Abstract
满足对大尺寸图像(2K-8K)超分辨率(SR)快速增长需求的方法主要有两个独立的方向:
1)通过内容感知路由加速现有网络,
2)通过令牌混合器改进设计更好的超分辨率网络。
尽管直接,但它们会遇到不可避免的缺陷(例如,不灵活的路由或非判别性处理),限制了质量复杂度权衡的进一步提升。
为了消除这些缺点,我们将这些方案整合起来,提出了一个内容感知混合器(CAMixer),它为简单上下文分配卷积,并为稀疏纹理使用额外的可变形窗口注意力。具体而言,CAMixer使用可学习预测器生成多个引导样本,包括用于窗口扭曲偏移、用于分类窗口和赋予卷积动态属性以调节注意力自适应地包含更多有用纹理并改善卷积表示能能力等掩码。我们还引入全局分类损失以提高预测器准确性。通过简单堆叠CAMixers, 我们获得了在大尺寸图像SR、轻量级SR和全向图像SR上实现优越性能的CAMixerSR。
Introduction
最近对神经网络的研究显著提高了图像超分辨率(SR)质量[22, 34, 43]。然而,现有方法在生成视觉上令人愉悦的高分辨率(HR)图像方面取得了进展,但在实际应用中遭受了密集的计算压力,尤其是针对2K-8K目标。为减轻这种开销,许多加速框架[4, 19]和轻量级网络[14, 32]被引入以用于实际超分辨率应用。然而,这些方法完全独立且缺乏合作。
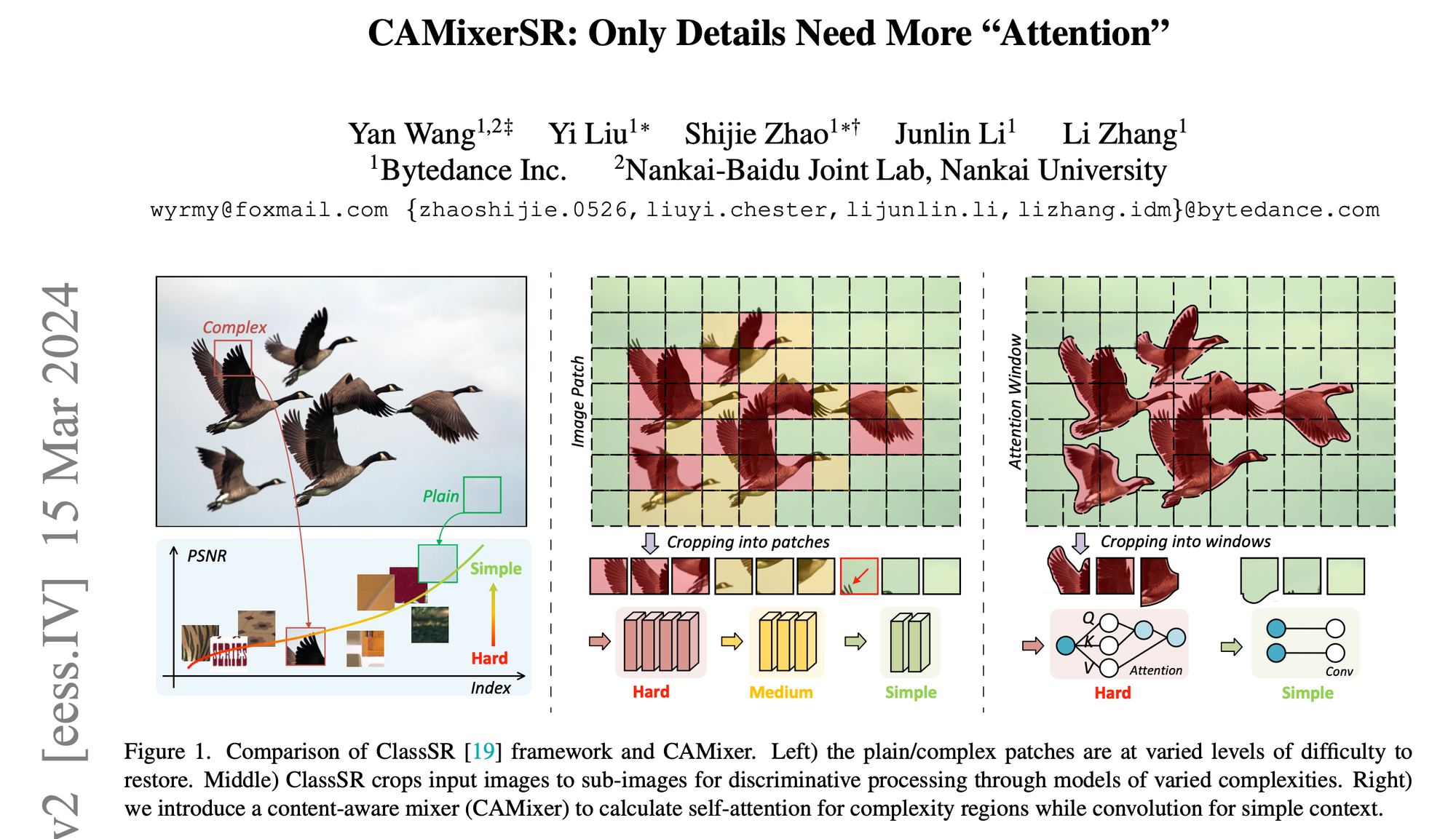
第一种策略——加速框架[11, 19, 39]基于以下观察:不同图像区域需要不同的网络复杂性,从内容感知路由各种模型来解决问题。正如图1中间图片所示,它们将大输入图像分解成固定块,并通过额外的分类网络将补丁分配给网络。ARM [4]进一步发展了这一策略,引入了基于LUT的分类器和参数共享设计以提高效率。尽管这些策略对所有神经网络都是通用的,但仍然存在两个不可避免的缺陷。一个是较差的分类和灵活性不足。图1显示了细节很少的窗口被错误地发送到简单模型中。另一个是有限的感知域。如表2所示,将图像裁剪成补丁会限制感知域,从而影响性能。
第二种策略——轻量级模型设计[7, 8, 17, 44]侧重于优化神经操作符(自注意力或卷积)和骨干结构,以在有限层内实现更强大的特征表示能力,即使用更多内部信息来重建图像。例如,NGswin [5]利用N-Gram进行自注意力以减少计算量并扩大感感知域。IMDN [14]引入信息多蒸馏进行高效块设计。 虽然这些轻量级方法在720p/1080p图像上达到了令人印象深刻的效率,但它们很少被用于更大输入(2K-8K)。此外,这些方法忽视了不同内容可以被区别处理的固有特性。
这篇论文首先整合了上述策略,基于得出的观察结果,即不同特征区域需要不同级别的令牌混合器复杂性。如表1所示,简单卷积(Conv)可以在处理简单补丁时与更复杂的卷积+自注意力(SA + Conv)有类似的性能。因此,我们提出了一种内容感知混合器(CAMixer),根据内容路由具有不同复杂度的令牌混合器。正如图1所示,我们的CAMixer对于复杂窗口使用复杂自注意力(SA),对于普通窗口使用简单卷积。此外,为了解决ClassSR的局限性,我们引入了一个更复杂的预测器。该预测器利用多个条件生成额外的有用信息,从而提高CAMixer的分区精度和更好的表示。
通过CAMixer,我们提出了Content-Aware Mixer (CAMixer),它整合了卷积和自注意力,能够通过将简单区域分配给卷积和复杂区域分配给自注意力来自适应地控制推断计算。我们还提出了一个强大的预测器,用于生成偏移、蒙版以及简单的空间/通道关注,从而调节CAMixer以用更少的计算捕捉更长距离的相关性。基于CAMixer,我们构建了CAMixerSR,在轻量级SR、大输入SR和全向图像SR三个具有挑战性的超分辨率任务上展现出最先进的质量-计算权衡。
为了充分检验CAMixer的性能,我们对轻量级SR、大输入(2K-8K)SR和全向图像SR进行了实验。图2说明CAMixerSR在轻量级SR和加速框架方面取得了巨大进展。我们的贡献总结如下:
• 我们提出了一个内容感知混合器(CAMixer),集成卷积和自注意力,可以通过将简单区域分配给卷积和复杂区域分配给自注意力来自适应地控制推理计算。
• 我们提出了一个强大的预测器,用于生成偏移、蒙版以及简单空间/通道关注,从而调节CAMixer以用更少的计算捕捉更长距离相关性。
• 基于CAMixer,我们构建了CAMixerSR,在三个具有挑战性的超分辨率任务上展现出最先进的质量-计算权衡:轻量级SR、大输入SR和全向图像SR。
Related Work
加速SR的框架
随着复杂性不断扩大以获得更好的恢复质量,对于SR模型的实际应用变得更加困难,特别是对于2K-8K SR。最近的研究[4, 19, 39]从不同角度解决了这个问题。他们没有设计轻量级模型,而是使用内容感知路由动态地将裁剪后的补丁发送到具有不同复杂性的模型中。ClassSR [19]利用3类分类器来确定由复杂/中等/简单网络计算出的子图像,这在8K数据集上为RCAN [43]节省了50% 的计算量。PathRestore [39]学会根据上下文选择特征路径以适应FLOP。
轻量级SR
自第一个作品SRCNN [7]在超分辨率任务中使用卷积神经网络(ConvNet)以来,已经提出了许多策略[7, 14, 23, 34]来减减少复杂性以获得更轻量级化。早期的DRCN [16] 和 DRRN [31] 尝试通过使用循环块来减少参数,但遭受了密集的计算。为了缓解这一缺点,IDN [13] 和 IMDN [14] 采用了高效的信息融合结构来减少参数和计算量。后来的ConvNet,例如EFDN [32] 和 RLFN [18] 进一步简化了信息提取过程,并引入重新参数化以实现在移动设备上进行实时推断。随着变压器技术的快速发展,各种强大的令牌混合器(如自注意力[41,42]和大内核卷积[33,45])被引入到轻量级SR中。例如,SwinIR [21] 使用基于窗口的SA,而MAN [33] 则采用大内核卷积,两者都取得了最先进性能。尽管这些神经操作符能够捕捉长距离相关性,但它们需要大量计算。因此,在本本文中将内容感知路由整合到令牌混合器设计中,该设计对具有信息区域使用复杂操作符,并对普通区域使用简单操作符。
Method
Content-Aware Mixing
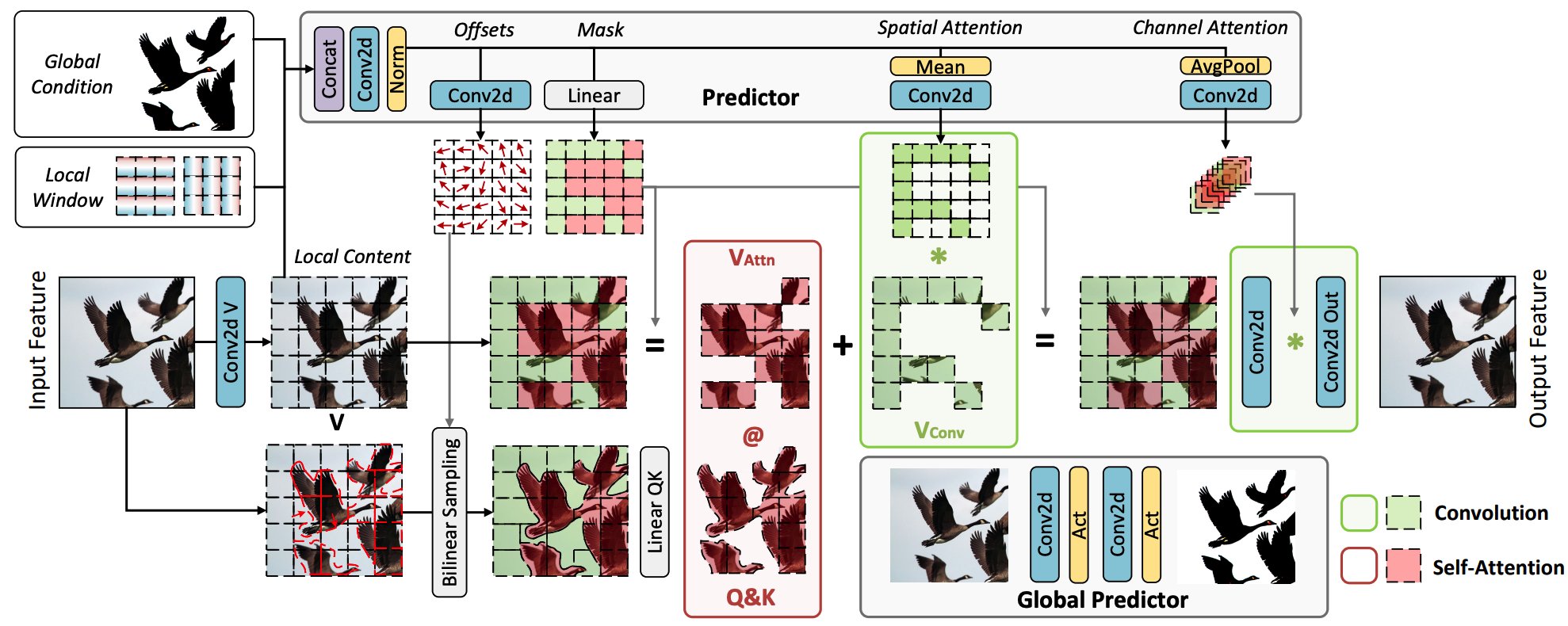
我们提出的CAMixer概述如图3所示。CAMixer由三个主要组件组成:预测模块、注意力分支和卷积分支。给定输入特征X ∈ R^{C×H×W},首先通过逐点卷积投影到值V ∈ R^{C×H×W}
(1) 预测器。
基于局部条件C_l = V,全局条件Cg ∈ R ^{2×H×W}和线性位置编码C_w ∈ R^{2×H×W},预测器首先计算共享的中间特征图F,然后生成偏移映射、混合器掩模和简单的空间/通道注意力
其中∆p是与内容相关的偏移矩阵,用于扭曲具有更复杂结构的窗口。r是一个标量,用于控制偏移范围。\hat{F}是根据注意窗口大小M减少并重新排列的即时特征。m是决定是否通过注意或卷积计算裁剪窗口的掩模。A_s 和 A_c 是增强卷积分支的空间和通道注意力。
(2)注意分支。
为了计算复杂区域的稀疏注意力,我们使用偏移量∆p来调制原始输入X,通过双线性插值ϕ(·)将更多有用的内容包含在选定的窗口中:\tilde{X } = \phi (X ,\Delta p)。
然后我们根据窗口形状M×M重新排列\tilde{X},\mathbf{V} \in \mathbb{R}^{\frac{H W}{M^2} \times M^2 \times C}。在训练阶段,我们应用gumble softmax [15, 29]来计算二进制掩码M = gumble softmax(m),以进行难和简单令牌采样。在推断过程中,通过对掩码m进行降序排序argsort(m),我们得到稀疏注意力前K个相关窗口的索引I_{hard},并得到卷积操作所需的其他\frac{HW}{M^2} − K个窗口的Isimple索引,其中K = \sum{M}。我们将注意力补丁的比率表示为γ = K/\frac{HW}{M^2}.
根据索引,我们通过以下方式分割\hat{X}和V:
获得\hat{X}_{hard} 后,查询\hat{Q}_{hard} 和键\hat{K}_{hard}由线性层生成:
对于Windows V_{simple}的轻操作,我们使用重新排列的A_s来通过逐元素乘法实现简单的注意力。
(3)卷积分支。
我们利用深度可分离卷积和预生成的通道注意力来捕获局部相关性,可以表示为:
最后,CAMixer的输出通过逐点卷积进行投影:
(4)CAMixer。
总的来说,通过控制自注意力比率 γ,我们调整了内容感知混合。当 γ = 1 时,CAMixer 是自注意力和卷积的组合,类似于 ACMix [28]。对于 γ = 0,则 CAMixer是一个纯卷积标记混合器,复杂度低。
对于 γ ∈ (0, 1),CAMixer 学习使用复杂模式处理困难区域,但对于普通区域则使用简单模式的内容感知混合。 复杂性分析。我们在表3中从理论上比较了卷积、基于窗口的自注意力和 CAMixer 的复杂性。具体来说,CAMixer 的 FLOPs 包括三个部分:卷积、注意力和预测器。给定输入 C ×h×w,卷积分支利用深度可分离卷积进行计算成本为 K^2Chw。 对于注意力分支,四次投影操作成本为 2(1 + γ)C^2hw ,而注意力计算成本为 2γM^2Chw,其中 γ = K/( hw/M^2 ) 是硬窗口的比例。对于预测器模块,则添加一系列计算:共享头部 ρC(C + 4)hw ,掩码 Mhw ,偏移量 2ρChw ,空间注意力 ρk^2Chw 和通道注意力 ρC^2 。这里 ρ = \frac{1}{8} 是减少计算的缩减比率。
Network Architecture
最后,我们通过修改SwinIRlight [21] 构建了CAMixerSR。通常,CAMixerSR 由四个组件组成,其中三个来自 SwinIR:浅层特征提取器、深层特征提取器、重构模块和图 3 所示的额外全局预测模块。此外,我们用 CAMixer 替换了基于窗口的自注意力,并减少了块数。
Training loss
我们描述了CAMixerSR的训练目标,包括优化超分辨率框架和预测器。在之前的工作[22, 34]基础上,我们采用主要的ℓ1损失来训练骨干网络。假设输入批次包含N对图像,即\{{I_{i}^{LR}, I^{HR}_i}\}^N_{i=1},则该过程可以表示为:
其中f_{CAMixerSR}(·)是提出的CAMixerSR。为了监督S个CAMixers的预测器,遵循控制SA稀疏性的先前工作[29, 37],我们采用简单但有效的MSE Loss来控制比率γ_i:
其中γref代表参考整体比例,γi表示第 i 个CAMixer的硬令牌比例。为了实现动态比例训练,我们首先使用γref = 0.5对CAMixerSR进行预训练,并在γref ∈ [0, 1]范围内进行微调。总体而言,我们通过简单地结合上述目标来训练CAMixerSR: