负载均衡是分布式可靠性中非常关键的一个问题或技术,在一定程度上反映了分布式系统对业务处理的能力。比如,早期的电商抢购活动,当流量过大时,可能就会发现有些地区可以购买,而有些地区因为服务崩溃而不能抢购。这其实就是系统的负载均衡出现了问题。
什么是负载均衡?
通常情况下,负载均衡可以分为两种:
一种是请求负载均衡,即将用户的请求均衡地分发到不同的服务器进行处理;
另一种是数据负载均衡,即将用户更新的数据分发到不同的存储服务器。
分布式系统中,服务请求的负载均衡是指,当处理大量用户请求时,请求应尽量均衡地分配到多台服务器进行处理,每台服务器处理其中一部分而不是所有的用户请求,以完成高并发的请求处理,避免因单机处理能力的上限,导致系统崩溃而无法提供服务的问题。比如,有 N 个请求、M 个节点,负载均衡就是将 N 个请求,均衡地转发到这 M 个节点进行处理。
轮询策略
轮询策略是一种实现简单,却很常用的负载均衡策略,核心思想是服务器轮流处理用户请求,以尽可能使每个服务器处理的请求数相同。
在负载均衡领域中,轮询策略主要包括顺序轮询和加权轮询两种方式,加权是为了适应不同性能机器(不同负载能力)
Nginx 默认的负载均衡策略就是一种改进的加权轮询策略
Nginx 轮询策略需要用到的变量:
weight:配置文件中为每个服务节点设置的服务节点权重,固定不变。
effective_weight:服务节点的有效权重,初始值为 weight。
在 Nginx 的源码中有一个最大失败数的变量 max_fails,当服务发生异常时,则减少相应服务节点的有效权重,公式为 effective_weight = effective_weight - weight / max_fails;之后再次选取本节点,若服务调用成功,则增加有效权重,effective_weight ++ ,直至恢复到 weight。
current_weight:服务节点当前权重,初始值均为 0,之后会根据系统运行情况动态变化。
假设,各服务器的优先级是{4,1,1},还是将 6 个请求分为 6 步来进行,如下所示:
遍历集群中所有服务节点,使用 current_weight = current_weight + effective_weight,计算此时每个服务节点的 current_weight,得到 current_weight 为{4,1,1},total 为 4+1+1=6。选出 current_weight 值最大的服务节点即服务器 1 来处理请求,随后服务器 1 对应的 current_weight 减去此时的 total 值,即 4 - 6,变为了 -2 。
按照上述步骤执行,首先遍历,按照 current_weight = current_weight + effective_weight 计算每个服务节点 current_weight 的值,结果为{2,2,2},total 为 6,选出 current_weight 值最大的服务节点。current_weight 最大值有多个服务节点时,直接选择第一个节点即可,在这里选择服务器 1 来处理请求,随后服务器 1 对应的 current_weight 值减去此时的 total,即 2 - 6,结果为 -4。
以此类推,直到处理完这 6 个请求。
最终的处理结果为,服务器 1 处理请求 1、2、4、6,服务器 2 处理请求 3,服务器 3 会处理请求 5。
可以看到,与普通的加权轮询策略相比,这种轮询策略的优势在于,当部分请求到来时,不会集中落在优先级较高的那个服务节点。
**优点:**实现简单,且对于请求所需开销差不多时,负载均衡效果比较明显,同时加权轮询策略还考虑了服务器节点的异构性,即可以让性能更好的服务器具有更高的优先级,从而可以处理更多的请求,使得分布更加均衡。
**缺点:**每次请求到达的目的节点不确定,不适用于有状态请求的场景。并且,轮询策略主要强调请求数的均衡性,所以不适用于处理请求所需开销不同的场景。
轮询策略适用于用户请求所需资源比较接近的场景。
最少连接数
根据实时的负载情况,进行动态负载均衡的方式。维护好活动中的连接数量,然后取最小的返回即可
最快响应
这也是一种动态负载均衡策略,它的本质是根据每个节点对过去一段时间内的响应情况来分配,响应越快分配的越多。具体的运作方式也有很多,比如请求a b c耗时分别为15ms,30ms,10ms,将最近一段时间的请求耗时的平均值记录下来,结合前面的「加权轮询」来处理,所以等价于2:1:3的加权轮询。
题外话:一般来说,同机房下的延迟基本没什么差异,响应时间的差异主要在服务的处理能力上。如果在跨地域(例:浙江->上海,还是浙江->北京)的一些请求处理中运用,大多数情况会使用定时「ping」的方式来获取延迟情况,因为是OSI的L3转发,数据更干净,准确性更高。
Hash法
hash法的负载均衡与之前的几种不同在于,它的结果是由客户端决定的。通过客户端带来的某个标识经过一个标准化的散列函数进行打散分摊。

高可用保障
不管是什么样的策略,难免会遇到机器故障或者程序故障的情况。所以要确保负载均衡能更好的起到效果,还需要结合一些「健康探测」机制。定时的去探测服务端是不是还能连上,响应是不是超出预期的慢。如果节点属于“不可用”的状态的话,需要将这个节点临时从待选取列表中移除,以提高可用性。一般常用的「健康探测」方式有3种。
HTTP探测
使用Get/Post的方式请求服务端的某个固定的URL,判断返回的内容是否符合预期。一般使用Http状态码、response中的内容来判断。
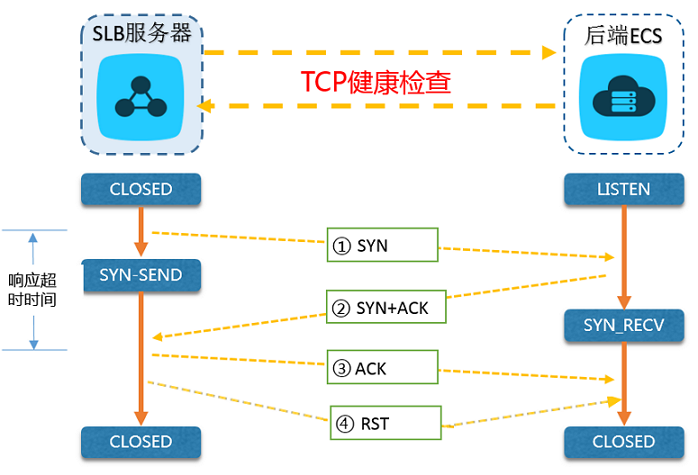
TCP探测
基于Tcp的三次握手机制来探测指定的IP + 端口。最佳实践可以借鉴阿里云的SLB机制,如下图。
UDP探测
可能有部分应用使用的UDP协议。在此协议下可以通过报文来进行探测指定的IP + 端口。最佳实践同样可以借鉴阿里云的SLB机制,如下图。
结果的判定方式是:在服务端没有返回任何信息的情况下,默认正常状态。否则会返回一个ICMP的报错信息。