创建型模式
1 简单工厂模式
如果没有工厂模式,在开发者创建一个类的对象时,如果有很多不同种类的对象将会如何实现,代码如下:
package main
import "fmt"
//水果类
type Fruit struct {
//...
//...
//...
}
func (f *Fruit) Show(name string) {
if name == "apple" {
fmt.Println("我是苹果")
} else if name == "banana" {
fmt.Println("我是香蕉")
} else if name == "pear" {
fmt.Println("我是梨")
}
}
//创建一个Fruit对象
func NewFruit(name string) *Fruit {
fruit := new(Fruit)
if name == "apple" {
//创建apple逻辑
} else if name == "banana" {
//创建banana逻辑
} else if name == "pear" {
//创建pear逻辑
}
return fruit
}
func main() {
apple := NewFruit("apple")
apple.Show("apple")
banana := NewFruit("banana")
banana.Show("banana")
pear := NewFruit("pear")
pear.Show("pear")
}
不难看出,Fruit类是一个“巨大的”类,在该类的设计中存在如下几个问题:
(1) 在Fruit类中包含很多“if…else…”代码块,整个类的代码相当冗长,代码越长,阅读难度、维护难度和测试难度也越大;而且大量条件语句的存在还将影响系统的性能,程序在执行过程中需要做大量的条件判断。
(2) Fruit类的职责过重,它负责初始化和显示所有的水果对象,将各种水果对象的初始化代码和显示代码集中在一个类中实现,违反了“单一职责原则”,不利于类的重用和维护;
(3) 当需要增加新类型的水果时,必须**修改Fruit类的构造函数NewFruit()**和其他相关方法源代码,违反了“开闭原则”。
关键是来观察main()函数,main()函数与Fruit类是两个模块。当业务层希望创建一个对象的时候,将直接依赖Fruit类型的构造方法NewFruit(),这样随着Fruit的越来越复杂,那么业务层的开发逻辑也需要依赖Fruit模块的更新,且随之改变,这样将导致业务层开发需要观察Fruit模块做改动,影响业务层的开发效率和稳定性。整体的依赖关系为
业务逻辑层 —> 基础类模块
那么如何将业务层创建对象与基础类模块做解耦呢,这里即可以在中间加一层工厂模块层,来降低业务逻辑层对基础模块层的直接依赖和耦合关联。
业务逻辑层 —> 工厂模块 —> 基础类模块
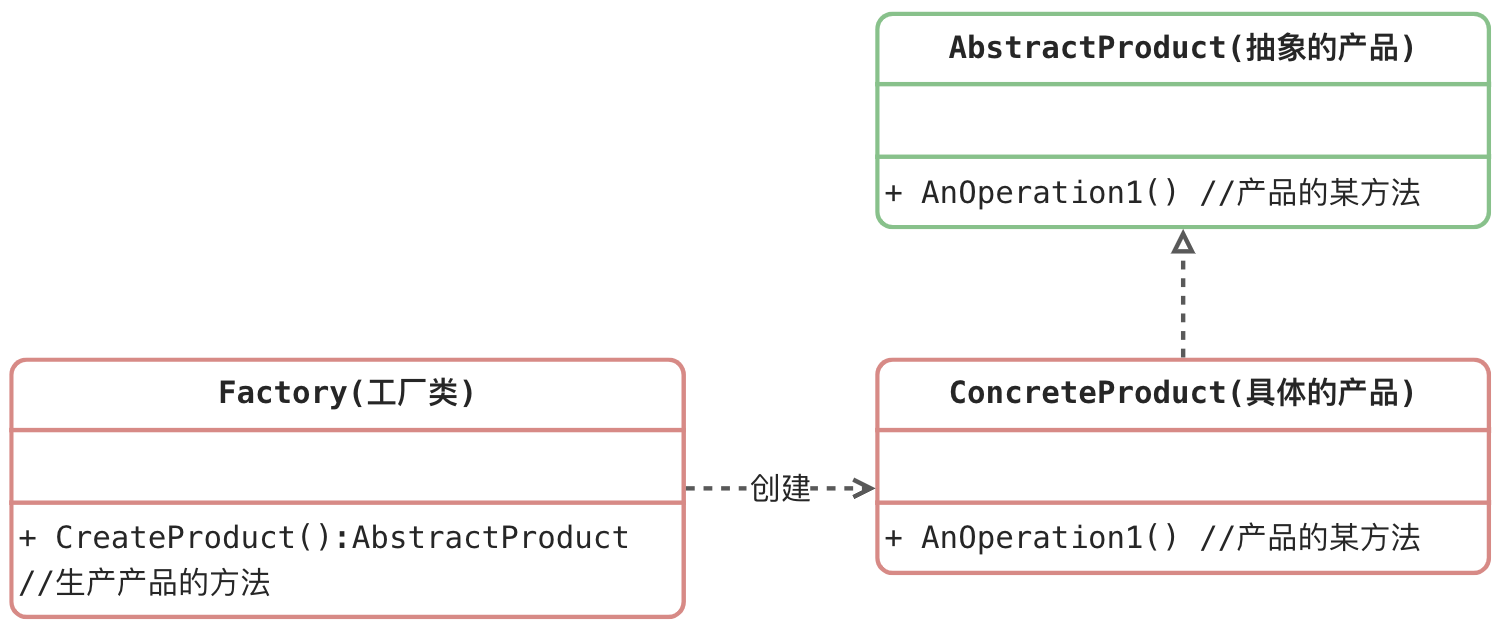
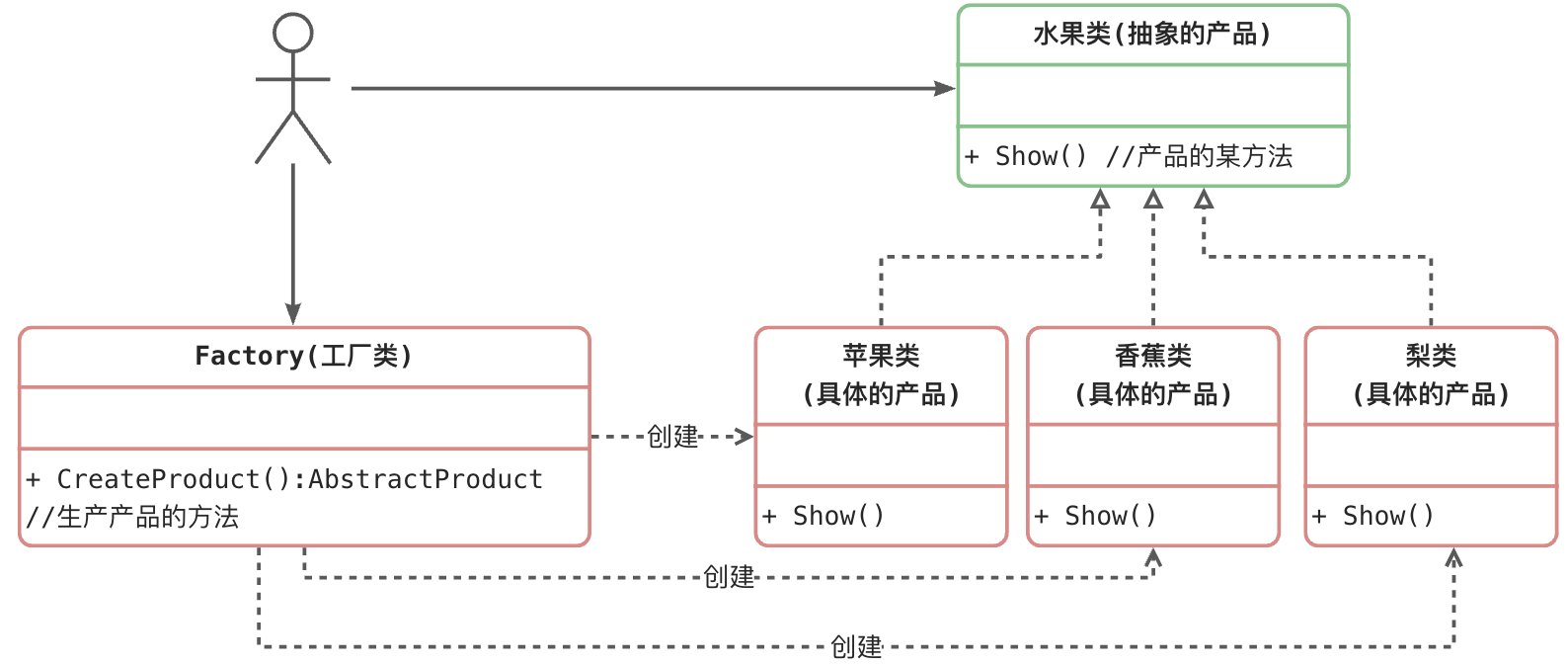
简单工厂模式角色和职责
工厂(Factory)角色:简单工厂模式的核心,它负责实现创建所有实例的内部逻辑。工厂类可以被外界直接调用,创建所需的产品对象。
抽象产品(AbstractProduct)角色:简单工厂模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口。
具体产品(Concrete Product)角色:简单工厂模式所创建的具体实例对象。
其标准的设计模式类图如下:
package main
import "fmt"
// ======= 抽象层 =========
//水果类(抽象接口)
type Fruit interface {
Show() //接口的某方法
}
// ======= 基础类模块 =========
type Apple struct {
Fruit //为了易于理解显示继承(此行可以省略)
}
func (apple *Apple) Show() {
fmt.Println("我是苹果")
}
type Banana struct {
Fruit
}
func (banana *Banana) Show() {
fmt.Println("我是香蕉")
}
type Pear struct {
Fruit
}
func (pear *Pear) Show() {
fmt.Println("我是梨")
}
// ========= 工厂模块 =========
//一个工厂, 有一个生产水果的机器,返回一个抽象水果的指针
type Factory struct {}
func (fac *Factory) CreateFruit(kind string) Fruit {
var fruit Fruit
if kind == "apple" {
fruit = new(Apple)
} else if kind == "banana" {
fruit = new(Banana)
} else if kind == "pear" {
fruit = new(Pear)
}
return fruit
}
// ==========业务逻辑层==============
func main() {
factory := new(Factory)
apple := factory.CreateFruit("apple")
apple.Show()
banana := factory.CreateFruit("banana")
banana.Show()
pear := factory.CreateFruit("pear")
pear.Show()
}
优点:1. 实现了对象创建和使用的分离。2. 不需要记住具体类名,记住参数即可,减少使用者记忆量。
缺点:1. 对工厂类职责过重,一旦不能工作,系统受到影响。2. 增加系统中类的个数,复杂度和理解度增加。3. 违反“开闭原则”,添加新产品需要修改工厂逻辑,工厂越来越复杂。
适用场景:1. 工厂类负责创建的对象比较少,由于创建的对象较少,不会造成工厂方法中的业务逻辑太过复杂。2. 客户端只知道传入工厂类的参数,对于如何创建对象并不关心。
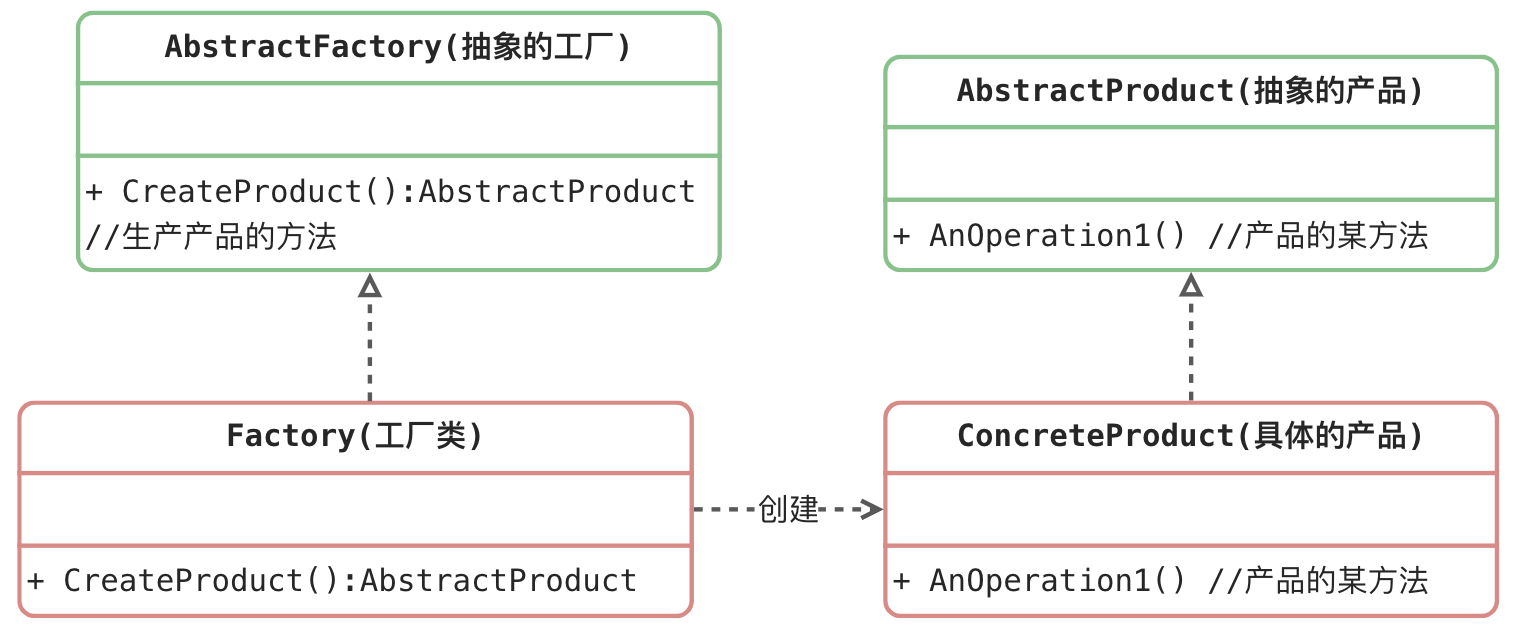
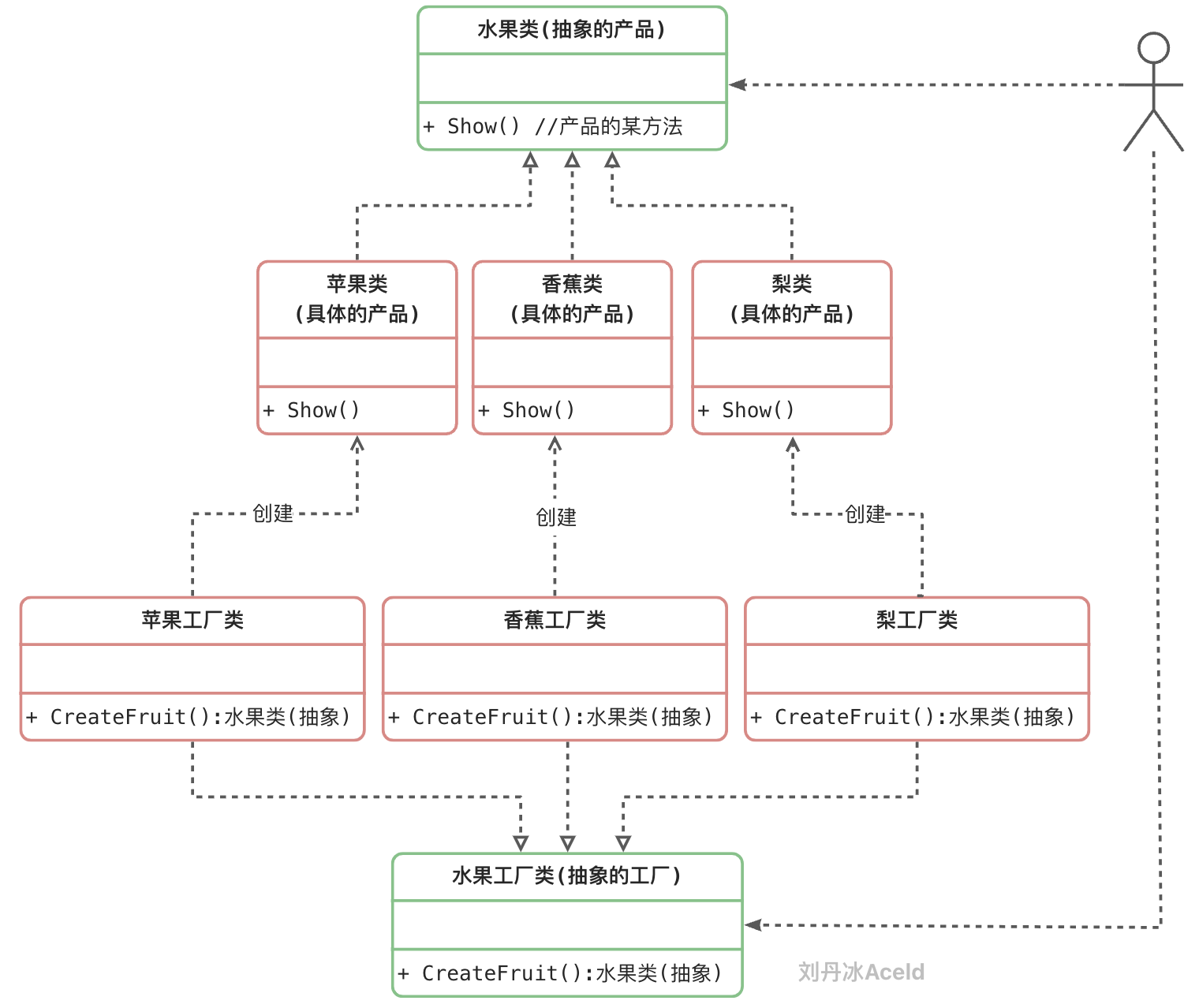
2 工厂方法模式
简单理解为:简单工厂+开闭原则
抽象工厂(Abstract Factory)角色:工厂方法模式的核心,任何工厂类都必须实现这个接口。
工厂(Concrete Factory)角色:具体工厂类是抽象工厂的一个实现,负责实例化产品对象。
抽象产品(Abstract Product)角色:工厂方法模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口。
具体产品(Concrete Product)角色:工厂方法模式所创建的具体实例对象。
package main
import "fmt"
// ======= 抽象层 =========
//水果类(抽象接口)
type Fruit interface {
Show() //接口的某方法
}
//工厂类(抽象接口)
type AbstractFactory interface {
CreateFruit() Fruit //生产水果类(抽象)的生产器方法
}
// ======= 基础类模块 =========
type Apple struct {
Fruit //为了易于理解显示继承(此行可以省略)
}
func (apple *Apple) Show() {
fmt.Println("我是苹果")
}
type Banana struct {
Fruit
}
func (banana *Banana) Show() {
fmt.Println("我是香蕉")
}
type Pear struct {
Fruit
}
func (pear *Pear) Show() {
fmt.Println("我是梨")
}
// ========= 工厂模块 =========
//具体的苹果工厂
type AppleFactory struct {
AbstractFactory
}
func (fac *AppleFactory) CreateFruit() Fruit {
var fruit Fruit
//生产一个具体的苹果
fruit = new(Apple)
return fruit
}
//具体的香蕉工厂
type BananaFactory struct {
AbstractFactory
}
func (fac *BananaFactory) CreateFruit() Fruit {
var fruit Fruit
//生产一个具体的香蕉
fruit = new(Banana)
return fruit
}
//具体的梨工厂
type PearFactory struct {
AbstractFactory
}
func (fac *PearFactory) CreateFruit() Fruit {
var fruit Fruit
//生产一个具体的梨
fruit = new(Pear)
return fruit
}
//======= 业务逻辑层 =======
func main() {
/*
本案例为了突出根据依赖倒转原则与面向接口编程特性。
一些变量的定义将使用显示类型声明方式
*/
//需求1:需要一个具体的苹果对象
//1-先要一个具体的苹果工厂
var appleFac AbstractFactory
appleFac = new(AppleFactory)
//2-生产相对应的具体水果
var apple Fruit
apple = appleFac.CreateFruit()
apple.Show()
//需求2:需要一个具体的香蕉对象
//1-先要一个具体的香蕉工厂
var bananaFac AbstractFactory
bananaFac = new(BananaFactory)
//2-生产相对应的具体水果
var banana Fruit
banana = bananaFac.CreateFruit()
banana.Show()
//需求3:需要一个具体的梨对象
//1-先要一个具体的梨工厂
var pearFac AbstractFactory
pearFac = new(PearFactory)
//2-生产相对应的具体水果
var pear Fruit
pear = pearFac.CreateFruit()
pear.Show()
//需求4:需要一个日本的苹果?
}
上述代码是通过面向抽象层开发,业务逻辑层的main()函数逻辑,依然是只与工厂耦合,且只与抽象的工厂和抽象的水果类耦合,这样就遵循了面向抽象层接口编程的原则。
那么抽象的工厂方法模式如何体现“开闭原则”的。接下来可以尝试在原有的代码上添加一种新产品的生产,如“日本苹果”,具体的代码如下:
package main
import "fmt"
// ======= 抽象层 =========
//水果类(抽象接口)
type Fruit interface {
Show() //接口的某方法
}
//工厂类(抽象接口)
type AbstractFactory interface {
CreateFruit() Fruit //生产水果类(抽象)的生产器方法
}
// ======= 基础类模块 =========
type Apple struct {
Fruit //为了易于理解显示继承(此行可以省略)
}
func (apple *Apple) Show() {
fmt.Println("我是苹果")
}
type Banana struct {
Fruit
}
func (banana *Banana) Show() {
fmt.Println("我是香蕉")
}
type Pear struct {
Fruit
}
func (pear *Pear) Show() {
fmt.Println("我是梨")
}
// ========= 工厂模块 =========
//具体的苹果工厂
type AppleFactory struct {
AbstractFactory
}
func (fac *AppleFactory) CreateFruit() Fruit {
var fruit Fruit
//生产一个具体的苹果
fruit = new(Apple)
return fruit
}
//具体的香蕉工厂
type BananaFactory struct {
AbstractFactory
}
func (fac *BananaFactory) CreateFruit() Fruit {
var fruit Fruit
//生产一个具体的香蕉
fruit = new(Banana)
return fruit
}
//具体的梨工厂
type PearFactory struct {
AbstractFactory
}
func (fac *PearFactory) CreateFruit() Fruit {
var fruit Fruit
//生产一个具体的梨
fruit = new(Pear)
return fruit
}
//======= 业务逻辑层 =======
func main() {
/*
本案例为了突出根据依赖倒转原则与面向接口编程特性。
一些变量的定义将使用显示类型声明方式
*/
//需求1:需要一个具体的苹果对象
//1-先要一个具体的苹果工厂
var appleFac AbstractFactory
appleFac = new(AppleFactory)
//2-生产相对应的具体水果
var apple Fruit
apple = appleFac.CreateFruit()
apple.Show()
//需求2:需要一个具体的香蕉对象
//1-先要一个具体的香蕉工厂
var bananaFac AbstractFactory
bananaFac = new(BananaFactory)
//2-生产相对应的具体水果
var banana Fruit
banana = bananaFac.CreateFruit()
banana.Show()
//需求3:需要一个具体的梨对象
//1-先要一个具体的梨工厂
var pearFac AbstractFactory
pearFac = new(PearFactory)
//2-生产相对应的具体水果
var pear Fruit
pear = pearFac.CreateFruit()
pear.Show()
//需求4:需要一个日本的苹果?
}
可以看见,新增的基本类“日本苹果”,和“具体的工厂” 均没有改动之前的任何代码。完全符合开闭原则思想。新增的功能不会影响到之前的已有的系统稳定性。
优点:1. 不需要记住具体类名,甚至连具体参数都不用记忆。2. 实现了对象创建和使用的分离。3. 系统的可扩展性也就变得非常好,无需修改接口和原类。4.对于新产品的创建,符合开闭原则。
缺点:1. 增加系统中类的个数,复杂度和理解度增加。2. 增加了系统的抽象性和理解难度。
适用场景:
-
客户端不知道它所需要的对象的类。
-
抽象工厂类通过其子类来指定创建哪个对象。
3 抽象工厂方法模式
提供一个创建一系列相关或者相互依赖的接口,而无需指定它们具体的类。
工厂方法模式通过引入工厂等级结构,解决了简单工厂模式中工厂类职责太重的问题,但由于工厂方法模式中的每个工厂只生产一类产品,可能会导致系统中存在大量的工厂类,势必会增加系统的开销。因此,可以考虑将一些相关的产品组成一个“产品族”,由同一个工厂来统一生产,这就是本文将要学习的抽象工厂模式的基本思想。
从工厂方法模式可以看出来:
(1)当添加一个新产品的时候,比如葡萄,虽然不用修改代码,但是需要添加大量的类,而且还需要添加相对的工厂。(系统开销,维护成本)
(2)如果使用同一地域的水果(日本苹果,日本香蕉,日本梨),那么需要分别创建具体的工厂,如果选择出现失误,将会造成混乱,虽然可以加一些约束,但是代码实现变得复杂。
所以“抽象工厂方法模式”引出了**“产品族”和“产品等级结构”**概念,其目的是为了更加高效的生产同一个产品组产品。
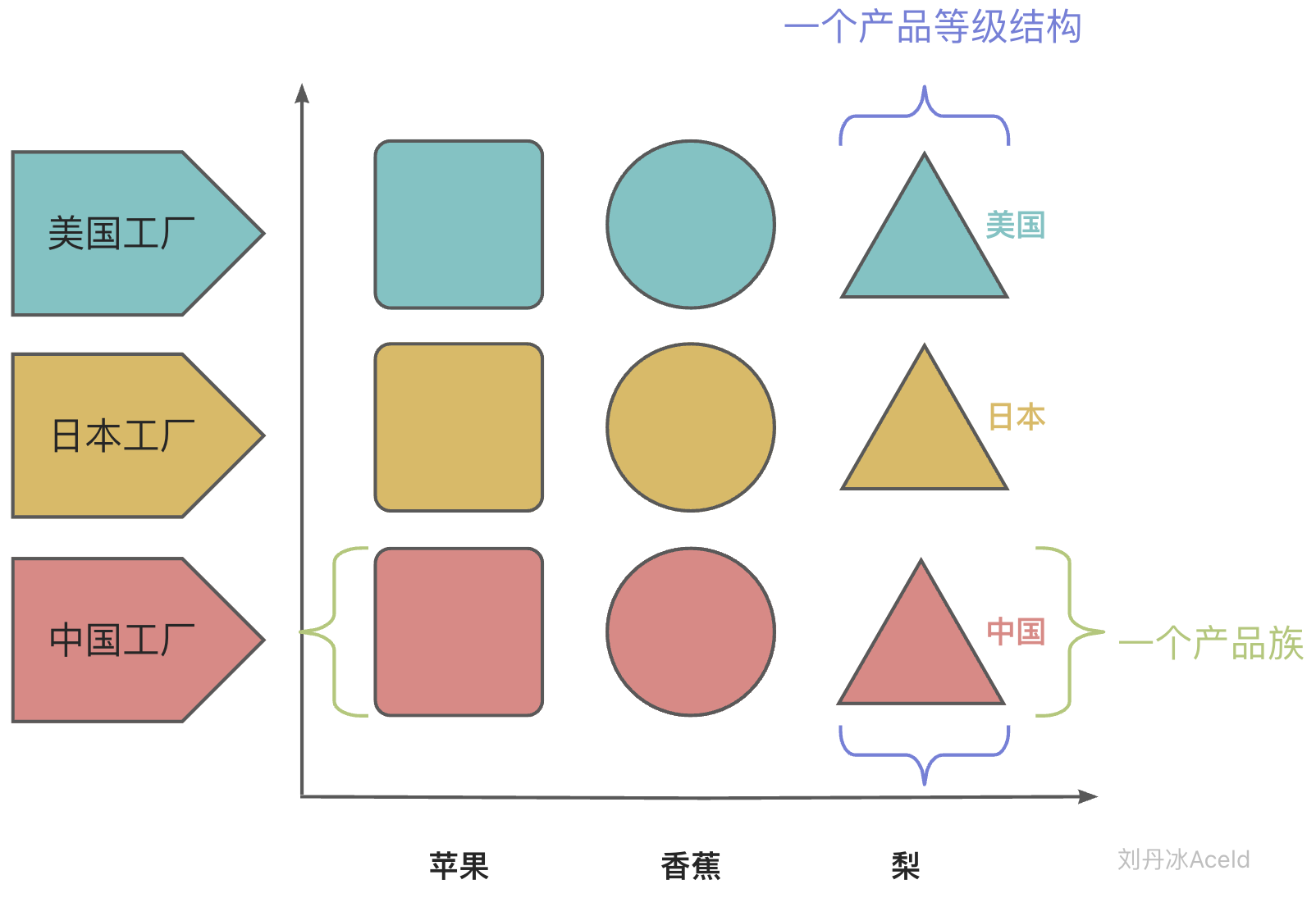
抽象工厂(Abstract Factory)角色:它声明了一组用于创建一族产品的方法,每一个方法对应一种产品。
具体工厂(Concrete Factory)角色:它实现了在抽象工厂中声明的创建产品的方法,生成一组具体产品,这些产品构成了一个产品族,每一个产品都位于某个产品等级结构中。
**抽象产品(Abstract Product)**角色:它为每种产品声明接口,在抽象产品中声明了产品所具有的业务方法。
**具体产品(Concrete Product)**角色:它定义具体工厂生产的具体产品对象,实现抽象产品接口中声明的业务方法。
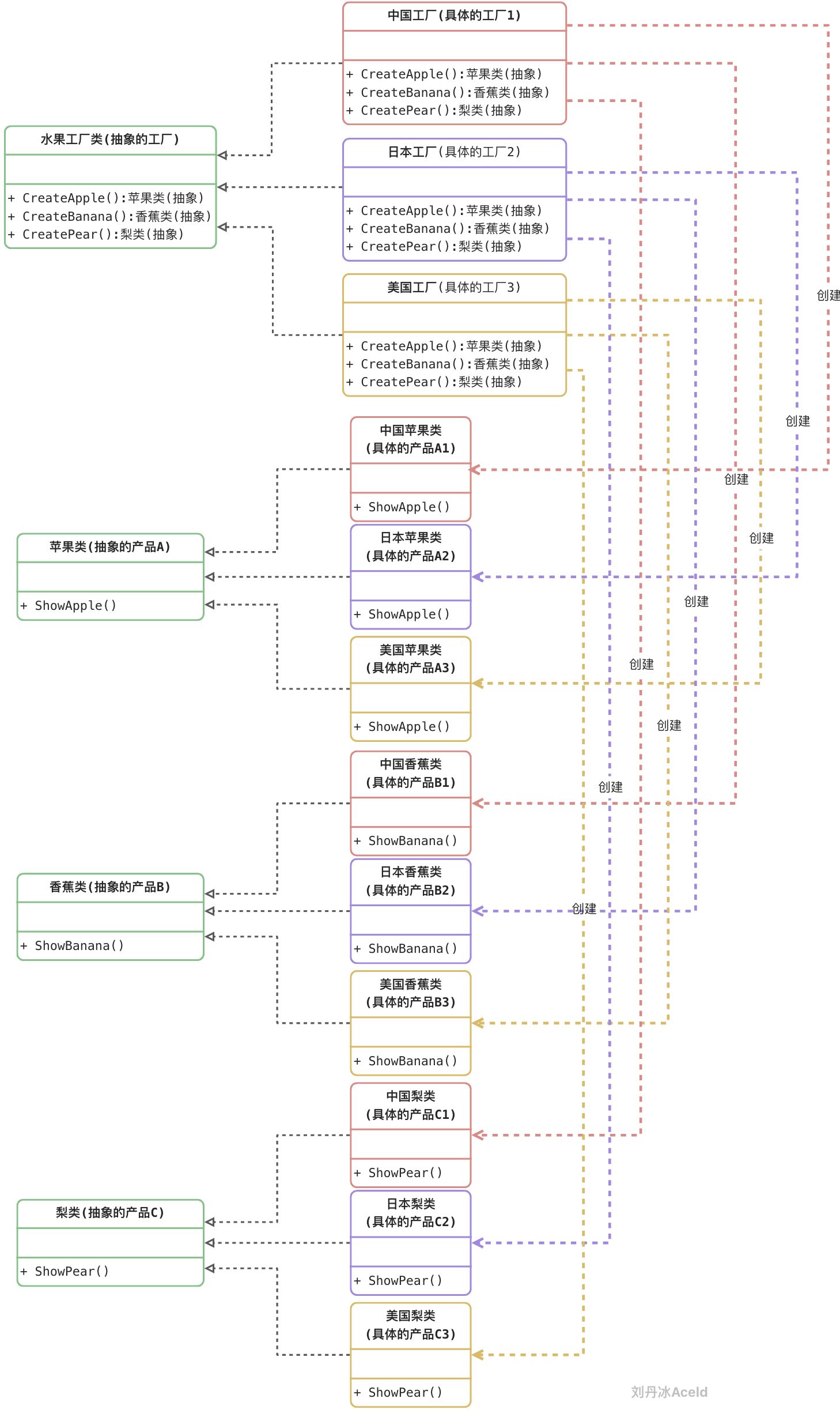
package main
import "fmt"
// ======= 抽象层 =========
type AbstractApple interface {
ShowApple()
}
type AbstractBanana interface {
ShowBanana()
}
type AbstractPear interface {
ShowPear()
}
//抽象工厂
type AbstractFactory interface {
CreateApple() AbstractApple
CreateBanana() AbstractBanana
CreatePear() AbstractPear
}
// ======== 实现层 =========
/* 中国产品族 */
type ChinaApple struct {}
func (ca *ChinaApple) ShowApple() {
fmt.Println("中国苹果")
}
type ChinaBanana struct {}
func (cb *ChinaBanana) ShowBanana() {
fmt.Println("中国香蕉")
}
type ChinaPear struct {}
func (cp *ChinaPear) ShowPear() {
fmt.Println("中国梨")
}
type ChinaFactory struct {}
func (cf *ChinaFactory) CreateApple() AbstractApple {
var apple AbstractApple
apple = new(ChinaApple)
return apple
}
func (cf *ChinaFactory) CreateBanana() AbstractBanana {
var banana AbstractBanana
banana = new(ChinaBanana)
return banana
}
func (cf *ChinaFactory) CreatePear() AbstractPear {
var pear AbstractPear
pear = new(ChinaPear)
return pear
}
/* 日本产品族 */
type JapanApple struct {}
func (ja *JapanApple) ShowApple() {
fmt.Println("日本苹果")
}
type JapanBanana struct {}
func (jb *JapanBanana) ShowBanana() {
fmt.Println("日本香蕉")
}
type JapanPear struct {}
func (cp *JapanPear) ShowPear() {
fmt.Println("日本梨")
}
type JapanFactory struct {}
func (jf *JapanFactory) CreateApple() AbstractApple {
var apple AbstractApple
apple = new(JapanApple)
return apple
}
func (jf *JapanFactory) CreateBanana() AbstractBanana {
var banana AbstractBanana
banana = new(JapanBanana)
return banana
}
func (cf *JapanFactory) CreatePear() AbstractPear {
var pear AbstractPear
pear = new(JapanPear)
return pear
}
/* 美国产品族 */
type AmericanApple struct {}
func (aa *AmericanApple) ShowApple() {
fmt.Println("美国苹果")
}
type AmericanBanana struct {}
func (ab *AmericanBanana) ShowBanana() {
fmt.Println("美国香蕉")
}
type AmericanPear struct {}
func (ap *AmericanPear) ShowPear() {
fmt.Println("美国梨")
}
type AmericanFactory struct {}
func (af *AmericanFactory) CreateApple() AbstractApple {
var apple AbstractApple
apple = new(AmericanApple)
return apple
}
func (af *AmericanFactory) CreateBanana() AbstractBanana {
var banana AbstractBanana
banana = new(AmericanBanana)
return banana
}
func (af *AmericanFactory) CreatePear() AbstractPear {
var pear AbstractPear
pear = new(AmericanPear)
return pear
}
// ======== 业务逻辑层 =======
func main() {
//需求1: 需要美国的苹果、香蕉、梨 等对象
//1-创建一个美国工厂
var aFac AbstractFactory
aFac = new(AmericanFactory)
//2-生产美国苹果
var aApple AbstractApple
aApple = aFac.CreateApple()
aApple.ShowApple()
//3-生产美国香蕉
var aBanana AbstractBanana
aBanana = aFac.CreateBanana()
aBanana.ShowBanana()
//4-生产美国梨
var aPear AbstractPear
aPear = aFac.CreatePear()
aPear.ShowPear()
//需求2: 需要中国的苹果、香蕉
//1-创建一个中国工厂
cFac := new(ChinaFactory)
//2-生产中国苹果
cApple := cFac.CreateApple()
cApple.ShowApple()
//3-生产中国香蕉
cBanana := cFac.CreateBanana()
cBanana.ShowBanana()
}
优点:1. 拥有工厂方法模式的优点 2. 当一个产品族中的多个对象被设计成一起工作时,它能够保证客户端始终只使用同一个产品族中的对象。3 增加新的产品族很方便,无须修改已有系统,符合“开闭原则”。
缺点:1. 增加新的产品等级结构麻烦,需要对原有系统进行较大的修改,甚至需要修改抽象层代码,这显然会带来较大的不便,违背了“开闭原则”。
3.3.5 适用场景
(1) 系统中有多于一个的产品族。而每次只使用其中某一产品族。可以通过配置文件等方式来使得用户可以动态改变产品族,也可以很方便地增加新的产品族。
(2) 产品等级结构稳定。设计完成之后,不会向系统中增加新的产品等级结构或者删除已有的产品等级结构。
4 单例模式
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
单例模式是最经典简单的设计模式,我们声明一个类并且保证这个类只存在全局唯一的实例供外部反复调用
适用场景:
- 只允许存在一个实例的类,比如全局统一的监控统计模块
Singleton(单例):在单例类的内部实现只生成一个实例,同时它提供一个静态的getInstance()工厂方法,让客户可以访问它的唯一实例;为了防止在外部对其实例化,将其构造函数设计为私有;在单例类内部定义了一个Singleton类型的静态对象,作为外部共享的唯一实例。
- “饿汉式”: 用不用都已经分配出去了,可能存在资源浪费
含义是,在初始化单例唯一指针的时候,就已经提前开辟好了一个对象,申请了内存。饿汉式的好处是,不会出现线程并发创建,导致多个单例的出现,但是缺点是如果这个单例对象在业务逻辑没有被使用,也会客观的创建一块内存对象。
package main
import "fmt"
/*
三个要点:
一是某个类只能有一个实例;
二是它必须自行创建这个实例;
三是它必须自行向整个系统提供这个实例。
*/
/*
保证一个类永远只能有一个对象
*/
//1、保证这个**类非公有化**,外界不能通过这个类直接创建一个对象
// 那么这个类就应该变得非公有访问 类名称**首字母要小写**
type singelton struct {}
//2、但是还要有一个指针可以指向这个唯一对象,但是这个指针永远不能改变方向
// Golang中没有常指针概念,所以只能通过将这个指针 不让外部模块访问
var instance *singelton = new(singelton)
//3、如果全部为私有化,那么外部模块将永远无法访问到这个类和对象,
// 所以需要对外提供一个方法来获取这个唯一实例对象
// 注意:这个方法是否可以定义为singelton的一个成员方法呢?
// 答案是不能,因为如果为成员方法就必须要先访问对象、再访问函数
// 但是类和对象目前都已经私有化,外界无法访问,所以这个方法一定是一个全局普通函数
func GetInstance() *singelton {
return instance
}
func (s *singelton) SomeThing() {
fmt.Println("单例对象的某方法")
}
func main() {
s := GetInstance()
s.SomeThing()
}
- 懒汉式:只有当主动获取实例的时候才去创建
package main
import "fmt"
type singelton struct {}
var instance *singelton
func GetInstance() *singelton {
// **只有首次GetInstance()方法被调用,才会生成这个单例的实例**
if instance == nil {
instance = new(singelton)
return instance
}
//接下来的GetInstance直接返回已经申请的实例即可
return instance
}
func (s *singelton) SomeThing() {
fmt.Println("单例对象的某方法")
}
func main() {
s := GetInstance()
s.SomeThing()
}
存在并发安全问题。上面的“懒汉式”实现是非线程安全的设计方式,也就是如果多个线程或者协程同时首次调用GetInstance()方法有概率导致多个实例被创建,则违背了单例的设计初衷。那么在上面的基础上进行修改,可以利用Sync.Mutex进行加锁,保证线程安全。这种线程安全的写法,有个最大的缺点就是每次调用该方法时都需要进行锁操作,在性能上相对不高效,具体的实现改进如下:
package main
import (
"fmt"
"sync"
)
//定义锁
var lock sync.Mutex
type singelton struct {}
var instance *singelton
func GetInstance() *singelton {
//为了线程安全,增加互斥
lock.Lock()
defer lock.Unlock()
if instance == nil {
return new(singelton)
} else {
return instance
}
}
func (s *singelton) SomeThing() {
fmt.Println("单例对象的某方法")
}
func main() {
s := GetInstance()
s.SomeThing()
}
上面代码虽然解决了线程安全,但是每次调用GetInstance()都要加锁会极大影响性能。所以接下来可以借助"sync/atomic"来进行内存的状态存留来做互斥。atomic就可以自动加载和设置标记,代码如下:
package main
import (
"fmt"
"sync"
"sync/atomic"
)
//标记
var initialized uint32
var lock sync.Mutex
type singelton struct {}
var instance *singelton
func GetInstance() *singelton {
//如果标记为被设置,直接返回,不加锁
if atomic.LoadUint32(&initialized) == 1 {
return instance
}
// 如果没有,则加锁申请
// 防止首次并发冲突
lock.Lock()
defer lock.Unlock()
if initialized == 0 {
instance = new(singelton)
//设置标记位
atomic.StoreUint32(&initialized, 1)
}
return instance
}
func (s *singelton) SomeThing() {
fmt.Println("单例对象的某方法")
}
func main() {
s := GetInstance()
s.SomeThing()
}
上述的实现其实Golang有个方法已经帮助开发者实现完成,就是Once模块,来看下Once.Do()方法的源代码:
func (o *Once) Do(f func()) { //判断是否执行过该方法,如果执行过则不执行
if atomic.LoadUint32(&o.done) == 1 {
return
}
// Slow-path.
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
package main
import (
"fmt"
"sync"
)
var once sync.Once
type singelton struct {}
var instance *singelton
func GetInstance() *singelton {
once.Do(func(){
instance = new(singelton)
})
return instance
}
func (s *singelton) SomeThing() {
fmt.Println("单例对象的某方法")
}
func main() {
s := GetInstance()
s.SomeThing()
}
优点:
(1) 单例模式提供了对唯一实例的受控访问。
(2) 节约系统资源。由于在系统内存中只存在一个对象。
缺点:
(1) 扩展略难。单例模式中没有抽象层。
(2) 单例类的职责过重。
适用场景
(1) 系统只需要一个实例对象,如系统要求提供一个唯一的序列号生成器或资源管理器,或者需要考虑资源消耗太大而只允许创建一个对象。
(2) 客户调用类的单个实例只允许使用一个公共访问点,除了该公共访问点,不能通过其他途径访问该实例。