消息队列是什么
消息队列,顾名思义就是传递消息的队列,有着先入先出的特性,既然是队列,自然遵循先入先出的原则,同时,消息队列具备可靠性、高性能等特点。 消息队列是大型分布式系统不可缺少的中间件,一般用于异步流程、消息分发、流量削锋等问题,可以通过消息队列实现高性能、高可用、高扩展的架构。

消息队列抽象出来就是一个数组,核心能力无非就是收消息、存消息、消费消息,底层是个B+树结构,一般也不会出太多问题
消息队列有很多:AcitiveMQ、RabbitMQ、ZeroMQ、Kafka、RoketMQ等等
消息队列解决什么问题
消息队列本质是解决消息传递的问题,其它场景都是扩展出来的。
1.接收方处理不过来的时候,比如接收方每秒只能处理1000条消息,但是你因为搞活动,瞬间1s有10000条,这时候打过去接收方也扛不住啊,通过消息队列可以让接收方按自己的能力来协调,把消息压力摊平,这就是削峰
2.发送一个通知到短信服务,让短信服务发一条短信给客户,这时候如果要等待短信发完,发送方就会慢,不需要关注结果,就可以实现解耦
3.相同消息要发给10个服务,如果直接发,要写10次发送的代码,新增加1个服务来接收的话,发布者还需要改代码发布。所以有不少场景是没法或者不太适合直接发送的,那怎么办呢?后端领域有一句名言,没什么事是引入一个中间层解决不了的,如果有,那就引入两个。这里就是引入消息队列作为中间层,来解决某些场景下消息传递的问题,这就是消息队列的意义
应用场景:解耦
解耦就是解除耦合,比如两个服务SvrA如果需要等待SvrB的返回,关注返回的结果和数据,或者就是单纯要B服务处理了,A才能给更前端回包,这就是耦合。 比如发送短信场景,假设服务SvrA发送消息给SvrB,SvrB发送短信给客户,很多时候业务是允许SvTA不需要得到SvrB发送完成的回应,只需要消息发送到SVrB就行了,这种情况下,如果还让SvrA等待SvrB的返回,显然会导致性能变低,同时还要去关注SvrB的运行结果。 所以,如果业务上可以去除这种依赖,那么就会获得性能、可靠性等的提升。

应用场景:异步
如果一个接口,处理时间很长,而且不能通过水平扩容来解决,就需要异步,那么,什么情况下不能通过水平扩容解决呢?
有很多,比如视频处理,涉及到视频下载,那受限于网络带宽等因素,扩容无用;比如区块链这种共识场景,只有单机才能出块,扩容也没有用;还有更常见的,比如一个业务流程,过了10多个微服务,单个也许不长,加起来就很难接受。
以上的情况下,用户很难通过同步接口长时间等待结果,那就应该做成异步,先扔进消息队列,后续再进行消费,和解耦一样可以收获更高的性能,以及获得更好的可靠性。
异步和解耦最大的区别在于,解耦是业务上本身就不需要依赖,异步是可能还是需要关注结果,但是不一定干等,可以回头再找。
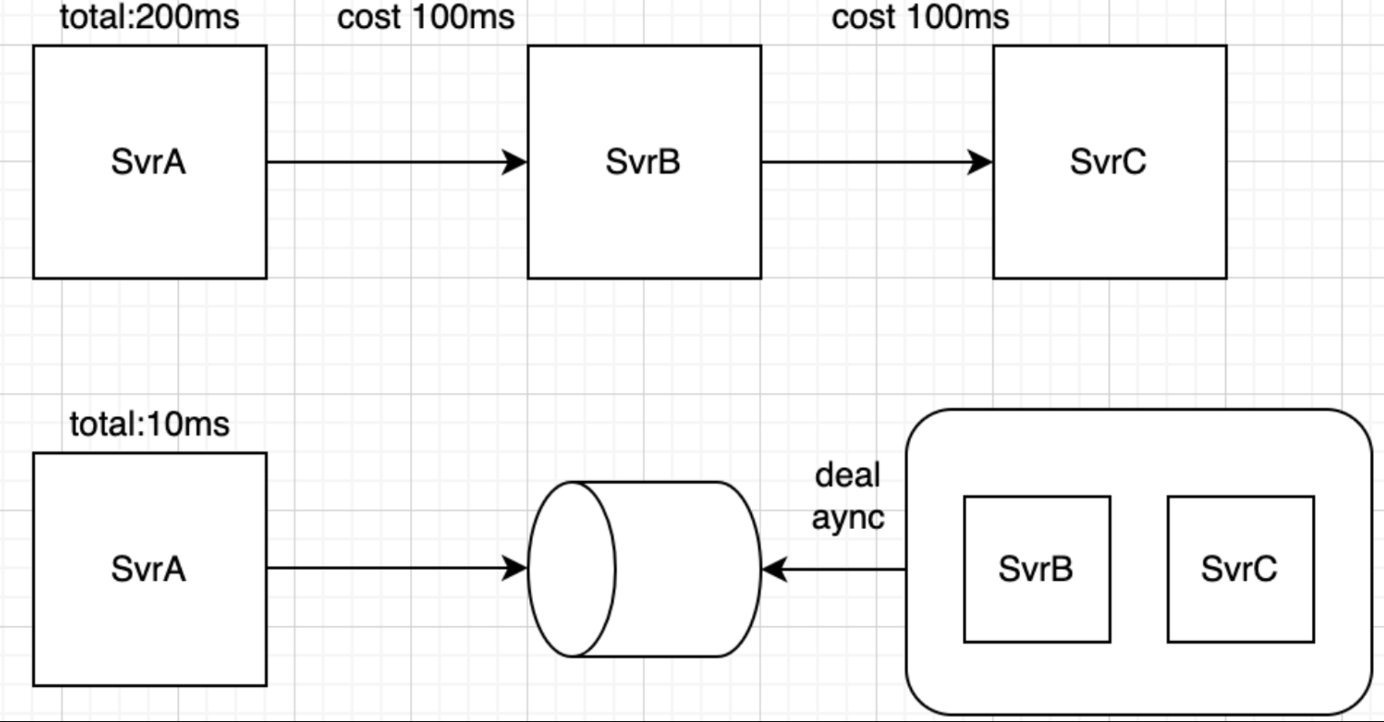
应用场景:消息分发
假设一个核心服务A,是用来发布某种信号的,发布之后,需要通知到下游服务B、C,这种模式在只有B、C两兄弟的时候,没啥问题。 但随着业务需要,可能会有D、E、F等更多的打工人出现,这时候A服务就需要更改代码,将消息也传递给这些新入的兄弟,每次增加打工人,就需要更改一次代码。
而引入消息队列就可以决绝这个问题,实现能力复用

应用场景:削峰
比如秒杀场景,把扣库存的操作均匀化处理,防止瞬时流量打崩mysql
消息队列选型对比

选型的时候,我们需要根据业务场景,结合上述特性来进行选型。 比如你要支持天猫双十一类超大型的秒杀活动,这种一锤子买卖,那管理界面、消息回湖啥的不重要。我们需要看什么?看吞吐量!所以优先选Kafka和RocketMQ这种更高吞吐的。
比如做一个公司的中台,对外提供能力,那可能会有很多主题接入,这时候主题个数又是很重要的考量,像Kafka这样百级的,就不太符合要求,可以根据情况考虑千级的RocketMQ,甚至百万级的RabbitMQ。
又比如是一个金融类业务,那么重点考虑的就是稳定性、安全性,分布式部署的Kafka和Rocket就更有优势。
又比如你的延时场景特别多,那么是否支持延时消息,也要作为考量标准,这种情况下Kafka实现起来麻烦点。
特别说一下时效性,RabbitMQ以微秒的时效作为招牌,但实际上毫秒和微秒,在绝大多数情况下,都没有感知的区别,加上网络带来的波动,这一点在生产过程中,反而不会作为重要的考量。
其它的特性,如消息确认、消息回溯也经常作为考量的场景