且这个 Total 值会是多少,大概应该是 3 百多亿吧,也不太合理,所以,3 层应该是比较合理的一个值。
刚刚在说 Y 的值时候假设的是 1K ,那比如我实际当行的数据占用空间不是 1K , 而是 5K, 那么单个数据页最多只能放下 3 条数据。
同样,还是按照 z = 3 的值来计算,那 Total = (1280 ^2) *3 = 4915200 (近 500w)
所以,在保持相同的层级(相似查询性能)的情况下,在行数据大小不同的情况下,其实这个最大建议值也是不同的,而且影响查询性能的还有很多其他因素,比如,数据库版本,服务器配置,sql 的编写等等。
MySQL 为了提高性能,会将表的索引装载到内存中,在 InnoDB buffer size 足够的情况下,其能完成全加载进内存,查询不会有问题。
但是,当单表数据库到达某个量级的上限时,导致内存无法存储其索引,使得之后的 SQL 查询会产生磁盘 IO,从而导致性能下降,所以增加硬件配置(比如把内存当磁盘使),可能会带来立竿见影的性能提升哈。
索引结构不会影响单表最大行数,2000W 也只是推荐值,超过了这个值可能会导致 B + 树层级更高,影响查询性能。
count(*)和count(1)区别

count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个。
select count(name) from t_order;
这条语句是统计「 t_order 表中,name 字段不为 NULL 的记录」有多少个。也就是说,如果某一条记录中的 name 字段的值为 NULL,则就不会被统计进去。
select count(1) from t_order;
1 这个表达式就是单纯数字,它永远都不是 NULL,所以上面这条语句,其实是在统计 t_order 表中有多少个记录。
count(主键字段)
//id 为主键值
select count(id) from t_order;
在通过 count 函数统计有多少个主键记录时,MySQL 的 server 层会维护一个名叫 count 的变量。
server 层会循环向 InnoDB 读取一条记录,如果 count 函数指定的参数不为 NULL,那么就会将变量 count 加 1,直到符合查询的全部记录被读完,就退出循环。最后将 count 变量的值发送给客户端。
InnoDB 是通过 B+ 树来保存记录的,根据索引的类型又分为聚簇索引和二级索引,它们区别在于,聚簇索引的叶子节点存放的是实际数据,而二级索引的叶子节点存放的是主键值,而不是实际数据。
如果表里只有主键索引,没有二级索引时,那么,InnoDB 循环遍历聚簇索引,将读取到的记录返回给 server 层,然后读取记录中的 id 值,就会 id 值判断是否为 NULL,如果不为 NULL,就将 count 变量加 1。
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就不是聚簇索引,而是二级索引。这是因为相同数量的二级索引记录可以比聚簇索引记录占用更少的存储空间,所以二级索引树比聚簇索引树小,这样遍历二级索引的 I/O 成本比遍历聚簇索引的 I/O 成本小,因此「优化器」优先选择的是二级索引。
count(1) 执行过程是怎样的?
如果表里只有主键索引,没有二级索引时。那么,InnoDB 循环遍历聚簇索引(主键索引),将读取到的记录返回给 server 层,但是不会读取记录中的任何字段的值,因为 count 函数的参数是 1,不是字段,所以不需要读取记录中的字段值。参数 1 很明显并不是 NULL,因此 server 层每从 InnoDB 读取到一条记录,就将 count 变量加 1。
可以看到,count(1) 相比 count(主键字段) 少一个步骤,就是不需要读取记录中的字段值,所以通常会说 count(1) 执行效率会比 count(主键字段) 高一点。
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就二级索引了。
count(*)执行过程?
count(\*) 其实等于 count(0),也就是说,当你使用 count(*) 时,MySQL 会将 * 参数转化为参数 0 来处理。所以,count(*) 执行过程跟 count(1) 执行过程基本一样的,性能没有什么差异。
而且 MySQL 会对 count(*) 和 count(1) 有个优化,如果有多个二级索引的时候,优化器会使用key_len 最小的二级索引进行扫描。
count(字段) 执行过程?
count(字段) 的执行效率相比前面的 count(1)、 count(*)、 count(主键字段) 执行效率是最差的。
对于这个查询来说,会采用全表扫描的方式来计数,所以它的执行效率是比较差的。
使用 MyISAM 引擎时,执行 count 函数只需要 O(1 )复杂度,这是因为每张 MyISAM 的数据表都有一个 meta 信息有存储了row_count值,由表级锁保证一致性,所以直接读取 row_count 值就是 count 函数的执行结果。
而 InnoDB 存储引擎是支持事务的,同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的,所以无法像 MyISAM一样,只维护一个 row_count 变量。
如何优化 count(*)?
1.近似值
show table status 或者 explain 命令来表进行估算
前者是定期更新的;explain通过索引基数、表行数和查询条件的选择性
2.额外表保存计数值
我们可以将这个计数值保存到单独的一张计数表中。
当我们在数据表插入一条记录的同时,将计数表中的计数字段 + 1。也就是说,在新增和删除操作时,我们需要额外维护这个计数表。