nodeSelector的缺点:强制约束,Pod只能在固定的一批节点中进行调度,若找不到指定的标签,直接调度失败。
使用亲和性的优点:
表述语法更加多样化,不再仅受限于强制约束与匹配
调度规则不再是强制约束(hard),取而代之的是软限(soft)或偏好(preference)
指定pod可以和哪些pod部署在同一个/不同拓扑结构下
affinity根据匹配的内容可以分为三种:
nodeAffinity- Node亲和性:“这个Pod应该部署在这个Node上”podAffinity- Pod亲和性:“这个Pod应该和那个Pod部署在一起”podAntiAffinity- Pod反亲和性:“这个Pod不应该和那个Pod部署在一起”
亲和性调度策略
预备知识:K8S调度流程与硬/软策略
预选(predicate):遍历所有节点,选择出符合预选策略 (又称 “硬策略” ) 要求的候选节点。若没有符合要求的,那就一直重试直到有符合要求的节点出现。
优选(priority):在选择出符合要求的候选节点中,根据优选策略 (又称 “软策略” ) 计算出每个节点的得分,最后选择得分最高的。
选定(select):如果最高得分有好几个节点,select就会从中随机选择一个节点。
在调度期的Pod调度策略和在运行过程中的Pod调度策略
在亲和性调度规则的定义文件中,除了指定一个调度规则是硬策略还是软策略外,还需要定义这个规则在运行过程中是否生效:
运行过程中生效的硬策略:
requiredDuringSchedulingRequiredDuringExecution(计划中,未实现,现在版本还不支持)在调度期间必须满足规则,如果不能满足规则,则Pod不能被调度到对应的主机上
在之后的运行过程中,如果因为某些原因(比如修改label)导致规则不能满足,系统会尝试把Pod从主机上删除
运行过程中不生效的硬策略:
requiredDuringSchedulingIgnoredDuringExecution在调度期间必须满足规则,如果不能满足规则,则Pod不能被调度到对应的主机上
在之后的运行过程中,系统不会再检查这些规则是否满足
为什么会有这种策略?根据一位核心开发人员在Issue中所写,
requiredDuringSchedulingIgnoredDuringExecution的存在只是为requiredDuringSchedulingRequiredDuringExecution的开发争取时间。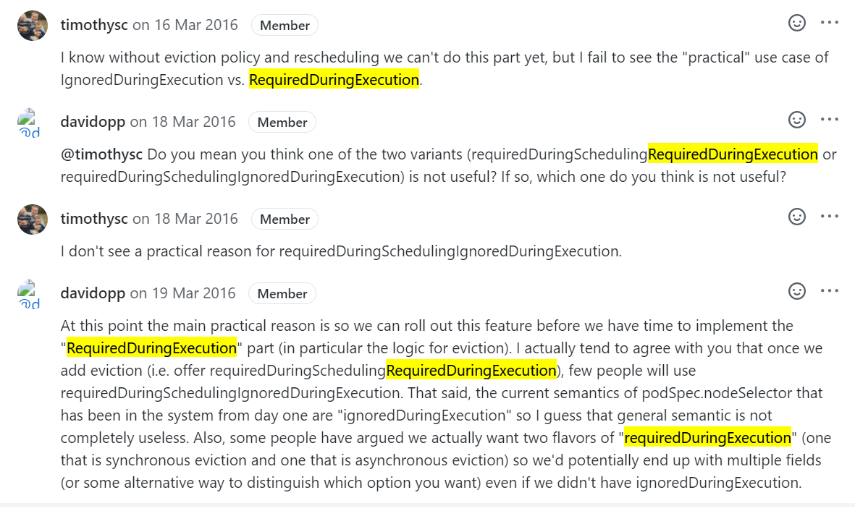
requiredDuringSchedulingRequiredDuringExecution的开发似乎非常困难,这么多年了还没做好
软策略:
preferredDuringSchedulingIgnoredDuringExecution在调度期间尽量满足规则,如果不能满足规则,Pod也有可能被调度到对应的主机上
在之后的运行过程中,系统不会再检查这些规则是否满足
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template: #Pod模板
metadata:
...
spec:
affinity:
nodeAffinity: #Node亲和性
requiredDuringSchedulingRequiredDuringExecution:
... #运行过程中生效的硬策略(计划中,未实现)
requiredDuringSchedulingIgnoredDuringExecution:
... #运行过程中不生效的硬策略
preferredDuringSchedulingIgnoredDuringExecution:
... #软策略
podAffinity: #Pod亲和性
requiredDuringSchedulingRequiredDuringExecution:
... #运行过程中生效的硬策略(计划中,未实现)
requiredDuringSchedulingIgnoredDuringExecution:
... #运行过程中不生效的硬策略
preferredDuringSchedulingIgnoredDuringExecution:
... #软策略
podAntiAffinity: #Pod反亲和性
requiredDuringSchedulingRequiredDuringExecution:
... #运行过程中生效的硬策略(计划中,未实现)
requiredDuringSchedulingIgnoredDuringExecution:
... #运行过程中不生效的硬策略
preferredDuringSchedulingIgnoredDuringExecution:
... #软策略
containers:
...
...
这命名不觉得有点反人类吗?有点无语......
预选策略/硬策略 详解
预选就是一系列逻辑表达式进行与运算,若结果为真,则选为候选节点。
对于KK个预选策略Fk(⋅)(1≤k≤K)Fk(⋅)(1≤k≤K)和系统内的全部节点集合N0N0,候选节点为符合预选策略的节点集合N1={n∈N0∣⋀k=1k≤KFk(n)}N1={n∈N0∣⋀k=1k≤KFk(n)}。
预选策略的种类:
MatchNodeSelector(即上文中的
nodeSelector调度):看节点标签能否适配Pod定义的nodeSelectorGeneralPred HostName:如果Pod定义
hostname属性,会检查节点是否匹配pod.spec.hostnamePodFitsHostPorts:根据
pod.spec.containers.ports.hostPort检查pod要暴露的端口是否被占用。CheckNodeConditionPred:检查节点是否正常
PodFitsResources:判断节点的资源能够满足Pod的
pod.spec.containers.resources定义NoDiskConflict:判断Pod定义的存储是否在node节点上使用。(默认没有启用)
PodToleratesNodeTaints:检查pod上Tolerates的能否容忍污点(
pod.spec.tolerations,下文介绍)CheckNodeLabelPresence:检查节点上的标志是否存在 (默认没有启动)
CheckServiceAffinity:根据Pod所属的
service。将相同service上的Pod尽量放到同一个节点(默认没有启动)CheckVolumeBinding:检查是否可以绑定挂载点(默认没有启动)
NoVolumeZoneConflict:检查是挂载区域冲突(默认没有启动)
CheckNodeMemoryPressure:检查内存是否存在压力
CheckNodeDiskPressure:检查磁盘IO压力是否过大
CheckNodePIDPressure:检查pid资源是否过大
优选策略/软策略 详解
优选策略由一系列带权重的逻辑表达式构成,其权重值的范围是1-100,若逻辑为真则加分,否则不加分,最后选出分数最高的节点。
若有LL个由逻辑表达式Gl(⋅)Gl(⋅)和权重wl(1≤wl≤100)wl(1≤wl≤100)组成的优选策略Hl(n)Hl(n):
Hl(n)={wl(Gl(n))0(¬Gl(n))Hl(n)={wl0(Gl(n))(¬Gl(n))
1≤l≤L1≤l≤L
则预选结果N1N1中的每个节点都会有一个得分S(n)=∑l=1l≤LHl(n)(n∈N1)S(n)=∑l=1l≤LHl(n)(n∈N1)。
则优选结果为得分最高的节点集合N2={n∈N1∣S(n)=max({S(n)∣n∈N1})}N2={n∈N1∣S(n)=max({S(n)∣n∈N1})}。
优选策略的种类:
node_label:根据节点标签得分,存在标签既得分,没有标签没得分。标签越多 得分越高。
least_requested:选择消耗最小的节点(根据空闲比率评估 cpu(总容量-sum(已使用)*10/总容量) )
balanced_resource_allocation:从节点列表中选出各项资源使用率最均衡的节点(CPU和内存)
node_prefer_avoid_pods:节点倾向
taint_toleration:将pod对象的
spec.toleration与节点的taints列表项进行匹配度检查,匹配的条目越多,得分越低(后文介绍)。selector_spreading:与services上其他pod尽量不在同一个节点上,节点上通一个service的pod越少得分越高。
interpod_affinity:遍历node上的亲和性条目,匹配项越多的得分越高
most_requested:选择消耗最大的节点上(尽量将一个节点上的资源用完)
image_locality:节点上有所需要的镜像既得分,所需镜像越多得分越高。(根据已有镜像体积大小之和)
优选策略的写法
如上所述,优选策略是带权重的逻辑表达式,每个表达式在定义中都由权重weight和逻辑表达式preference两部分构成,例如:
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template: #Pod模板
metadata:
...
spec:
affinity:
nodeAffinity: #Node亲和性
preferredDuringSchedulingIgnoredDuringExecution: #软策略
- weight: 11
perference:
...
- weight: 22
perference:
...
...
podAffinity: #Pod亲和性
preferredDuringSchedulingIgnoredDuringExecution: #软策略
- weight: 33
perference:
...
- weight: 44
perference:
...
...
podAntiAffinity: #Pod反亲和性
preferredDuringSchedulingIgnoredDuringExecution: #软策略
- weight: 55
perference:
...
- weight: 66
perference:
...
...
containers:
...
...
亲和性调度匹配规则
Node亲和性nodeAffinity
Node亲和性用于指定Pod应该部署在满足某条件的节点上。
常用的nodeAffinity:nodeSelectorTerms和matchExpressions - 根据Label选Node
如果你同时指定了
nodeSelector和nodeAffinity,两者必须都要满足,才能将Pod调度到候选节点上。如果你指定了多个与
nodeAffinity类型关联的nodeSelectorTerms,则如果其中一个nodeSelectorTerms满足的话,Pod将可以调度到节点上。如果你指定了多个与
nodeSelectorTerms关联的matchExpressions,则只有当所有matchExpressions满足的话,Pod才会可以调度到节点上。
nodeSelectorTerms由一系列matchExpressions组成,每个matchExpressions由要匹配的Label名key、匹配操作operator和要匹配的值values三个部分组成。例如:
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template: #Pod模板
metadata:
...
spec:
affinity:
nodeAffinity: #Node亲和性
requiredDuringSchedulingIgnoredDuringExecution: #运行过程中不生效的硬策略
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- node01
- node02
- node03
- key: disktype
operator: In
values:
- ssd
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 11
preference:
- matchExpressions:
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
- weight: 22
preference:
- matchExpressions:
- key: netspeed
operator: Gt
values:
- 1000
containers:
...
...
表示匹配条件为:
硬策略:“
kubernetes.io/hostname标签值不是node01、node02或node03”且“disktype标签值为ssd软策略:
“
beta.kubernetes.io/arch的值为amd64”值11分“
netspeed的值大于1000”值22分
现在Kubernetes提供的操作符有下面的几种:
In:label 的值在某个列表中NotIn:label 的值不在某个列表中Gt:label 的值大于某个值Lt:label 的值小于某个值Exists:某个 label 存在DoesNotExist:某个 label 不存在
Pod亲和性podAffinity和Pod反亲和性podAntiAffinity
Pod间亲和与反亲和使你可以基于已经在节点上运行的Pod的标签来约束Pod可以调度到的节点,而不是基于节点上的标签。规则的格式为“如果 X 节点上已经运行了一个或多个 满足规则 Y 的pod,则这个 pod 应该(或者在非亲和的情况下不应该)运行在 X 节点”。Y 表示一个具有可选的关联命令空间列表的 LabelSelector。
Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度。我们不建议在超过数百个节点的集群中使用它们。
podAffinity和podAntiAffinity定义格式完全相同,但互为反义词:
podAffinity表示这个Pod应该和某个Pod部署在一起podAntiAffinity表示这个Pod不应该和某个Pod部署在一起podAffinity软策略将表示这个Pod应该和得分最高的Pod部署在一起podAntiAffinity软策略将表示这个Pod不应该和得分最高的Pod部署在一起
重要知识:topologyKey
pod亲和性调度需要各个相关的pod对象运行于"同一位置", 而反亲和性调度则要求他们不能运行于“同一位置”。这里指定 “同一位置” 是通过 topologyKey 来定义的:topologyKey 对应的值是 node 上的一个标签键,对应标签值相同的所有节点都被视为“同一位置”。
比如某些节点上有zone=A标签,还有一些节点有zone=B标签,pod affinity topologyKey定义为zone,那么调度pod的时候,所有zone=A的node就被视为为“同一位置”,zone=B的node也被视为“同一位置”,而zone=A的node和zone=B的node被视为处在不同的位置。
K8S节点自带标签kubernetes.io/hostname是最常用的topologyKey,它使得Pod不会调度到同一个node上。
常用的podAffinity和podAntiAffinity:labelSelector
podAffinity和podAntiAffinity中labelSelector的语法与nodeAffinity中的nodeSelectorTerms大致相同,不同的是:
典型案例
在三节点集群中,一个 web 应用程序具有内存缓存,例如 redis。我们希望 web 服务器尽可能与缓存放置在同一位置。
例如有三个Redis缓存,我们希望它们两两之间不要部署在一起,那就给打个标签并且在podAntiAffinity里面写上这个标签:
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
然后web服务中就将这个store标签放在podAffinity里面从而使得web服务和Redis缓存部署在一起;并且同理用podAntiAffinity使得web服务不会两两部署在一起:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine