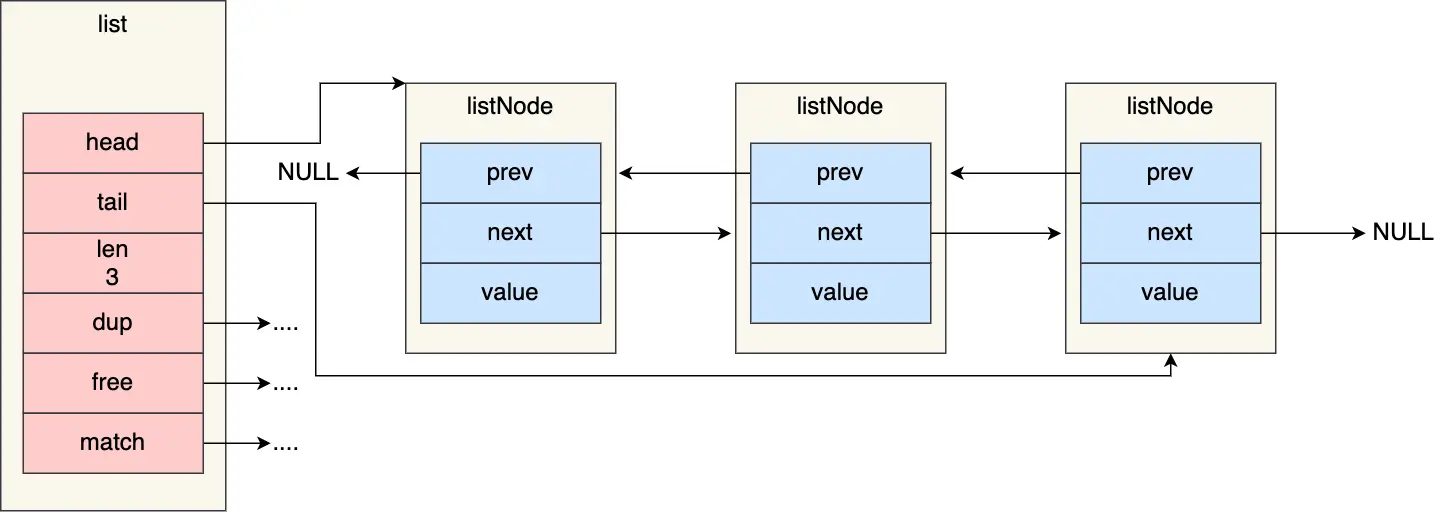
链表
typedef struct listNode {
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
} listNode;
Redis在 listNode 结构体基础上又封装了 list 这个数据结构。list 结构为链表提供了链表头指针 head、链表尾节点 tail、链表节点数量 len、以及可以自定义实现的 dup、free、match 函数。
typedef struct list {
//链表头节点
listNode *head;
//链表尾节点
listNode *tail;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值比较函数
int (*match)(void *ptr, void *key);
//链表节点数量
unsigned long len;
} list;
Redis 的链表实现优点如下:
- listNode 链表节点的结构里带有 prev 和 next 指针,获取某个节点的前置节点或后置节点的时间复杂度只需O(1),而且这两个指针都可以指向 NULL,所以链表是无环链表;
- list 结构因为提供了表头指针 head 和表尾节点 tail,所以获取链表的表头节点和表尾节点的时间复杂度只需O(1);
- list 结构因为提供了链表节点数量 len,所以获取链表中的节点数量的时间复杂度只需O(1);
- listNode 链表节使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此链表节点可以保存各种不同类型的值;
链表的缺陷也是有的:
- 链表每个节点之间的内存都是不连续的,意味着无法很好利用 CPU 缓存。能很好利用 CPU 缓存的数据结构就是数组,因为数组的内存是连续的,这样就可以充分利用 CPU 缓存来加速访问。
- 还有一点,保存一个链表节点的值都需要一个链表节点结构头的分配,内存开销较大。
因此,Redis 3.0 的 List 对象在数据量比较少的情况下,会采用「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构。
不过,压缩列表存在性能问题(具体什么问题,下面会说),所以 Redis 在 3.2 版本设计了新的数据结构 quicklist,并将 List 对象的底层数据结构改由 quicklist 实现。
然后在 Redis 5.0 设计了新的数据结构 listpack,沿用了压缩列表紧凑型的内存布局,最终在最新的 Redis 版本,将 Hash 对象和 Zset 对象的底层数据结构实现之一的压缩列表,替换成由 listpack 实现。
压缩列表
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。缺陷也是有的:
- 不能保存过多的元素,否则查询效率就会降低;
- 新增或修改某个元素时,压缩列表占用的内存空间需要重新分配,甚至可能引发连锁更新的问题。
因此,Redis 对象(List 对象、Hash 对象、Zset 对象)包含的元素数量较少,或者元素值不大的情况才会使用压缩列表作为底层数据结构。
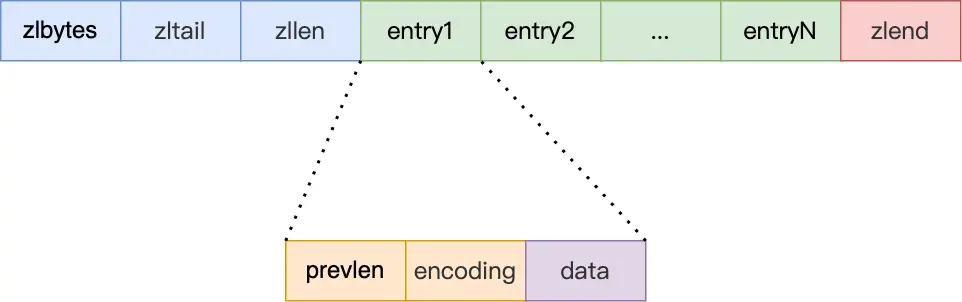
- zlbytes,记录整个压缩列表占用对内存字节数;
- zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
- zllen,记录压缩列表包含的节点数量;
- zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段(zllen)的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素。
节点包含:
- prevlen,记录了「前一个节点」的长度,目的是为了实现从后向前遍历;
- encoding,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。
- data,记录了当前节点的实际数据,类型和长度都由
encoding决定;
当我们往压缩列表中插入数据时,压缩列表就会根据数据类型是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
分别说下,prevlen 和 encoding 是如何根据数据的大小和类型来进行不同的空间大小分配。
压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」,而且 prevlen 属性的空间大小跟前一个节点长度值有关,比如:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
encoding 属性的空间大小跟数据是字符串还是整数,以及字符串的长度有关,如下图(下图中的 content 表示的是实际数据,即本文的 data 字段):
- 如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码,也就是 encoding 长度为 1 字节。通过 encoding 确认了整数类型,就可以确认整数数据的实际大小了,比如如果 encoding 编码确认了数据是 int16 整数,那么 data 的长度就是 int16 的大小。
- 如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节/2字节/5字节的空间进行编码,encoding 编码的前两个 bit 表示数据的类型,后续的其他 bit 标识字符串数据的实际长度,即 data 的长度。
压缩列表的连锁更新问题
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
前面提到,压缩列表节点的 prevlen 属性会根据前一个节点的长度进行不同的空间大小分配:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
现在假设一个压缩列表中有多个连续的、长度在 250~253 之间的节点,如下图:

因为这些节点长度值小于 254 字节,所以 prevlen 属性需要用 1 字节的空间来保存这个长度值。
这时,如果将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,即新节点将成为 e1 的前置节点,如下图:

因为 e1 节点的 prevlen 属性只有 1 个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作,并将 e1 节点的 prevlen 属性从原来的 1 字节大小扩展为 5 字节大小。
多米诺牌的效应就此开始。

e1 原本的长度在 250~253 之间,因为刚才的扩展空间,此时 e1 的长度就大于等于 254 了,因此原本 e2 保存 e1 的 prevlen 属性也必须从 1 字节扩展至 5 字节大小。
正如扩展 e1 引发了对 e2 扩展一样,扩展 e2 也会引发对 e3 的扩展,而扩展 e3 又会引发对 e4 的扩展… 一直持续到结尾。
这种在特殊情况下产生的连续多次空间扩展操作就叫做「连锁更新」
空间扩展操作也就是重新分配内存,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。
所以说,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题。
因此,压缩列表只会用于保存的节点数量不多的场景
哈希表
哈希表是一种保存键值对(key-value)的数据结构。
哈希表中的每一个 key 都是独一无二的,程序可以根据 key 查找到与之关联的 value,或者通过 key 来更新 value,又或者根据 key 来删除整个 key-value等等。
在讲压缩列表的时候,提到过 Redis 的 Hash 对象的底层实现之一是压缩列表(最新 Redis 代码已将压缩列表替换成 listpack)。Hash 对象的另外一个底层实现就是哈希表。
哈希表优点在于,它能以 O(1) 的复杂度快速查询数据。怎么做到的呢?将 key 通过 Hash 函数的计算,就能定位数据在表中的位置,因为哈希表实际上是数组,所以可以通过索引值快速查询到数据。
但是存在的风险也是有,在哈希表大小固定的情况下,随着数据不断增多,那么哈希冲突的可能性也会越高。
解决哈希冲突的方式,有很多种。
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht;
Redis 采用了「链式哈希」来解决哈希冲突,在不扩容哈希表的前提下,将具有相同哈希值的数据串起来,形成链接起,以便这些数据在表中仍然可以被查询到。
dictEntry 结构里不仅包含指向键和值的指针,还包含了指向下一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对链接起来,以此来解决哈希冲突的问题,这就是链式哈希。
另外,这里还跟你提一下,dictEntry 结构里键值对中的值是一个「联合体 v」定义的,因此,键值对中的值可以是一个指向实际值的指针,或者是一个无符号的 64 位整数或有符号的 64 位整数或double 类的值。这么做的好处是可以节省内存空间,因为当「值」是整数或浮点数时,就可以将值的数据内嵌在 dictEntry 结构里,无需再用一个指针指向实际的值,从而节省了内存空间。
typedef struct dictEntry {
//键值对中的键
void *key;
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
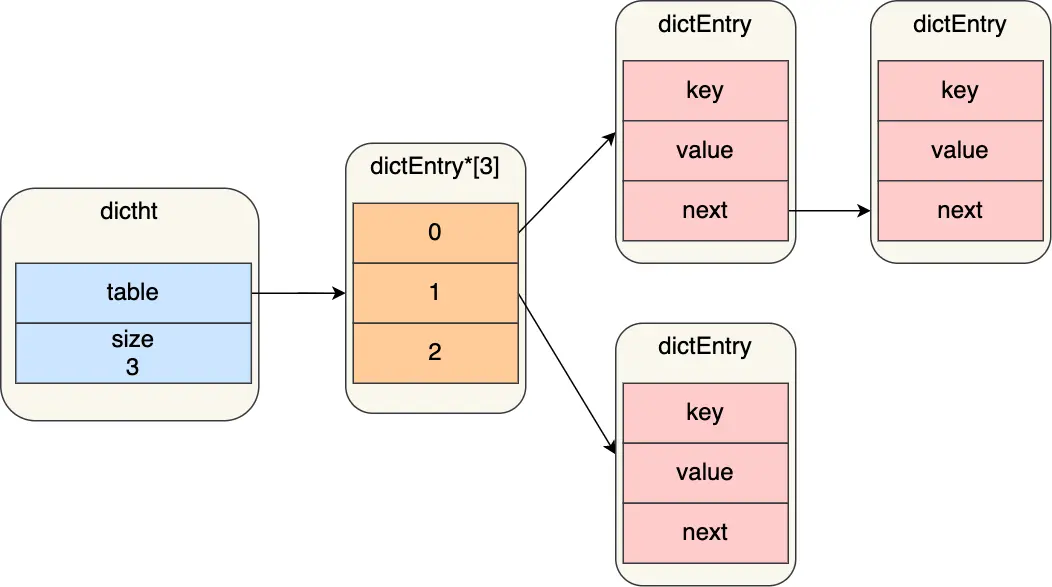
哈希冲突
哈希表实际上是一个数组,数组里多每一个元素就是一个哈希桶。
当一个键值对的键经过 Hash 函数计算后得到哈希值,再将(哈希值 % 哈希表大小)取模计算,得到的结果值就是该 key-value 对应的数组元素位置,也就是第几个哈希桶。那么就可能会发生哈希冲突
Redis 采用了「链式哈希」的方法来解决哈希冲突。**被分配到同一个哈希桶上的多个节点可以用这个单项链表连接起来。**局限性也很明显,随着链表长度的增加,在查询这一位置上的数据的耗时就会增加,毕竟链表的查询的时间复杂度是 O(n)。要想解决这一问题,就需要进行 rehash,也就是对哈希表的大小进行扩展。
rehash
在实际使用哈希表时,Redis 定义一个 dict 结构体,这个结构体里定义了两个哈希表(ht[2]),因为rehash需要用到两个
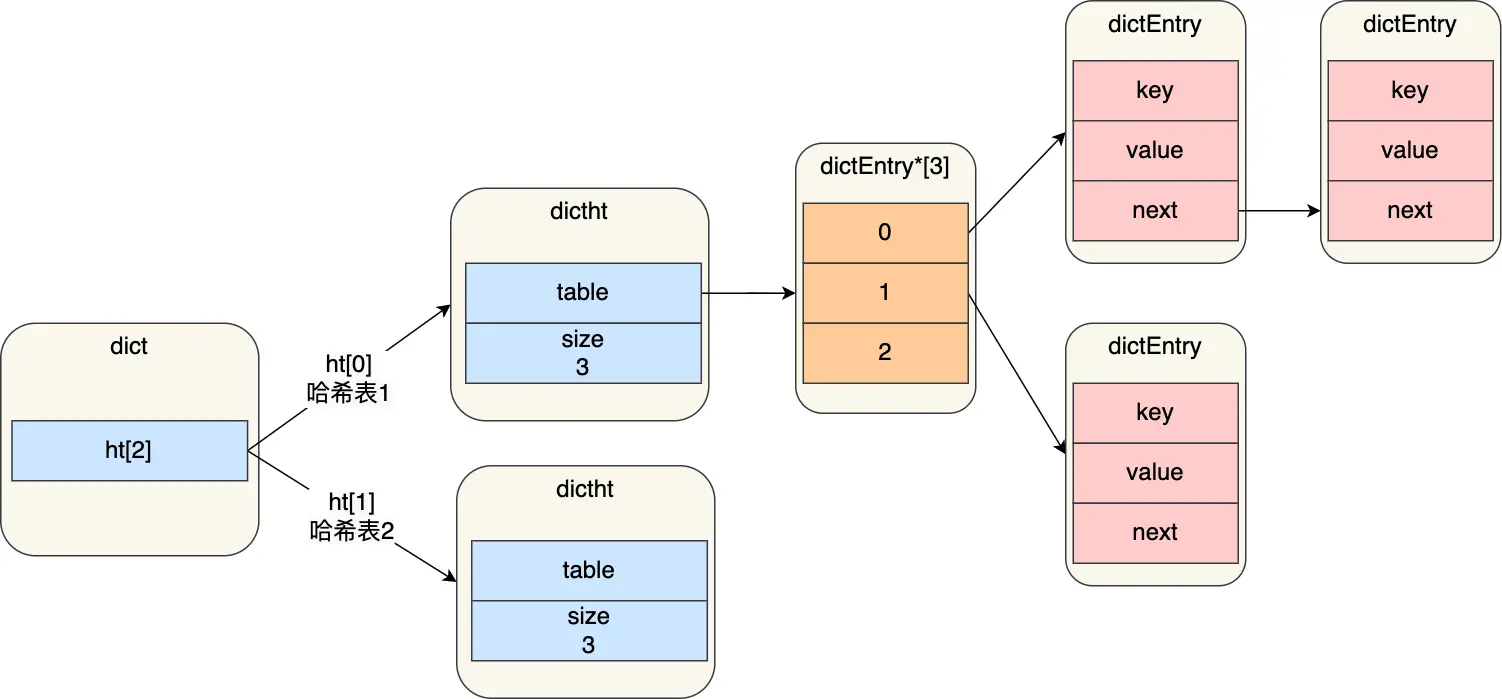
typedef struct dict {
…
//两个Hash表,交替使用,用于rehash操作
dictht ht[2];
…
} dict;

在正常服务请求阶段,插入的数据,都会写入到「哈希表 1」,此时的「哈希表 2 」 并没有被分配空间。
随着数据逐步增多,触发了 rehash 操作,这个过程分为三步:
- 给「哈希表 2」 分配空间,一般会比「哈希表 1」 大一倍(两倍的意思);
- 将「哈希表 1 」的数据迁移到「哈希表 2」 中;
- 迁移完成后,「哈希表 1 」的空间会被释放,并把「哈希表 2」 设置为「哈希表 1」,然后在「哈希表 2」 新创建一个空白的哈希表,为下次 rehash 做准备。
如果「哈希表 1 」的数据量非常大,那么在迁移至「哈希表 2 」的时候,因为会涉及大量的数据拷贝,此时可能会对 Redis 造成阻塞,无法服务其他请求。
渐进式 rehash
为了避免 rehash 在数据迁移过程中,因拷贝数据的耗时,影响 Redis 性能的情况,所以 Redis 采用了渐进式 rehash,也就是将数据的迁移的工作不再是一次性迁移完成,而是分多次迁移。
渐进式 rehash 步骤如下:
- 给「哈希表 2」 分配空间;
- 在 rehash 进行期间,每次哈希表元素进行新增、删除、查找或者更新操作时,Redis 除了会执行对应的操作之外,还会顺序将「哈希表 1 」中索引位置上的所有 key-value 迁移到「哈希表 2」 上;
- 随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间点会把「哈希表 1 」的所有 key-value 迁移到「哈希表 2」,从而完成 rehash 操作。
这样就巧妙地把一次性大量数据迁移工作的开销,分摊到了多次处理请求的过程中,避免了一次性 rehash 的耗时操作。
在进行渐进式 rehash 的过程中,会有两个哈希表,所以在渐进式 rehash 进行期间,哈希表元素的删除、查找、更新等操作都会在这两个哈希表进行。
比如,查找一个 key 的值的话,先会在「哈希表 1」 里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到。
另外,在渐进式 rehash 进行期间,新增一个 key-value 时,会被保存到「哈希表 2 」里面,而「哈希表 1」 则不再进行任何添加操作,这样保证了「哈希表 1 」的 key-value 数量只会减少,随着 rehash 操作的完成,最终「哈希表 1 」就会变成空表。
rehash 触发条件
介绍了 rehash 那么多,还没说什么时情况下会触发 rehash 操作呢?
rehash 的触发条件跟**负载因子(load factor)**有关系。
负载因子可以通过下面这个公式计算:

触发 rehash 操作的条件,主要有两个:
- 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
- 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。