TCP重传机制
超时重传
快速重传
SACK
D-SACK
超时重传
发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据
当超时时间 RTO 较大时,重发就慢,丢了老半天才重发,没有效率,性能差;
当超时时间 RTO 较小时,会导致可能并没有丢就重发,于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
超时重传时间 RTO 的值应该略大于报文往返 RTT 的值
Linux 是如何计算 RTO 的呢?
估计往返时间,通常需要采样以下两个:
需要 TCP 通过采样 RTT 的时间,然后进行加权平均,算出一个平滑 RTT 的值,而且这个值还是要不断变化的,因为网络状况不断地变化。
除了采样 RTT,还要采样 RTT 的波动范围,这样就避免如果 RTT 有一个大的波动的话,很难被发现的情况。
快速重传

快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。问题:重传的时候,是重传一个,还是重传所有的问题
SACK 方法 选择性确认
这种方式需要在 TCP 头部「选项」字段里加一个 SACK 的东西,它可以将已收到的数据的信息发送给「发送方」,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。

Duplicate SACK
使用了 SACK 来告诉「发送方」有哪些数据被重复接收了

滑动窗口
窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。
窗口的实现实际上是操作系统开辟的一个缓存空间,发送方主机在等到确认应答返回之前,必须在缓冲区中保留已发送的数据。如果按期收到确认应答,此时数据就可以从缓存区清除。
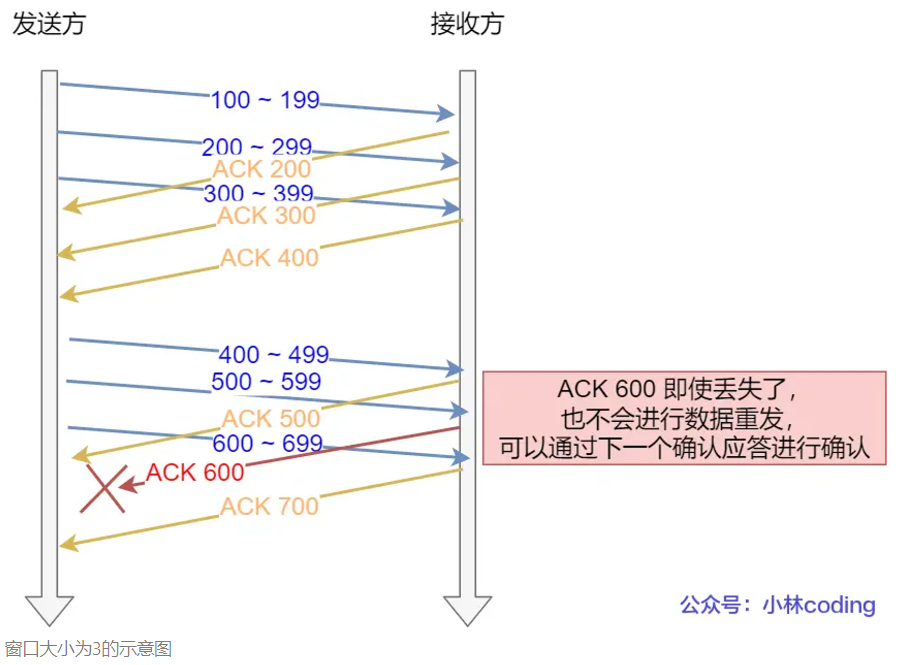
窗口大小为3的示意图
ACK 600 确认应答报文丢失,也没关系,因为可以通过下一个确认应答进行确认,只要发送方收到了 ACK 700 确认应答,就意味着 700 之前的所有数据「接收方」都收到了。这个模式就叫累计确认或者累计应答。
TCP 头里有一个字段叫 Window,也就是窗口大小。
这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。所以通常窗口的大小是由接收方的窗口大小来决定的。
发送方:

接收方:
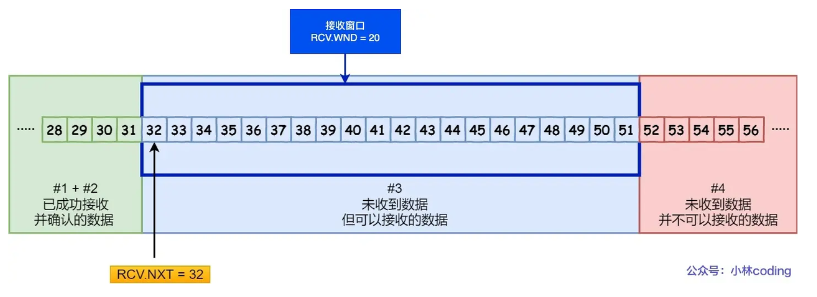
接收窗口的大小是约等于发送窗口的大小的。因为滑动窗口并不是一成不变的。比如,当接收方的应用进程读取数据的速度非常快的话,这样的话接收窗口可以很快的就空缺出来。那么新的接收窗口大小,是通过 TCP 报文中的 Windows 字段来告诉发送方。那么这个传输过程是存在时延的,所以接收窗口和发送窗口是约等于的关系
流量控制
TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制
客户端是接收方,服务端是发送方
假设接收窗口和发送窗口相同,都为
200假设两个设备在整个传输过程中都保持相同的窗口大小,不受外界影响
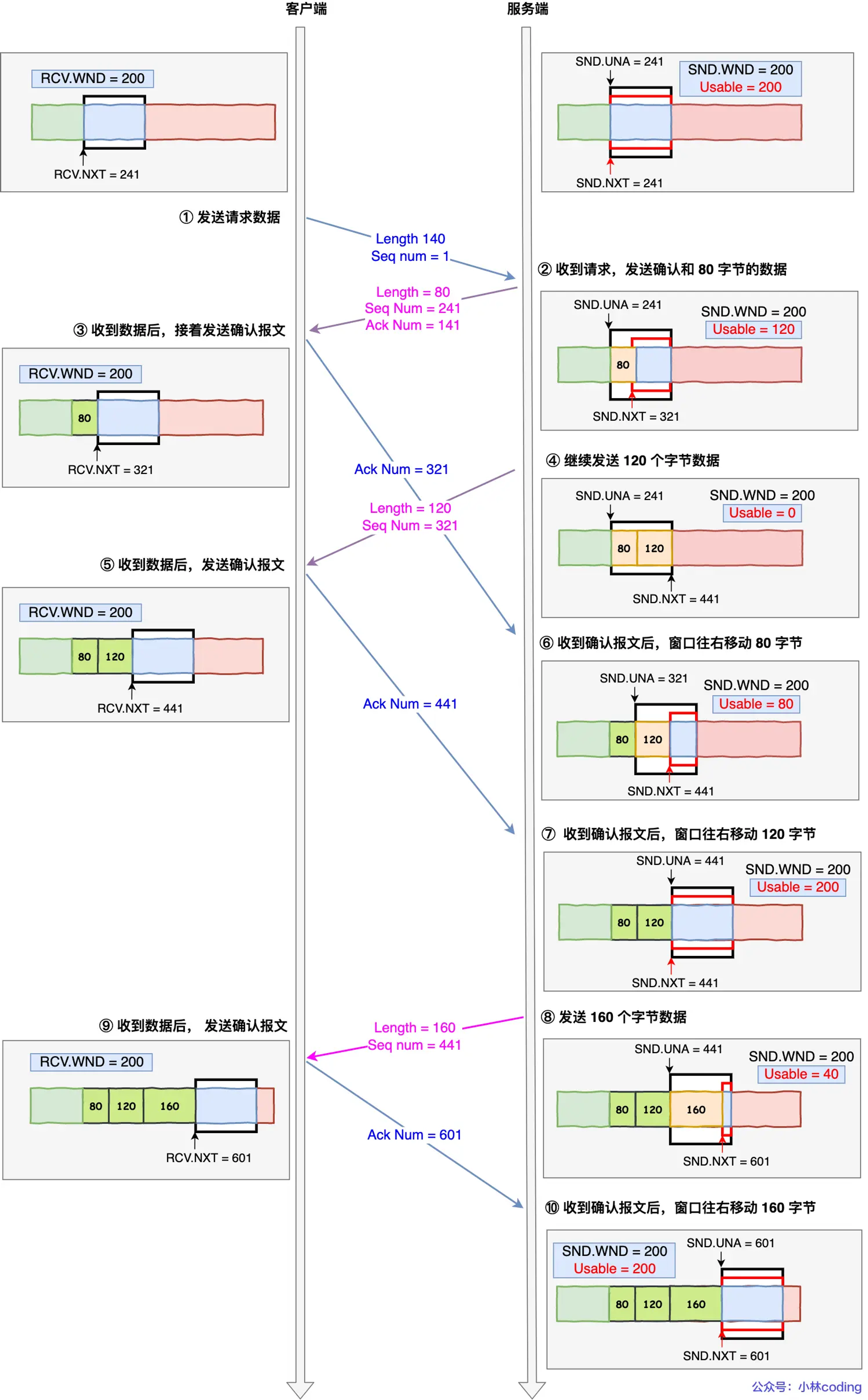
这个情况假定了发送窗口和接收窗口是不变的,但是实际上,发送窗口和接收窗口中所存放的字节数,都是放在os内存缓冲区中的,而os的缓冲区,会被操作系统调整。
下一个例子:
客户端作为发送方,服务端作为接收方,发送窗口和接收窗口初始大小为
360;服务端非常的繁忙,当收到客户端的数据时,应用层不能及时读取数据。

最后窗口都收缩为 0 了,也就是发生了窗口关闭。当发送方可用窗口变为 0 时,发送方实际上会定时发送窗口探测报文,以便知道接收方的窗口是否发生了改变
当服务端系统资源非常紧张的时候,操作系统可能会直接减少了接收缓冲区大小,这时应用程序又无法及时读取缓存数据,那么这时候就有严重的事情发生了,会出现数据包丢失的现象。
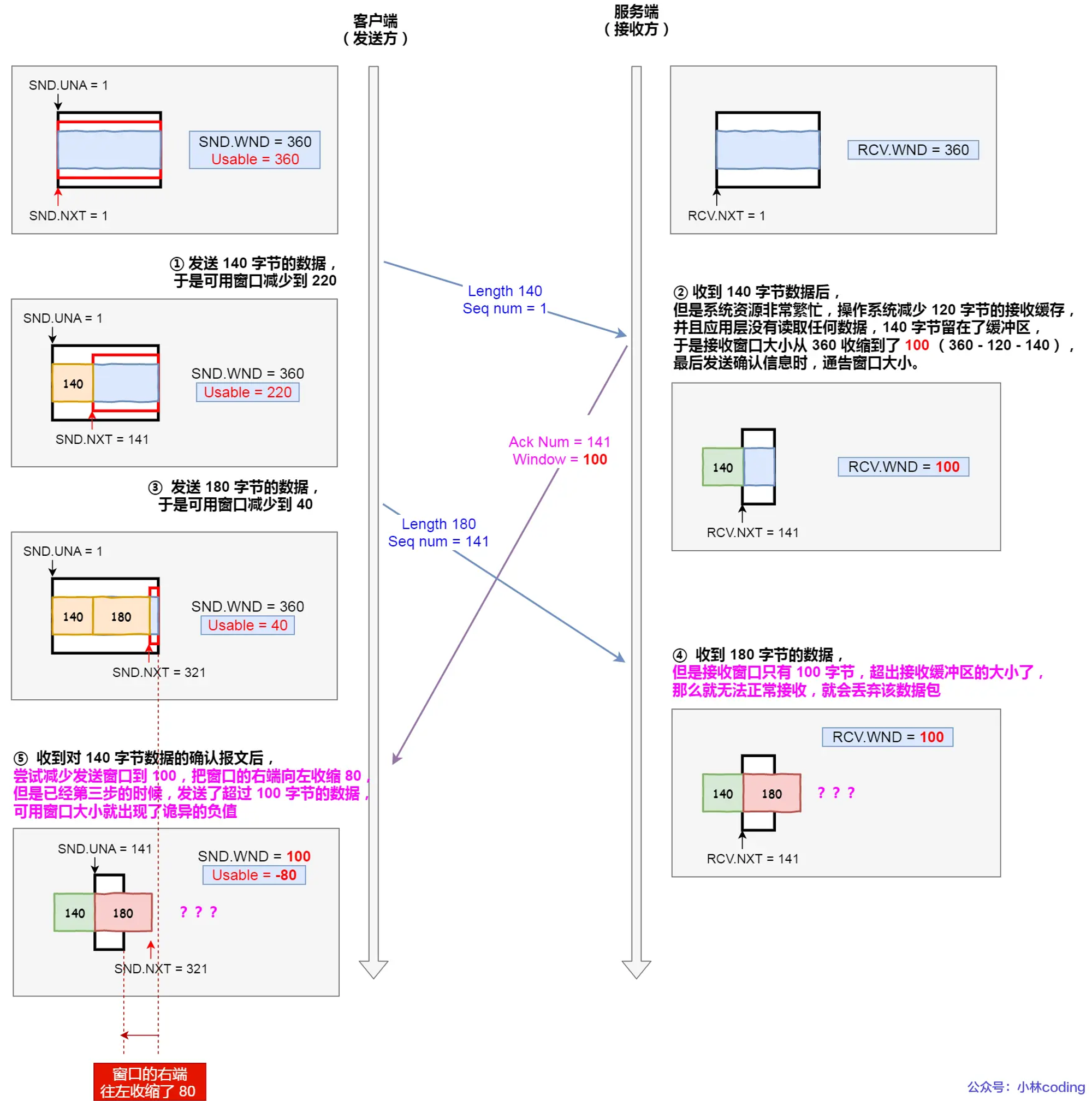
所以,如果发生了先减少缓存,再收缩窗口,就会出现丢包的现象。
为了防止这种情况发生,TCP 规定是不允许同时减少缓存又收缩窗口的,而是采用先收缩窗口,过段时间再减少缓存,这样就可以避免了丢包情况。
窗口关闭
**如果窗口大小为 0 时,就会阻止发送方给接收方传递数据,直到窗口变为非 0 为止,这就是窗口关闭。**当发生窗口关闭时,接收方处理完数据后,会向发送方通告一个窗口非 0 的 ACK 报文,如果这个通告窗口的 ACK 报文在网络中丢失了,那麻烦就大了。
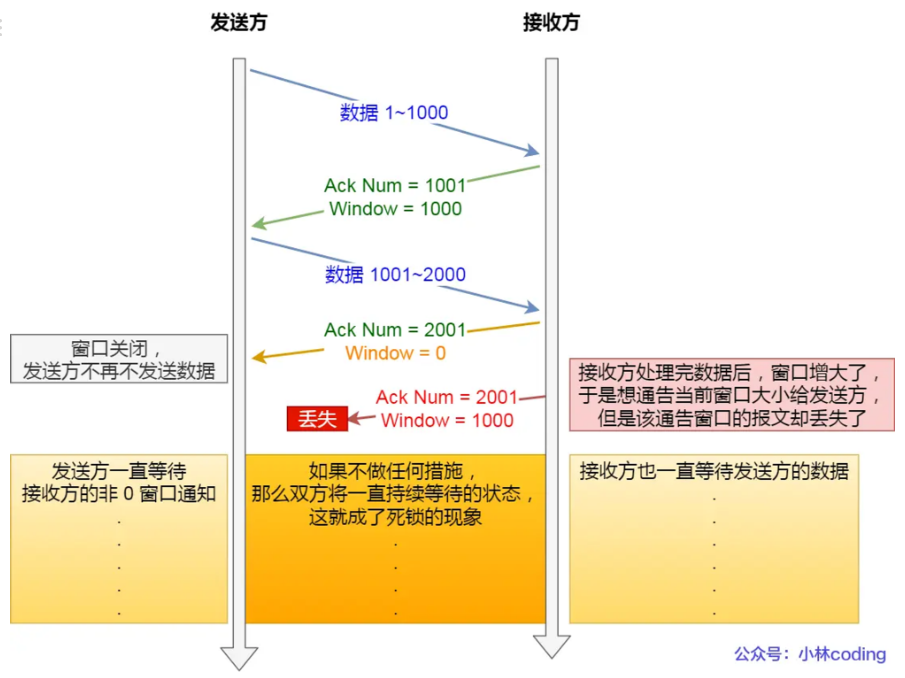
造成死锁现象
解决这个问题,TCP 为每个连接设有一个持续定时器,只要 TCP 连接一方收到对方的零窗口通知,就启动持续计时器。如果持续计时器超时,就会发送窗口探测 ( Window probe ) 报文,而对方在确认这个探测报文时,给出自己现在的接收窗口大小。
如果接收窗口仍然为 0,那么收到这个报文的一方就会重新启动持续计时器;
如果接收窗口不是 0,那么死锁的局面就可以被打破了。
窗口探测的次数一般为 3 次,每次大约 30-60 秒(不同的实现可能会不一样)。如果 3 次过后接收窗口还是 0 的话,有的 TCP 实现就会发 RST 报文来中断连接。
糊涂窗口综合症
如果接收方太忙了,来不及取走接收窗口里的数据,那么就会导致发送方的发送窗口越来越小。
到最后,如果接收方腾出几个字节并告诉发送方现在有几个字节的窗口,而发送方会义无反顾地发送这几个字节,这就是糊涂窗口综合症。
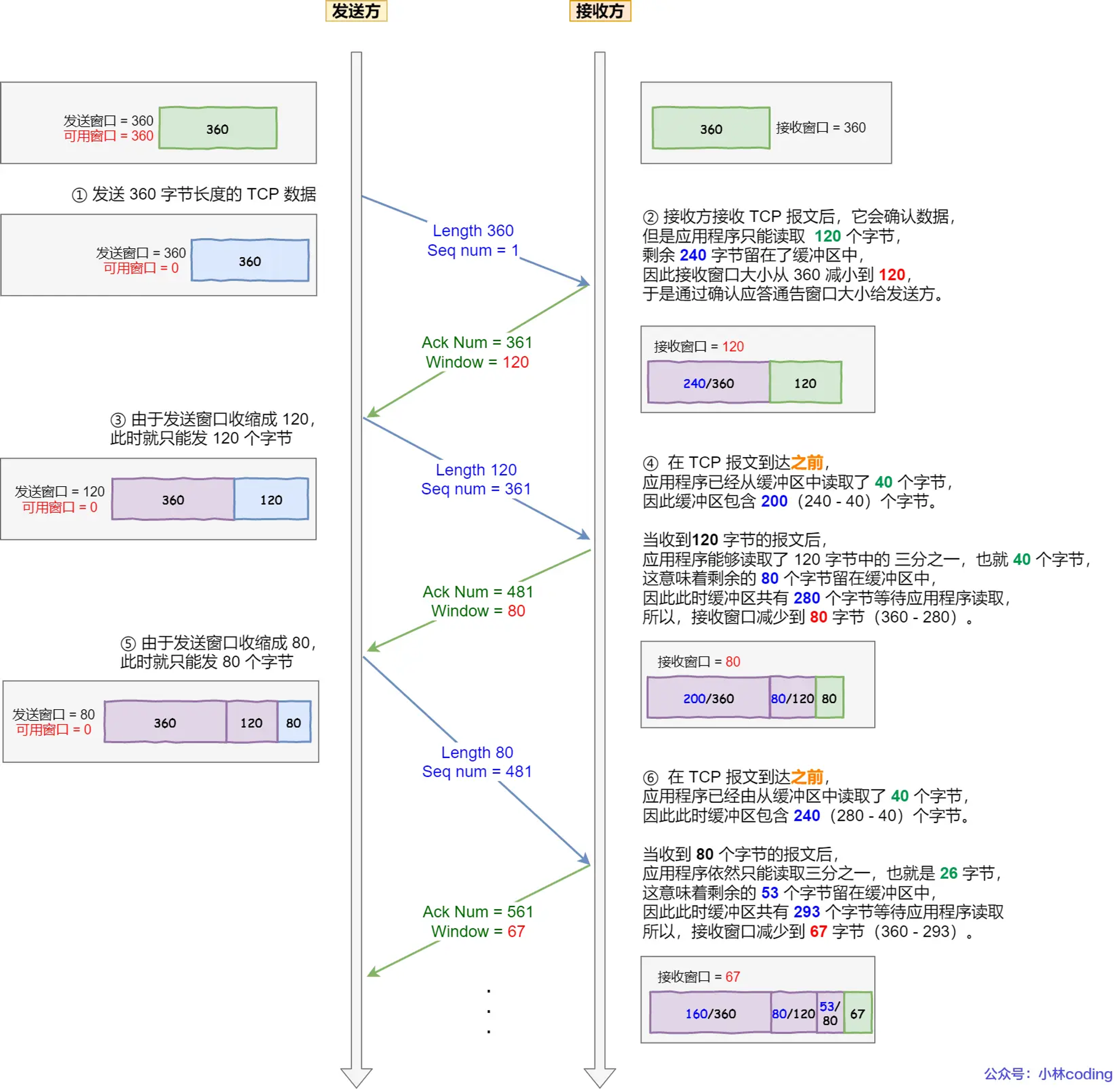
现举个糊涂窗口综合症的栗子,考虑以下场景:
接收方的窗口大小是 360 字节,但接收方由于某些原因陷入困境,假设接收方的应用层读取的能力如下:
接收方每接收 3 个字节,应用程序就只能从缓冲区中读取 1 个字节的数据;
在下一个发送方的 TCP 段到达之前,应用程序还从缓冲区中读取了 40 个额外的字节;
接收方不通告小窗口 策略如下:
当「窗口大小」小于 min( MSS,缓存空间/2 ) ,也就是小于 MSS 与 1/2 缓存大小中的最小值时,就会向发送方通告窗口为 0,也就阻止了发送方再发数据过来。
等到接收方处理了一些数据后,窗口大小 >= MSS,或者接收方缓存空间有一半可以使用,就可以把窗口打开让发送方发送数据过来。
发送方避免发送小数据
使用 Nagle 算法,该算法的思路是延时处理,只有满足下面两个条件中的任意一个条件,才可以发送数据:
条件一:要等到窗口大小 >=
MSS并且 数据大小 >=MSS;条件二:收到之前发送数据的
ack回包;
只要上面两个条件都不满足,发送方一直在囤积数据,直到满足上面的发送条件。
如果接收方不能满足「不通告小窗口给发送方」,那么即使开了 Nagle 算法,也无法避免糊涂窗口综合症,因为如果对端 ACK 回复很快的话(达到 Nagle 算法的条件二),Nagle 算法就不会拼接太多的数据包,这种情况下依然会有小数据包的传输,网络总体的利用率依然很低。
所以,接收方得满足「不通告小窗口给发送方」+ 发送方开启 Nagle 算法,才能避免糊涂窗口综合症。
拥塞控制
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环被不断地放大....
拥塞控制可以避免「发送方」的数据填满整个网络
拥塞窗口 cwnd是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的
只要网络中没有出现拥塞,
cwnd就会增大;但网络中出现了拥塞,
cwnd就减少;
其实只要「发送方」没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就会认为网络出现了拥塞。
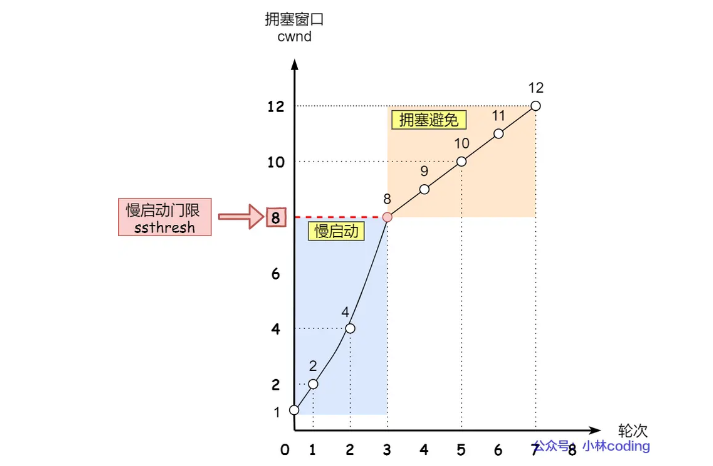
慢启动

拥塞避免
当拥塞窗口超过限制后,进入拥塞避免算法:每当收到一个 ACK 时,cwnd 增加 1/cwnd,成为线性增长。按这个算法网络就会慢慢进入了拥塞的状况了,于是就会出现丢包现象,这时就需要对丢失的数据包进行重传。当触发了重传机制,也就进入了「拥塞发生算法」
拥塞发生:超时重传就回触发该算法
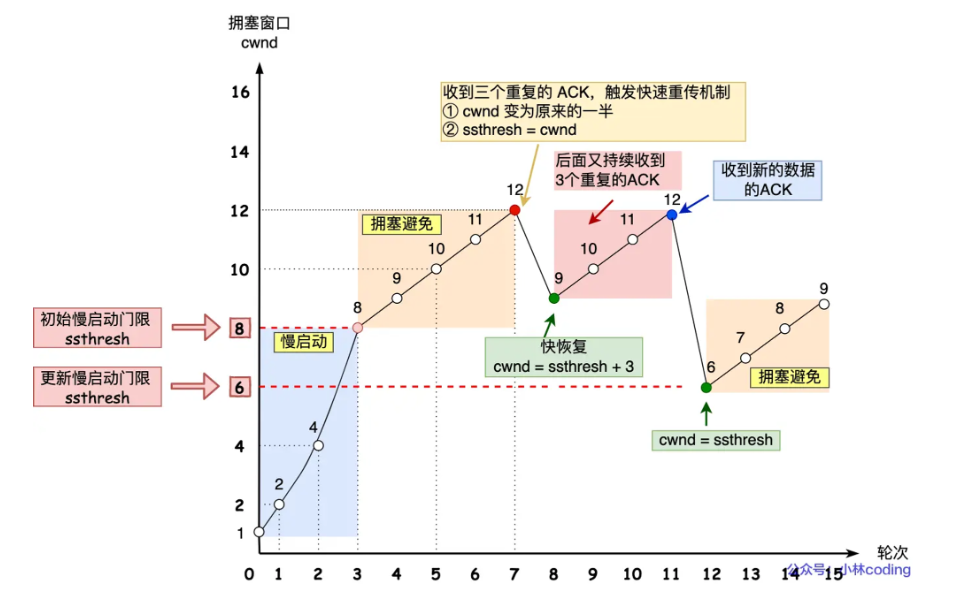
当发生了**「超时重传」**这个时候,ssthresh 和 cwnd 的值会发生变化:
ssthresh设为cwnd/2,cwnd重置为1(是恢复为 cwnd 初始化值,我这里假定 cwnd 初始化值 1)

发生**「快速重传」**的时候,TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,则 ssthresh 和 cwnd 变化如下:
cwnd = cwnd/2,也就是设置为原来的一半;ssthresh = cwnd;
进入快速恢复算法
快速恢复
拥塞窗口
cwnd = ssthresh + 3( 3 的意思是确认有 3 个数据包被收到了);重传丢失的数据包;
如果再收到重复的 ACK,那么 cwnd 增加 1;
如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态;
TCP优化
三次握手性能提升
在网络状态不佳、高并发或者遭遇 SYN 攻击等场景中,如果不能有效正确的调节三次握手中的参数,就会对性能产生很多的影响。
客户端优化:可以根据网络的稳定性和目标服务器的繁忙程度修改 SYN 的重传次数,调整客户端的三次握手时间上限。比如内网中通讯时,就可以适当调低重试次数,尽快把错误暴露给应用程序。默认有五次重传,差不多1分钟
**服务端优化:当服务端收到 SYN 包后,服务端会立马回复 SYN+ACK 包,表明确认收到了客户端的序列号,同时也把自己的序列号发给对方。此时,服务端出现了新连接,状态是 SYN_RCV。在这个状态下,Linux 内核就会建立一个「半连接队列」**来维护「未完成」的握手信息,当半连接队列溢出后,服务端就无法再建立新的连接。出现SYN攻击很容易就导致半连接队列满了,方法:增大队列;开启syncookies;
四次挥手性能提升
主动方的优化
关闭连接的方式通常有两种,分别是 RST 报文关闭和 FIN 报文关闭。
如果进程收到 RST 报文,就直接关闭连接了,不需要走四次挥手流程,是一个暴力关闭连接的方式。安全关闭连接的方式必须通过四次挥手,它由进程调用 close 和 shutdown 函数发起 FIN 报文(shutdown 参数须传入 SHUT_WR 或者 SHUT_RDWR 才会发送 FIN)。
tcp_max_tw_buckets 参数,当 TIME_WAIT 的连接数量超过该参数时,新关闭的连接就不再经历 TIME_WAIT 而直接关闭
有一种方式可以在建立新连接时,复用处于 TIME_WAIT 状态的连接,那就是打开 tcp_tw_reuse 参数。但是需要注意,该参数是只用于客户端(建立连接的发起方),因为是在调用 connect() 时起作用的,而对于服务端(被动连接方)是没有用的。
在程序中设置 socket 选项,来设置调用 close 关闭连接行为。调用 close 后,会立该发送一个 RST 标志给对端,该 TCP 连接将跳过四次挥手,也就跳过了 TIME_WAIT 状态,直接关闭